围绕Transformer的模型架构是当下大家关注的焦点!阿联酋阿布扎比大学发布了首篇《Transformer医疗影像》综述论文,41页pdf439篇文献全面阐述ansformers在医疗影像中的应用,涵盖了各个方面,从最近提出的架构设计到未解决的问题。具体来说,我们调研了Transformers在医学图像分割、检测、分类、重建、合成、配准、临床报告生成和其他任务中的使用。

在自然语言任务上取得了前所未有的成功之后,Transformers已经成功地应用于计算机视觉问题并取得了SOTA结果,并促使研究人员重新考虑卷积神经网络(CNN)作为模型骨干的优势。利用计算机视觉方面的这些进步,医疗影像领域也见证了人们对能够捕获全局上下文的Transformers 越来越感兴趣,而与CNN相比,Transformers只能捕获局部接收域。受这种转变的启发,在本次综述中,我们试图提供一个全面的回顾Transformers在医疗影像中的应用,涵盖了各个方面,从最近提出的架构设计到未解决的问题。具体来说,我们调研了Transformers在医学图像分割、检测、分类、重建、合成、配准、临床报告生成和其他任务中的使用。特别是,对于每一个应用,我们将提出分类法,识别特定于应用的挑战,并提供解决这些挑战的见解,并强调最近的趋势。此外,我们对该领域目前的整体状态进行了批判性的讨论,包括确定关键挑战、开放的问题,并概述了有前途的未来方向。我们希望这一调研将点燃社区进一步的兴趣,并为研究人员提供最新的参考,有关Transformers模型在医学成像中的应用。最后,为了应对这一领域的快速发展,我们打算定期在https://github.com/fahadshamshad/awesome-transformers-in-medical-imaging上更新相关的最新论文及其开源实现。
引言
卷积神经网络(CNN)[1] -[4]因其能够以数据驱动的方式学习高度复杂的表示形式,对医学成像领域产生了重大影响。自其复兴以来,CNN已经在许多医学成像模式中表现出显著的改进,包括x线摄影[5],内窥镜[6],计算机断层摄影(CT)[7],[8],乳房x线摄影图像(MG)[9],超声图像[10],磁共振成像(MRI)[11],[12],正电子发射断层摄影(PET)[13],等等。