AAAI 2019 | 基于分层强化学习的关系抽取

本文是清华大学发表在 AAAI 2019 上的一篇关系抽取方向的文章。作者开创性地提出了使用层次强化学习做关系抽取的方法,在不同数据集上和现有方法相比都有提高。
作者丨刘朋伯
学校丨哈尔滨工业大学硕士生
研究方向丨自然语言处理
现有的关系抽取方法大多是先识别所有实体然后再确定关系类型。但是这类方法并没有考虑到实体与关系之间的作用。本文应用分层强化学习框架来增强实体提及和关系类型之间的交互,将相关实体视为关系的集合。此外,该方法还解决了抽取重叠关系(Overlapping Relations)的问题。


研究动机
该研究主要解决的问题有两个:
1. 大部分现有的方法在实体被识别后才决策关系类型。这种方法存在两个弊端:一是并没有充分挖掘实体和关系之间的联系,而是把他们割裂作为两个子任务去处理;二是很多和关系无关的实体会带来噪声;
2. 关系抽取会存在重叠关系问题(也叫一对多问题)。在一句话中,一个实体可能会存在多个关系,或者一个实体对可能存在多种关系。目前已知只有 CopyR 方法研究了这个问题,但是本文作者实验证明了这种方法严重依赖数据,并且无法抽取多词语关系。 如图:
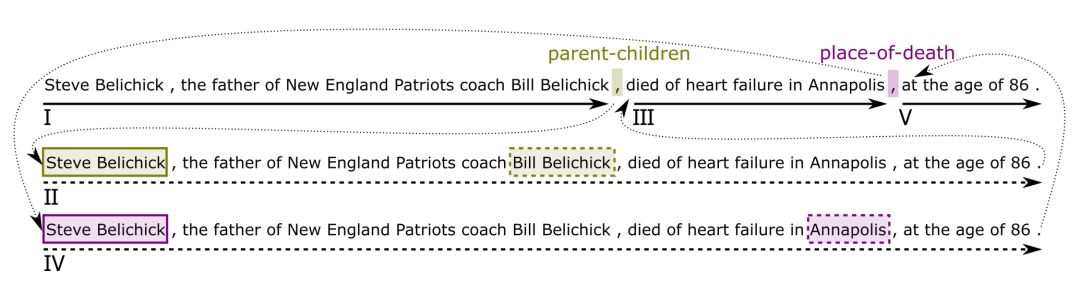
层次抽取框架
首先,文章定义了“关系指示符”(Relation Indicator)。 当在一句话中的某个位置有足够信息去识别语义关系时,我们把这个位置就叫做“关系指示符”。它可以是名词、动词、介词,或者是一些其他的符号比如逗号、时间等等。关系指示符在本结构中非常重要,因为整个的关系抽取任务可以分解为“关系指示符”和“关系中的实体抽取”。
整体来看,关系抽取过程如下:
一个 agent 在扫描句子时预测特定位置的关系类型。不同于识别实体对之间关系的关系分类,该过程不需要对实体进行标注。当在一个时间步中没有足够的信息来指示语义关系时,agent 可以选择 NR,这是一种指示没有关系的特殊关系类型。否则,触发一个关系指示符,agent 启动一个用于实体提取的子任务,以识别两个实体之间的关系。当实体被识别时,子任务完成,代理继续扫描句子的其余部分寻找其他关系。
