
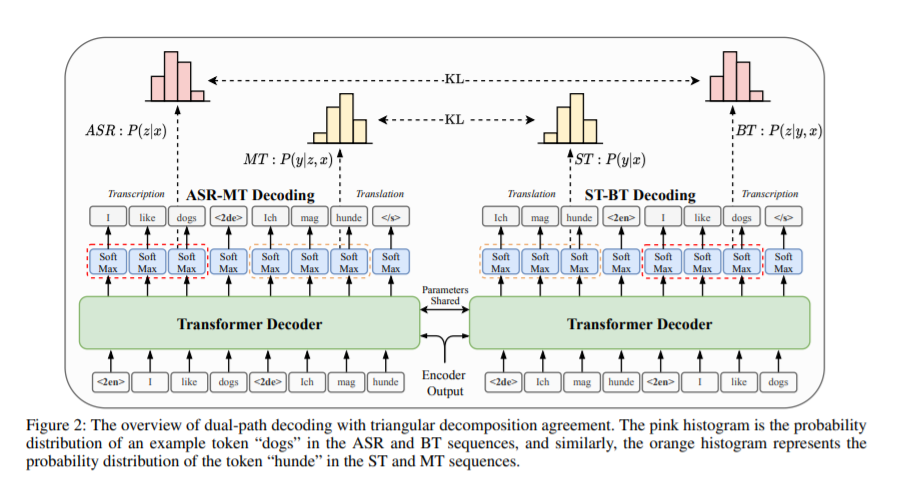
端到端语音翻译由于其错误传播更少、延迟更低和模型更小的潜力而变得越来越流行。对于给定三元组训练语料<speech,transcription,translation>,传统的高质量端到端语音翻译系统利用<speech,transcription>预训练模型,然后利用<speech,translation>进一步优化它。
然而,该过程在每个阶段只涉及二元组数据,这种松散耦合未能充分利用三元组数据之间的关联。我们的工作中,尝试基于语音输入对转录和翻译的联合概率进行建模,以直接利用此类三元组数据。在此基础上,提出了一种新颖的三角分解一致性正则化训练方法,以提高对偶路径分解的一致性。
论文标题: Regularizing End-to-End Speech Translation with Triangular Decomposition Agreement
论文链接: https://www.zhuanzhi.ai/paper/25b3065b3ad1012e9751664ac8cd28ed
成为VIP会员查看完整内容
相关内容
Arxiv
0+阅读 · 2022年4月18日
Arxiv
13+阅读 · 2019年11月14日


相关VIP内容
相关资讯
相关论文
Arxiv
0+阅读 · 2022年4月18日
Arxiv
13+阅读 · 2019年11月14日