CNN中的主力是卷积算子,它在局部进行运算并提供平移等方差。虽然这些特性有助于开发高效和可推广的医疗成像解决方案,但卷积操作中的局部接受域限制了捕获长程像素关系。此外,卷积滤波器在推理时具有不适应给定输入图像内容的固定权值。
与此同时,视觉界也做了大量的研究工作,将注意力机制[14]-[16]整合到CNN架构[17]-[22]中。这些基于注意力的“Transformer”模型已经成为一种有吸引力的解决方案,因为它们能够编码长期依赖关系,并学习高效的特征表示[23]。最近的研究表明,这些Transformer模块可以通过对一系列图像补丁进行操作,完全取代深度神经网络中的标准卷积,从而产生Vision Transformer (ViTs)[22]。自诞生以来,ViT模型已被证明在许多视觉任务中推动了最先进的技术,包括图像分类[22]、对象检测[24]、语义分割[25]、图像着色[26]、低级视觉[27]和视频理解[28]等等。此外,最近的研究表明,ViTs的预测误差比CNN[29] -[32]更符合人类的预测误差。ViT的这些令人满意的特性引起了医学界的极大兴趣,将其用于医学成像应用,从而减轻CNN[33]固有的归纳偏差。
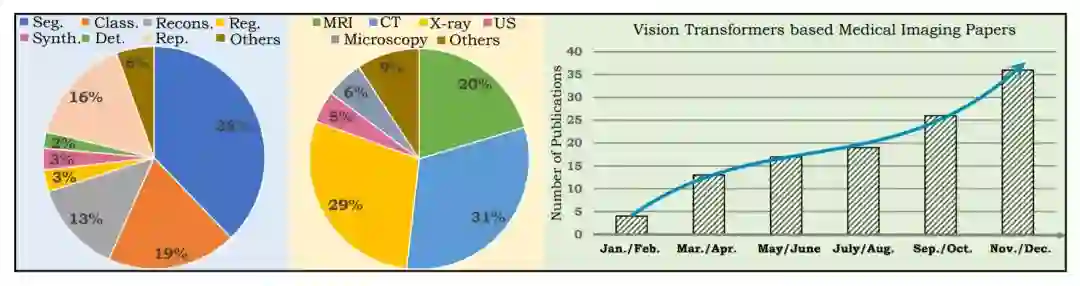
(左)饼状图显示了根据医学成像问题设置和数据模态所包括的调研论文的统计数据。最右边的数字显示了近期文献(2021年)的持续增长。Seg:分割,Class:分类,Recons:重建,Reg:配准,Synth:合成,Det:检测,Rep:报告生成,US:超声
最近,医学影像社区见证了基于Transformer的技术数量呈指数级增长,特别是在vit出现之后(见图1)。这个主题现在在著名的医学影像会议和期刊上占据主导地位,而且由于论文的迅速涌入,要跟上最近的进展越来越困难。因此,对现有有关工作的调研是及时的,以便全面介绍这一新兴领域的新方法。为此,我们提供了Transformer模型在医学成像中的应用的整体概述。我们希望这项工作可以为研究人员进一步探索这一领域提供一个路线图。我们的主要贡献包括:
-