这种过程可以被表述为半马尔可夫决策过程:1)检测句子中关系指示符的高级 RL 过程;2)识别对应关系的相关实体的低级 RL 过程。
通过将任务分解成两个 RL 过程的层次结构,该模型有利于处理对于同一实体对具有多种关系类型的句子,或者一个实体涉及多种关系的情况。过程如图:
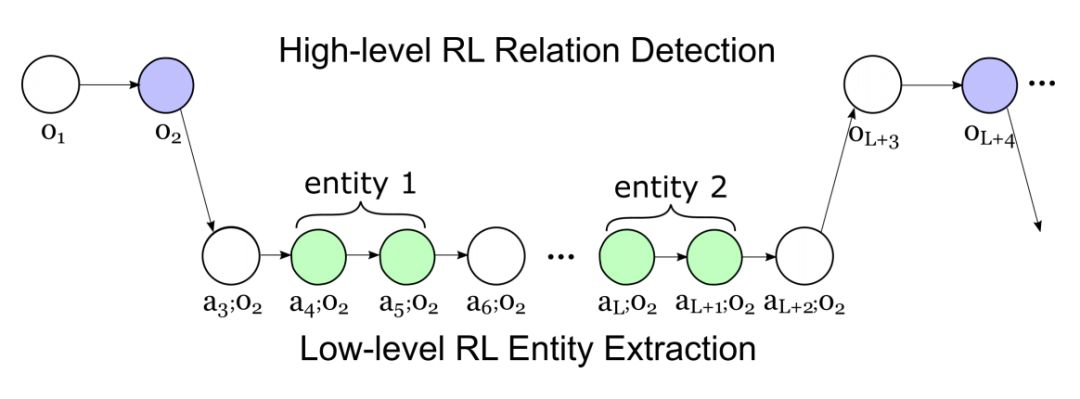
下面分别介绍两个决策过程。
Relation Detection with High-level RL
High-level RL 的策略(policy)µ 旨在从句子中找到存在的关系,可以看做是带有 options 的 RL policy。option 指的是一旦 agent 执行了某个选项,就会启动低级别的 RL 策略。
Option:option 在集合 O = {NR} ∪ R 中选择,当 low-level RL 进入结束状态,agent 的控制将被 high-level 接管去执行下一个 option。
State:状态 S 由以下三者共同决定:当前的隐状态,最后一个 option 的 relation type vector
和上一个时间步的状态
。公式如下:
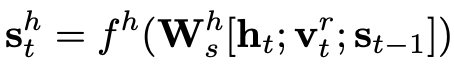
是非线性变换,
是由 Bi-LSTM 得到隐状态。
Policy:关系检测的策略,也就是 option 的概率分布,如下,其中 W 是权重:
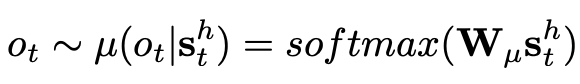
Reward:环境提供给 Agent 的一个可量化的标量反馈信号,也就是 reward。reward 计算方法如下:
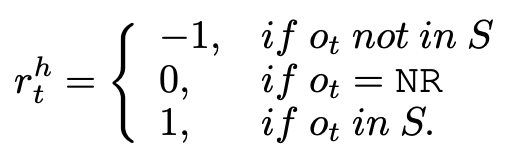
最后,用一个最终的 reward 来评价句子级别的抽取效果:
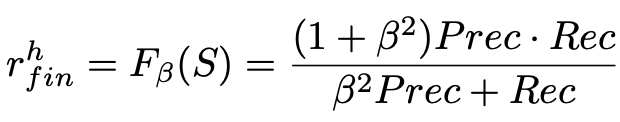
Entity Extraction with Low-level RL
