

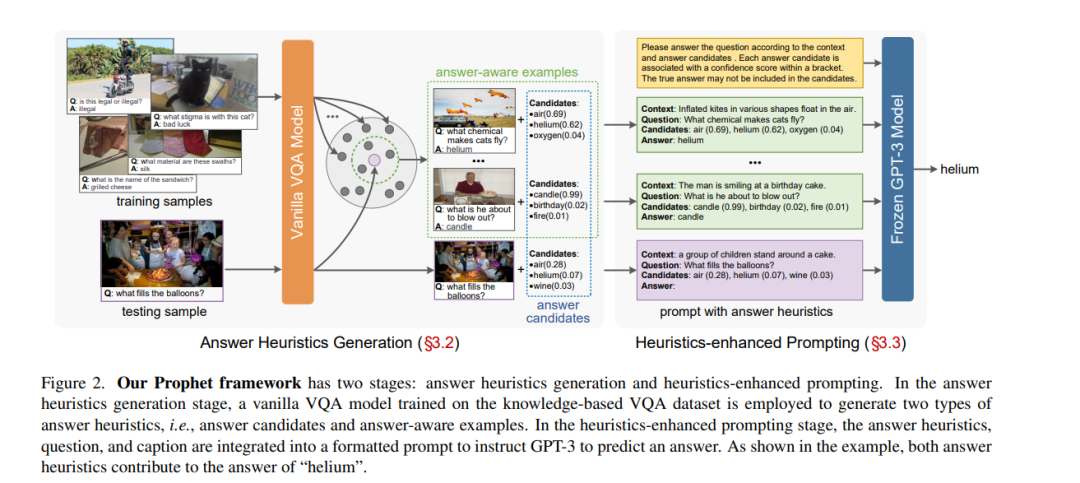
基于知识的视觉问答(VQA)需要图像以外的外部知识来回答问题。早期的研究从显式知识库(KBs)中检索所需的知识,但这些知识往往会引入与问题无关的信息,从而限制了模型的性能。最近的工作试图使用大型语言模型(即GPT-3[3])作为隐式知识引擎,以获取必要的知识进行回答。尽管这些方法取得了令人鼓舞的结果,但由于提供的输入信息不足,它们并没有充分激活GPT-3的能力。**本文提出prophet——一个概念简单的框架,旨在用答案启发式方法提示GPT-3进行基于知识的VQA。**首先,在没有外部知识的情况下,在特定的基于知识的VQA数据集上训练了一个普通的VQA模型。然后,从模型中抽取两类互补答案启发:答案候选和答案感知示例。最后,将两类答案启发编码到提示信息中,使GPT-3能够更好地理解任务,从而提高其能力。Prophet在两个具有挑战性的基于知识的VQA数据集OK-VQA和A-OKVQA上明显优于所有现有的最先进方法,在它们的测试集上分别取得了61.1%和55.7%的准确率。
https://www.zhuanzhi.ai/paper/041ce0c21c2475799872dddbbfef55df
成为VIP会员查看完整内容
相关内容

CVPR 2023大会将于 6 月 18 日至 22 日在温哥华会议中心举行。CVPR是IEEE Conference on Computer Vision and Pattern Recognition的缩写,即IEEE国际计算机视觉与模式识别会议。该会议是由IEEE举办的计算机视觉和模式识别领域的顶级会议,会议的主要内容是计算机视觉与模式识别技术。
CVPR 2023 共收到 9155 份提交,比去年增加了 12%,创下新纪录,今年接收了 2360 篇论文,接收率为 25.78%。作为对比,去年有 8100 多篇有效投稿,大会接收了 2067 篇,接收率为 25%。
专知会员服务
26+阅读 · 2022年3月1日
Arxiv
12+阅读 · 2020年12月14日

相关VIP内容
专知会员服务
26+阅读 · 2022年3月1日
相关资讯