这是第一篇全面涵盖transformer在医学成像领域的应用的综述论文,从而在这个快速发展的领域弥合了视觉和医学成像社区之间的差距。具体来说,我们提出了一个超过125篇相关论文的全面概述,以涵盖最近的进展。
-
如图2所示,我们根据论文在医学成像中的应用对其进行了分类,从而对该领域进行了详细的覆盖。对于这些应用,我们开发了一种分类法,突出了特定于任务的挑战,并根据文献综述提供了解决这些挑战的见解。
-
最后,我们对该领域的整体现状进行了批判性的讨论,包括确定关键挑战,突出开放的问题,并概述了有前景的未来方向。
-
尽管本次调研的主要焦点是Vision Transformer,但我们也是自最初的Transformer(大约五年前)诞生以来,首次在临床报告生成任务中广泛覆盖其语言建模功能(见第9节)。
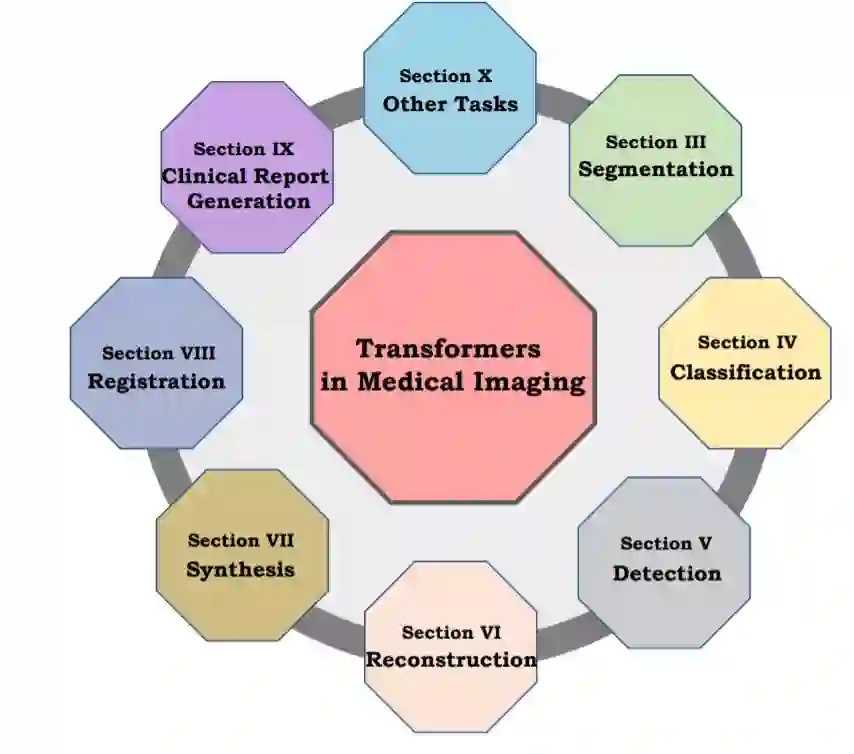
本综述涵盖了Transformer在医学成像中的多种应用领域
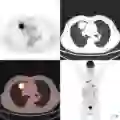
ViT在各种医学成像问题中的应用,以及基于CNN的基线方法。与基于CNN的方法相比,基于ViT的方法具有更好的性能,这是因为它们能够建模全局上下文。图来源:(a) [34], (b) [35], (c) [36], (d) [37], (e) [38], [39] (f)。
医学图像分割
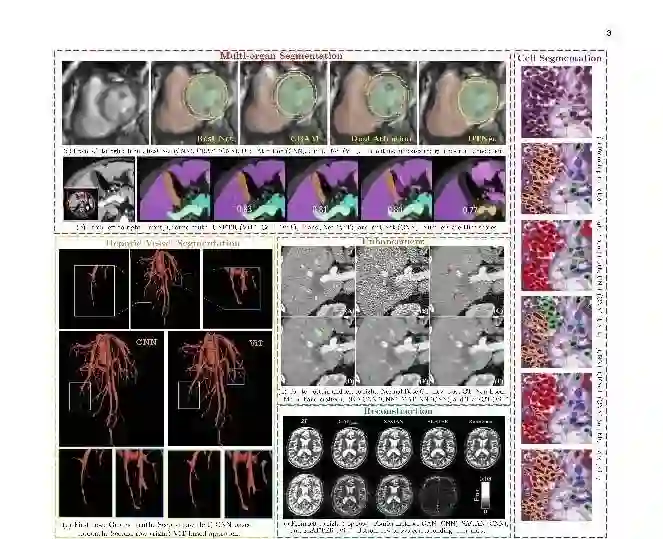
精确的医学图像分割是计算机辅助诊断、图像引导手术和治疗规划的关键步骤。Transformer的全局上下文建模能力对于精确的医学图像分割至关重要,因为通过建模空间距离远的像素之间的关系(例如,肺分割),可以有效地对分布在大接收域上的器官进行编码。此外,医学扫描的背景通常是分散的(如超声扫描[94]);因此,学习与背景相对应的像素之间的全局上下文可以帮助模型防止误分类。下面,我们将重点介绍在医学图像分割中整合基于ViT模型的各种尝试。鉴于两组方法所需的上下文建模水平不同,大致将基于vit的分割方法分为器官特异性和多器官类别,如图5所示。
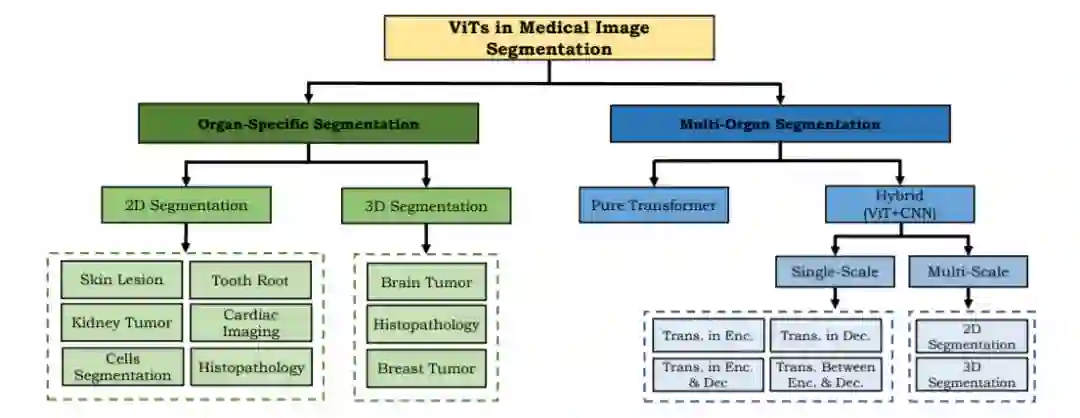