当 High-level RL policy 预测了一个非 NR 的relation,Low-level RL 会抽取 relation 中的实体。High-level RL 的 option 会作为 Low-level RL 的额外输入。
Action:action 会给当期的词分配一个 tag,tag 包括 A=({S,T,O}×{B,I})∪{N}。其中,S 是参与的源实体,T 是目标实体,O 是和关系无关的实体,N 是非实体单词,B 和 I 表示一个实体的开始和结束。可参看下图:
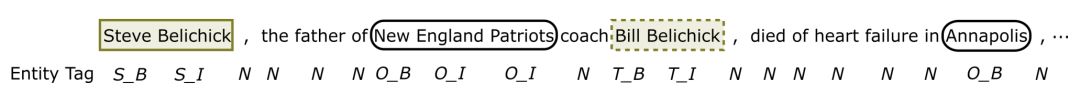
State:类似 High-level RL 中的关系检测,High-level 中的状态计算方法如下:
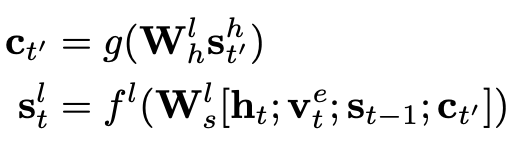
是当前单词的隐状态,同样也是经过 Bi-LSTM 计算得到,Vet 是可学习的实体标签向量,
是上一阶段的状态(注意,既可以是 High-level 的状态,也可以是 Low-level 的状态)。g 和 f 都是多层感知机。
Policy:由句子到实体的概率计算如下:
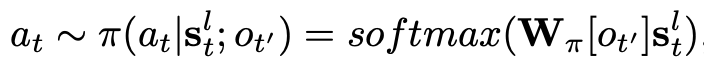
Reward:给定一个关系类型,通过 policy 可以很容易得到实体标签。我们需要用 reward 来衡量预测的标签是否准确:
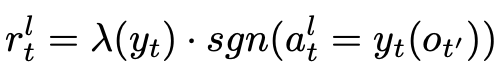
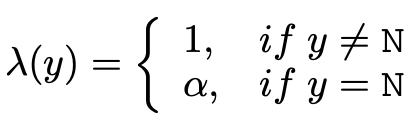
其中,λ(y) 用来降低 non-entity tag 的权重。
Hierarchical Policy Learning
在优化 High-level policy 时,我们需要最大化预期累积回报,如下:
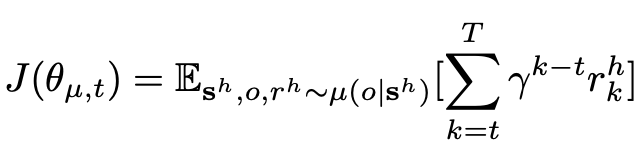
γ 是 RL 中的折扣因子。在结束前,整个采样过程需要 T 个时间步长。
