

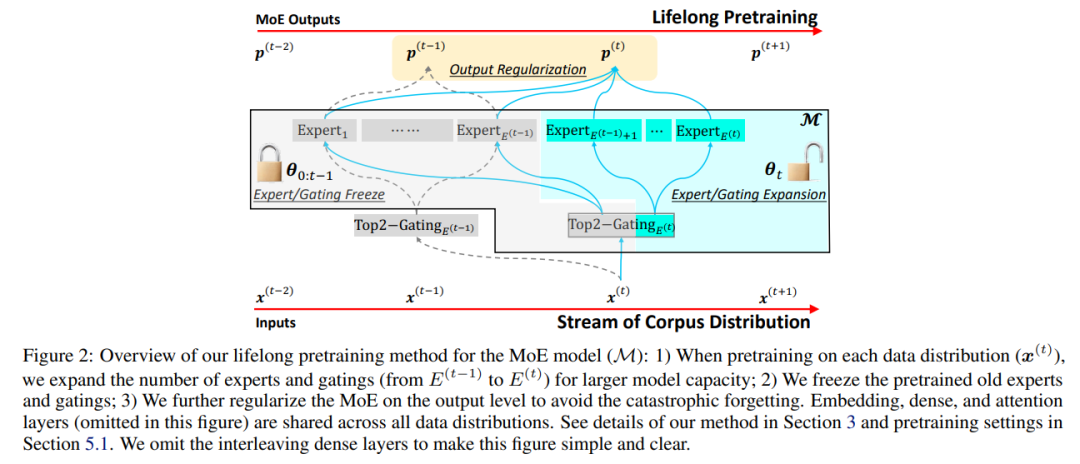
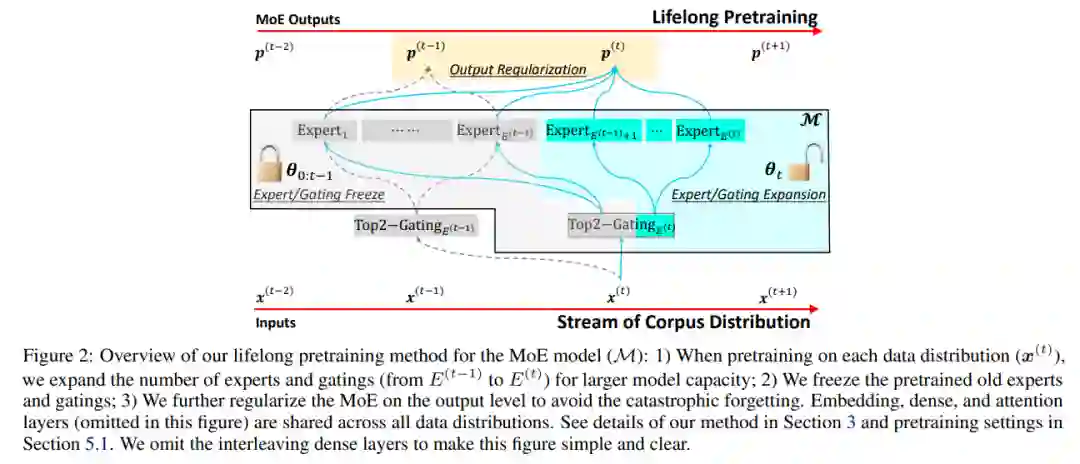
在大规模语料库上进行预训练已经成为构建通用语言模型(LMs)的标准方法。适应新的数据分布以针对不同的下游任务是一项重大挑战。简单的微调可能会导致灾难性的遗忘,当超参数化的LMs过度拟合新数据但无法保留预训练特征时。终身学习(LLL)的目标是使信息系统能够在时间跨度上从连续数据流中学习。然而,大部分先前的工作都是修改训练策略,假定网络架构是静态固定的。我们发现额外的模型容量和适当的正则化是实现强大LLL性能的关键元素。因此,我们提出了Lifelong-MoE,这是一个可扩展的MoE(专家混合)架构,通过添加带有正则化预训练的专家动态增加模型容量。我们的结果表明,只引入有限数量的额外专家同时保持计算成本恒定,我们的模型可以稳定地适应数据分布的变化同时保留先前的知识。与现有的终身学习方法相比,LifelongMoE在19个下游NLP任务上实现了更好的少样本性能。
https://arxiv.org/abs/2305.12281
成为VIP会员查看完整内容

相关内容


相关VIP内容
相关资讯
相关论文