
转载于“计算机研究与发展”
近年来,大型语言模型的出现和发展对自然语言处理和人工智能领域产生了变革性影响. 随着不断增大模型参数量和训练数据量,语言模型的文本建模困惑度以可预测的形式降低,在各类自然语言处理任务上的表现也持续提升. 因此,增加语言模型的参数和数据规模成为提升系统智能水平的富有前景的途径.
本文首先回顾了大型语言模型的基本定义,从模型表现和算力需求的角度给出了“大型”语言模型的界定标准. 其次,从数据、算法、模型三个维度梳理了大型语言模型的发展历程及规律,展示了不同阶段各个维度的规模化如何推动语言模型的发展. 接着,考察了大型语言模型所表现出的涌现能力,介绍了思维链、情景学习和指令遵循等关键涌现能力的相关研究和应用现状. 最后,展望了大型语言模型的未来发展和技术挑战.
内容简介

1.回顾了大型语言模型的基本定义,从模型表现和算力需求的角度给出了“大型”语言模型的界定标准. 2.从数据、算法、模型三个维度梳理了大型语言模型的发展历程及规律,展示了不同阶段各个维度的规模化如何推动语言模型的发展. 3.考察了大型语言模型所表现出的涌现能力,介绍了思维链、情景学习和指令遵循等关键涌现能力的相关研究和应用现状. 4.展望了大型语言模型的未来发展和技术挑战.
亮点图文
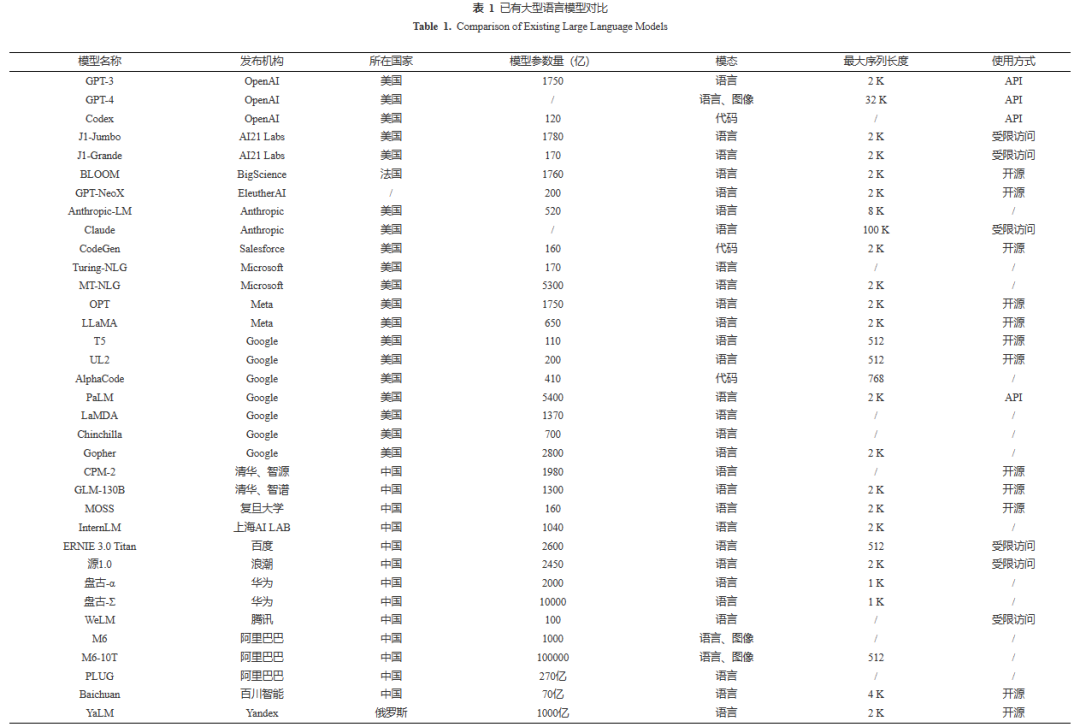
如下图展示了语言模型的主要发展路径:2008年,Collobert等人发现将语言模型作为辅助任务预先训练可以显著提升各个下游任务上的性能,初步展示了语言模型的通用性;2013年,Mikolov等人在更大语料上进行语言模型预训练得到一组词向量,接着通过迁移学习的手段,以预训练得到的词向量作为初始化,使用下游任务来训练任务特定模型;2018年,Google的Devlin等人将预训练参数从词向量扩增到整个模型,同时采用Transformer架构作为骨干模型,显著增大了模型容量,在诸多自然语言处理任务上仅需少量微调即可取得很好的效果;随后,研究人员继续扩增模型参数规模和训练数据量,同时采取一系列对齐算法使得语言模型具备更高的易用性、忠诚性、无害性,在许多场景下展现出极强的通用能力,OpenAI于2022年底发布的ChatGPT以及2023年发布的GPT-4是其中的代表. 纵观近十余年来语言模型的发展历程,不难发现两个规律:

- 以语言模型及其变体为训练任务,从多个维度实现规模化. 从2008年到今天,语言模型的训练任务变化很小,而其训练数据逐渐从6亿单词增长到今天的超万亿单词,算法从传统的多任务学习范式发展到更适合大规模预训练的迁移学习范式,模型从容量较小的CNN/RNN模型发展为包含超过千亿参数的Transformer模型.
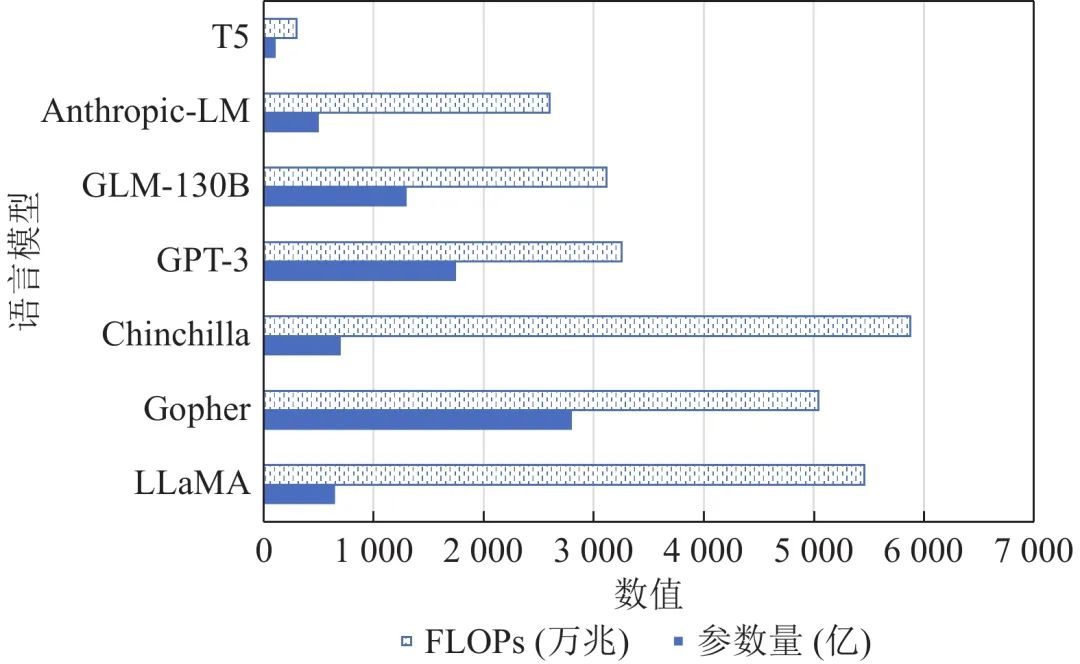
- 将更多模型参数和训练任务从下游转移到上游. 从模型参数的角度,2013年以前的大多数模型要从头训练(training from scratch)所有参数;2013年到2018年主要基于预训练的词向量训练参数随机初始化的任务特定模型;2018年到2020年逐渐转向“预训练+微调”范式,即使用预训练模型作为下游任务初始化,仅需添加少量任务特定参数,例如在预训练模型上添加一个随机初始化的线性分类器;2020年左右,基于提示(prompt)的方法得到了很大发展,通常直接使用包括语言模型分类头(language modeling head)在内的整个预训练语言模型,通过调整其输入内容来得到任务特定输出. 从训练任务的角度,语言模型从与其他下游任务联合多任务训练逐渐发展成为独立的上游任务,通过数据、模型、算法等多个维度的规模化逐渐降低对下游任务训练的需求,近年来的大型语言模型通常在已有的上千个指令化自然语言处理任务(例如FLAN)上训练,从而可以在未经下游任务训练的情况下很好地泛化到未见任务上. 如下图给出了当前常见的大型语言模型的参数量和训练计算量,不难发现,较近的语言模型(如Chinchilla和LLaMA)通常采用相对较大的训练数据和相对较小的参数规模,这在下游微调和推理部署时具有显著的效率优势.