基于VIT的医学图像分割方法分类
医学图像分类
医学图像的准确分类是辅助临床护理和治疗的重要手段。本节将全面介绍VIT在医学图像分类中的应用。由于与这些分类相关的一系列不同挑战,我们将这些方法大致分为基于COVID-19、肿瘤和视网膜疾病的分类方法,如图13所示。
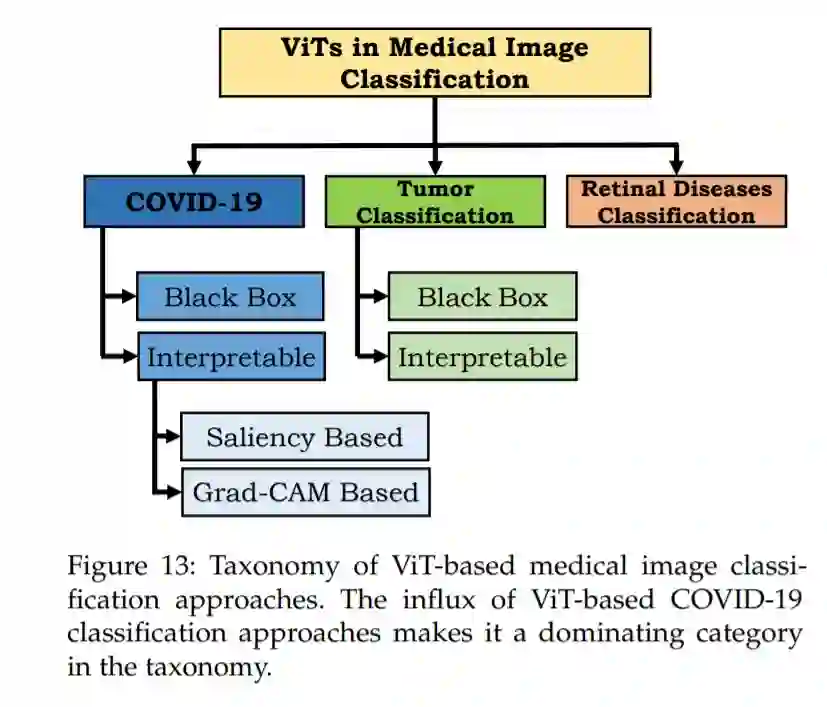
医学图像检测
在医学图像分析中,目标检测是指从x射线图像中定位和识别感兴趣的区域(如肺结节),通常是诊断的一个重要方面。然而,这是临床医生最耗时的任务之一,因此需要准确的计算机辅助诊断(CAD)系统作为第二个观察者,可能加快这一过程。随着CNN在医学图像检测方面的成功[278],[279],最近很少有人尝试使用Transformer模型进一步提高性能。这些方法主要是基于检测Transformer (DETR)框架[24]。
医学图像重建
医学图像重建的目标是从退化的输入中获得一幅干净的图像。例如,从采样不足的版本中恢复高分辨率的MRI图像。由于其不适定性,这是一项具有挑战性的任务。在许多实际的医学成像场景中,精确解析逆变换是未知的。最近,VIT已被证明可以有效地应对这些挑战。我们将相关工作分为医学图像增强和医学图像恢复两个领域,如图18所示。
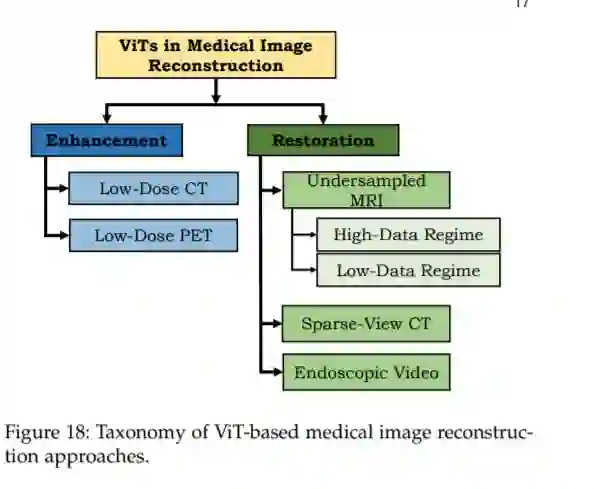
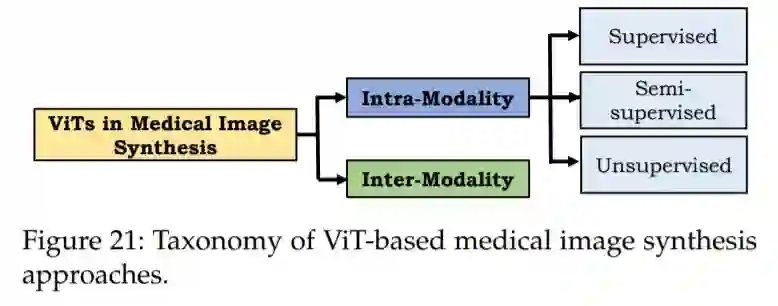
医学图像合成
在本节中,我们将概述VIT在医学图像合成中的应用。大多数这些方法都包含了对抗性损失,以合成真实和高质量的医学图像,尽管代价是训练不稳定[314]。我们进一步将这些方法分为模态内合成和模态间合成。
医学图像配准
医学图像配准的目标是找到密集的逐体素位移,并在一对固定和移动图像之间建立对齐。在医学成像中,当分析不同时间、不同视角或不同模式(如MRI和CT)获得的一对图像时,配准可能是必要的[75]。由于难以从多模态医学图像中提取有区别的特征、复杂的运动以及缺乏鲁棒的离群点拒绝方法,精确的医学图像配准是一项具有挑战性的任务[329]。在本节中,我们将简要介绍ViT在医学图像配准中的应用。