同样的,在优化 Low-level policy 时,我们也需要最大化累计回报,公式如下:
把累计回报分解成 Bellman 方程,得到:
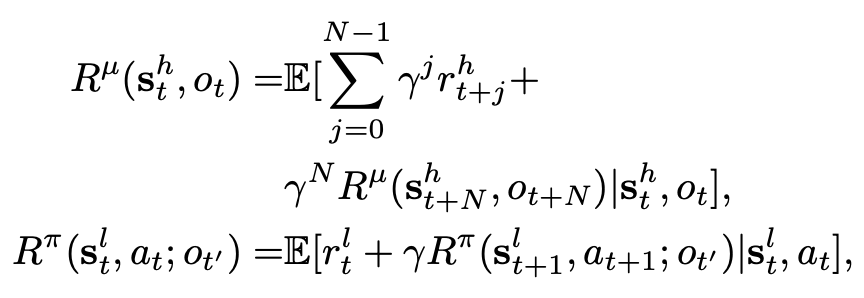
当实体提取策略根据选项 ot 运行时,子任务持续的时间步数是 N。当 option 是 NR 是,N=1。
可以一同优化 High-level 和 Low-level 两段策略,High-level 的梯度是:
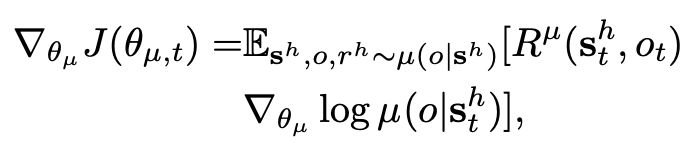
Low-level 的梯度是:
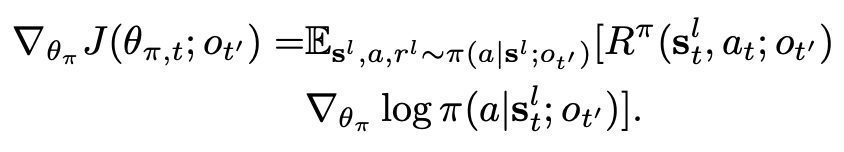
整个训练过程如下:

实验
数据集:通过远程监督得到的数据:NYT10 和 NYT11。
参数设置:预训练词向量使用 300 维的 GloVe 词向量,Relation Type Vectors 和 Entity Tag Vectors 是随机初始化的,学习率:4e − 5,mini-batch size:16,α = 0.1,β = 0.9,discount factor γ = 0.95。
评价方法:采用 micro-F1 评价方法,如果关系类型和两个对应的实体都正确,则认为三元组是正确的。
Baselines:作为对比的 baseline 方法有:FCM、MultiR、CoType、SPTree、Tagging 和 CopyR。
实验结果
Split:输入为 c×h×w 的特征图,和
均表示 Group Convolution。这里使用 Group Convolution 以减少计算量。注意,这里两路 Group Convolution 使用的卷积核大小不一致,原因在于 Motivation 中说的第一点,提升精度。
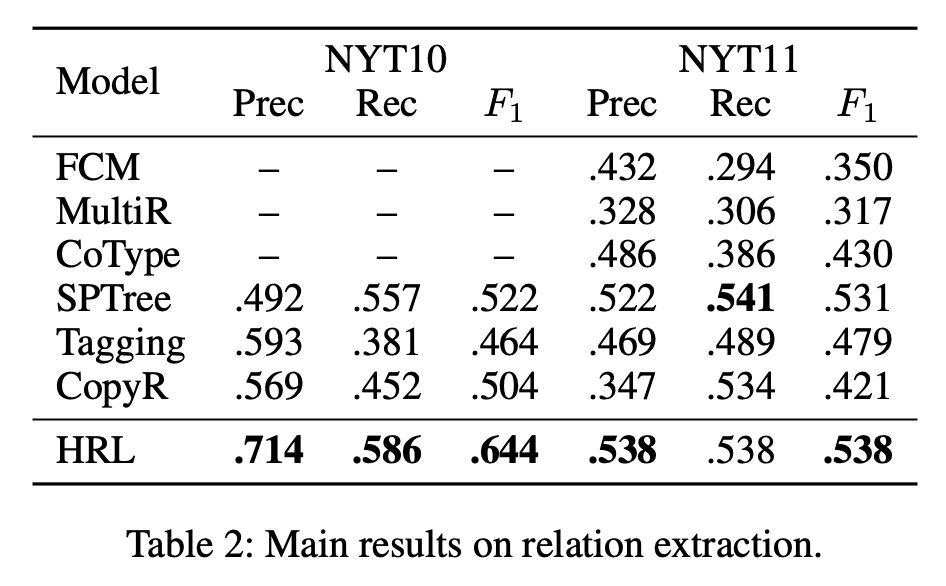
▲ 关系抽取
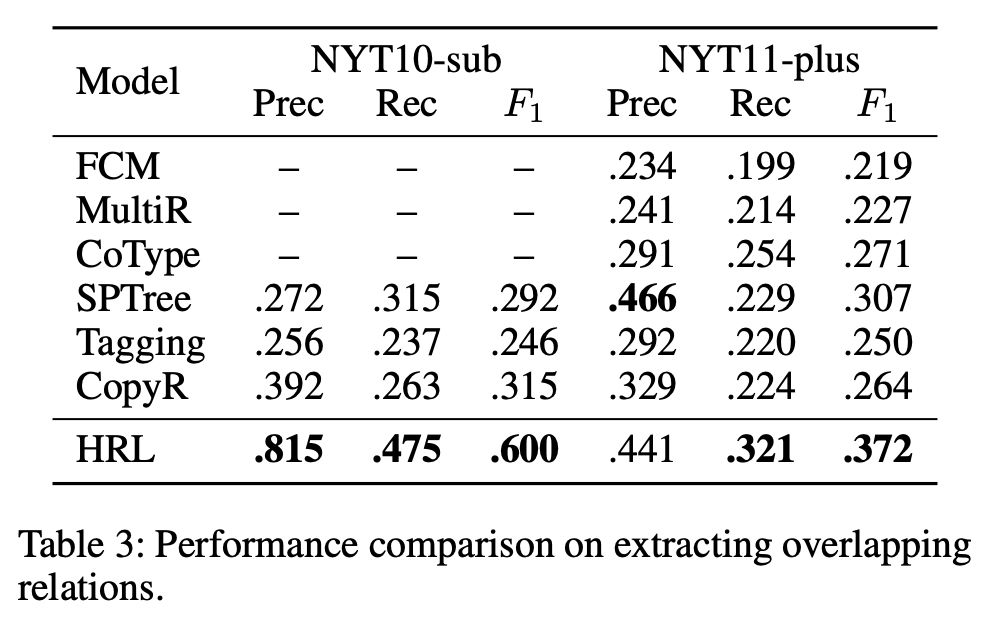
▲ 重叠关系抽取
