机器翻译新时代:Facebook 开源无监督机器翻译模型和大规模训练语料
【导读】基于深度学习的机器翻译往往需要数量非常庞大的平行语料,这一前提使得当前最先进的技术无法被有效地用于那些平行语料比较匮乏的语言之间。为了解决这一问题,Facebook提出了一种不需要任何平行语料的机器翻译模型。该模型的基本思想是, 通过将来自不同语言的句子映射到同一个隐空间下来进行句子翻译。近日,Facebook开源了这一翻译模型MUSE: Multilingual Unsupervised and Supervised Embeddings,并提供预训练好的30种语言的词向量和110个大规模双语词典。
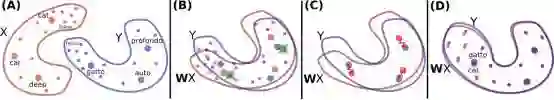
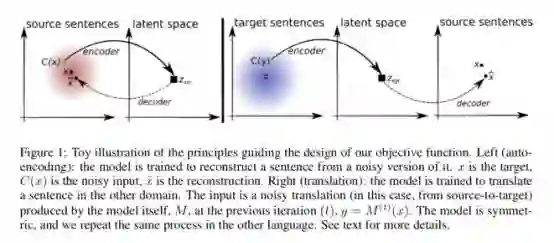
▌主要流程
1、先用单语语料训练两个词向量空间,然后用无监督方法对齐这两个空间
2. 对齐 encoder 语义空间,两种语言各一个 decoder;用 denoising auto-encoder 训练单语语言模型,用 back-translation 造伪平行语料优化似然函数
Facebook MUSE: a Python library for multilingual word embeddings now open sourced!
转自:专知
完整内容请点击“阅读原文”
登录查看更多
相关内容



相关VIP内容
相关资讯
相关论文