到目前为止,规模定律仍然是一个非常重要且值得探索的方向,特别是中文语言模型的规模定律尚未有公开研究. 此外,已有的对规模定律的研究主要为通过大量实验得出的经验性规律,而缺乏对其理论机理的解释.
** 以ChatGPT、GPT-4为代表的大型语言模型已经在社会各界引起了很大反响,其中GPT-4已经初步具备通用人工智能的雏形. 一方面,大型语言模型的强大能力向人们展现了广阔的研究和应用空间;而另一方面,这类模型的快速发展也带来了许多挑战和应用风险.
未来发展
1)高效大型语言模型.当前大型语言模型主要采用Transformer架构,能够充分利用GPU的并行计算能力并取得不俗的性能表现. 但由于其计算和存储复杂度与输入文本长度呈平方关系,因此存在推理效率慢、难以处理长文本输入等缺陷. 2)插件增强的语言模型.集成功能插件已经成为大型语言模型快速获得新能力的重要手段3)实时交互学习.语言模型能够在与用户交互过程中完成实时学习,特别是能够根据用户输入的自然语言指令更新自身知识是迈向通用人工智能的重要步骤.4)语言模型驱动的具身智能.通过多模态深度融合、强化逻辑推理与计划能力等手段,打造具备强大认知智能的具身系统正在成为大型语言模型和机器人领域的研究热点.
** 挑战**1)检测.大型语言模型生成的文本高度复杂甚至相当精致,在很多场景下难以与人类创作的文本区分开. 因而,语言模型生成文本的检测和监管成为亟待解决的问题,2)安全性.大型语言模型的训练数据大量来自互联网上未经标注的文本,因而不可避免地引入了有害、不实或歧视性内容. 如何构造适合中文环境的安全性评估标准及其相应训练数据仍然是中文语言模型大规模落地应用的重要挑战.3)幻觉.目前ChatGPT和GPT-4等高性能语言模型仍然存在较严重的幻觉问题,即经常生成包含事实性错误、似是而非的文本,这严重影响了其在部分专业领域应用的可靠性.有效识别模型的内部知识和能力边界仍旧是极具挑战性的未解之题. 总之,大型语言模型给自然语言处理乃至人工智能领域带来了巨大的范式变革,将原来按不同任务进行横向划分的领域设定转变为按流程阶段进行纵向划分的新型研究分工,并构建了以大型语言模型为中心的人工智能新生态.
引用格式
舒文韬, 李睿潇 , 孙天祥, 黄萱菁, 邱锡鹏. 大型语言模型:原理、实现与发展[J]. 计算机研究与发展. doi: 10.7544/issn1000-1239.202330303 Shu Wentao, Li Ruixiao, Sun Tianxiang, Huang Xuanjing, Qiu Xipeng. Large Language Models: Theories, Methods, and Progress[J]. Journal of Computer Research and Development. doi: 10.7544/issn1000-1239.202330303