医学图像配准
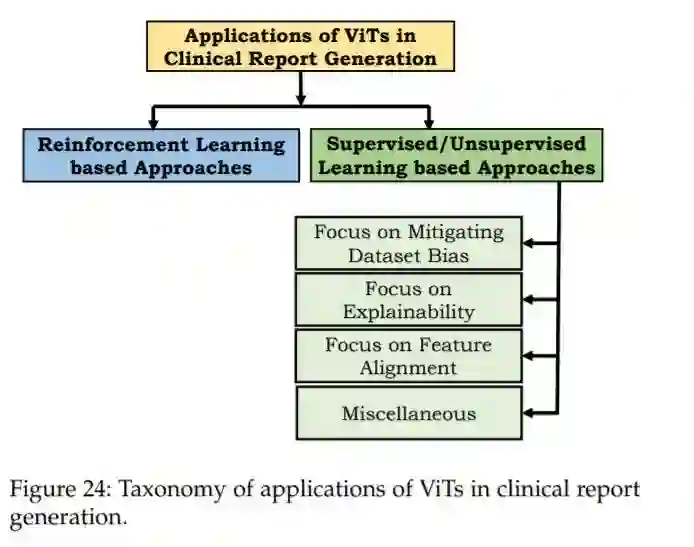
最近,利用深度学习技术从医学图像中自动生成临床报告取得了巨大进展[335]-[338]。这种自动生成报告的过程可以帮助临床医生做出准确的决策。然而,由于不同放射科医生报告的多样性、长序列长度(不像自然图像标题)和数据集偏差(与异常数据相比,更多的是正常数据),从医学图像数据生成报告(或标题)具有挑战性。此外,一个有效的医学报告生成模型有望处理两个关键属性:(1)语言流利性,便于人类阅读(2)临床准确性,以正确识别疾病及相关症状。在本节中,我们将简要描述变压器模型如何帮助实现这些预期目标,并有效地缓解前面提到的与生成医疗报告相关的挑战。具体来说,这些基于transformers的方法在自然语言生成(NLG)和临床疗效(CE)指标方面都取得了最先进的性能。还要注意的是,与主要讨论ViT的前几节不同,在本节中,重点是将transformer作为一种强大的语言模型来利用句子生成的长期依赖关系。由于其潜在的训练机制不同,我们将基于Transformers的临床报告生成方法大致分为基于强化学习(RL)和有监督/无监督学习方法,如图24所示。
结论与未来方向
最后,我们首次全面回顾了Transformers 在医学成像中的应用。我们简要介绍了Transformer模型成功背后的核心概念,然后提供了Transformer在广泛的医疗成像任务中的全面文献综述。具体介绍了Transformers在医学图像分割、检测、分类、重建、合成、配准、临床报告生成等方面的应用。特别是,对于每一个应用,我们提出了分类法,确定了应用特定的挑战,并给出了解决它们的见解,并指定了最近的趋势。尽管它们的表现令人印象深刻,但我们预计,在医学成像领域,Transformers仍有很多探索工作要做,我们希望这项调研为研究人员进一步推进这一领域提供了一个路线图。
未来挑战包括:
- 在大数据集上进行预训练的挑战,
- 基于ViT视觉技术的医学成像方法的可解释性,
- 对抗攻击的鲁棒性,
- 为实时医疗应用设计有效的ViT视觉技术架构,
- 在分布式设置中部署基于ViT技术的模型的挑战,
- 以及领域适应