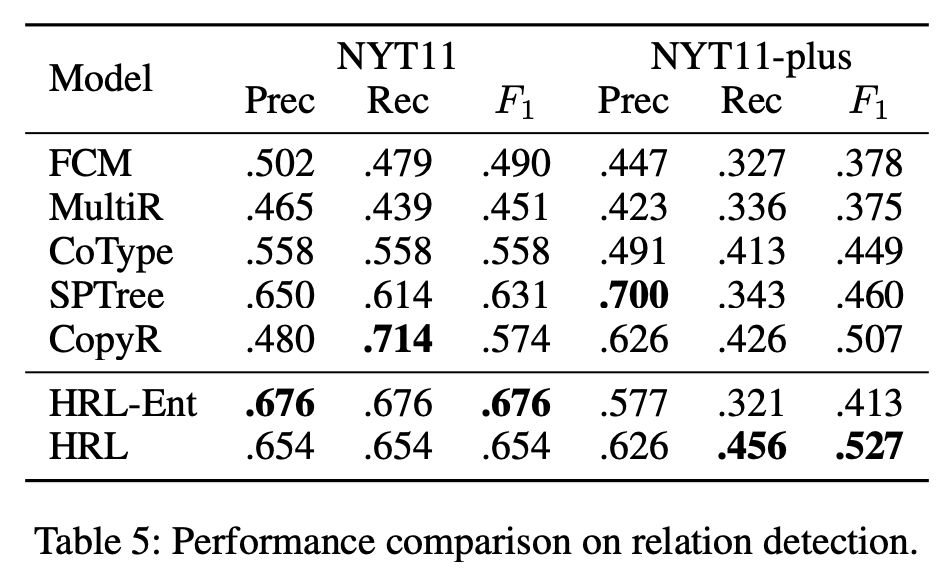
▲ 关系检测
总结
在本文中,作者提出了一种通过分层强化学习进行关系抽取的分层抽取范式。该范式将实体视为关系的集合,并将关系抽取任务分解为两个子任务的层次结构:High-level 指示符检测和 Low-level 实体抽取。
关系检测的 High-level 策略识别句子中的多个关系,实体提取的 Low-level 策略启动子任务以进一步提取每个关系的相关实体。这种方法擅长于建模两个子任务之间的交互,尤其擅长于提取重叠关系。
实验证明,该方法优于最先进的基线。目前,强化学习在 NLP 的应用较少,该工作为关系抽取任务带来了启发,事实证明,基于强化学习的关系抽取是可以成功的。

点击以下标题查看更多往期内容:

让你的论文被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢? 答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学习心得或技术干货。我们的目的只有一个,让知识真正流动起来。
📝 来稿标准:
• 稿件确系个人原创作品,来稿需注明作者个人信息(姓名+学校/工作单位+学历/职位+研究方向)
• 如果文章并非首发,请在投稿时提醒并附上所有已发布链接
• PaperWeekly 默认每篇文章都是首发,均会添加“原创”标志
📬 投稿邮箱:
• 投稿邮箱:hr@paperweekly.site
• 所有文章配图,请单独在附件中发送
• 请留下即时联系方式(微信或手机),以便我们在编辑发布时和作者沟通
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
关于PaperWeekly
PaperWeekly 是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事 AI 领域,欢迎在公众号后台点击「交流群」,小助手将把你带入 PaperWeekly 的交流群里。

▽ 点击 | 阅读原文 | 下载论文 & 源码




