

本文提供了一个关于大型语言模型(LLMs)在软件工程(SE)中应用的新兴领域的调查。它还提出了将LLMs应用于软件工程师面临的技术问题的开放性研究挑战。LLMs的新兴属性带来了创新性和创造力,其应用覆盖了软件工程活动的全谱,包括编码、设计、需求、修复、重构、性能提升、文档和分析。然而,这些同样的新兴属性也带来了重大的技术挑战;我们需要能够可靠地剔除错误的解决方案,如幻觉。我们的调查揭示了混合技术(传统的SE与LLMs相结合)在开发和部署可靠、高效和有效的基于LLM的SE中的关键作用。本文调查了基于LLM的SE的最近发展、进展和实证结果;即大型语言模型(LLMs)在软件工程(SE)应用的应用。我们使用这次调查来突出这个迅速发展但尚属初级阶段的研究文献中的空白。基于文献中的空白和技术机会,我们还确定了软件工程研究社区的开放问题和挑战。尽管对这样一个迅速扩张的领域的任何调查都既不能渴望也不能声称是全面的,但我们希望这次调查能为这个令人兴奋的新软件工程子学科——基于LLM的软件工程提供一个有用且相对完整的早期概述。尽管该领域的科学和技术结构仍在形成中,但我们已经可以识别出趋势、对未来研究的有益方向以及需要解决的重要技术挑战。特别是,我们已经能够辨别出与软件工程内的现有趋势和既定方法及子学科的重要连接(和共鸣)。尽管总的来说,我们找到了很多乐观的理由,但仍然存在重要的技术挑战,这些挑战很可能在未来几年内影响研究议程。许多作者都从科学和轶事的角度指出,LLMs普遍存在幻觉问题[1],而且它对基于LLM的SE也带来了特定的问题[2]。与人类智慧一样,幻觉意味着LLM可以产生虚构的输出。在软件工程的背景下,这意味着创造的工程制品可能是错误的,但看起来是合理的;LLMs可能引入错误。然而,与LLMs的许多其他应用不同,软件工程师通常有可自动化的真实依据(软件执行),大部分软件工程制品都可以基于此进行评估。此外,软件工程研究社区已经花了很多时间开发自动化和半自动化技术,以检查人类可能产生的错误结果。这意味着,对于这个学科和研究社区,当面对像幻觉这样的问题所带来的挑战时,有大量的经验和专业知识可以借鉴。
显然,自动化测试技术 [3]–[5] 将在确保正确性中发挥核心作用,就像它们已经为人工设计的制品所做的那样。在生成全新的功能和系统时,由于缺乏可自动化的oracle [6](一种自动技术,用于确定给定输入刺激的输出行为是否正确),自动测试数据生成受到限制。考虑到LLMs的幻觉倾向,Oracle问题仍然非常相关,对它的解决方案将变得更加有影响力。但是,一些SE应用关心现有软件系统的适应、改进和开发,对于这些应用,有一个现成的可自动化的oracle:原始系统的功能行为。在本文中,我们称其为“自动回归Oracle”,这种方法已在遗传改进领域得到证明是有益的 [7]。自动回归Oracle简单地使用软件系统的现有版本作为参考,以对任何后续的适应和更改的输出进行基准测试。当然,有“烘焙”功能错误的风险,因为自动回归Oracle无法检测系统应该做什么,只能捕捉它当前做什么。因此,自动回归Oracle只能测试功能退化,所以它最适合于需要保持现有功能的用例。例如,对于性能优化和语义保持不变的重构。LLM的输入将成为越来越多研究的焦点,我们可以预期关于prompt工程和prompt优化文献的迅速发展 [8]。在这次调查中,我们突出了关于软件工程的几个特定方面的prompt工程的现有工作和开放挑战。LLM的输出不仅可以限于代码,还可以包括其他软件工程制品,如需求、测试用例、设计图和文档。总的来说,LLM的基于语言的特性使其能够生成任何语言定义的软件工程制品。我们通常认为软件工程制品是LLM的主要输出,但它不是唯一的输出。与主要输出一起提供的解释也是LLM的重要输出。我们的调查突出了需要进行更多的研究的需求,不仅要优化prompt工程(专注于LLM的输入),还要优化与主要输出一起提供的解释的工作。LLMs本质上是非确定性的:相同的prompt在不同的推断执行中产生不同的答案(除非温度设为零,这在多次执行中经常被发现是次优的)[9]。此外,无论温度设置如何,prompt的微妙变化都可能导致非常不同的输出[9]。除了激励‘prompt工程’和输出处理,这种非确定性行为为基于LLM的软件工程的科学评估带来了挑战:如果每次我们运行整个工程过程时结果都会变化,我们如何确定所提议的技术是否超越了现有的技术?这是一个在经验软件工程[10]和基于搜索的软件工程(SBSE)[11]的背景下已经被深入研究的问题。特别是,SBSE与基于LLM的软件工程有很多相似之处,在存在嘈杂、非确定性和不完整的结果[12]、[13]的情况下实现稳健的科学评估都与之有关。因此,已经有一个成熟的软件工程文献专门研究适用于基于LLM的科学评估所需的稳健的科学评估技术。例如,参数和非参数的推断统计技术现在经常被用来在SBSE学科中提供在高度非确定性算法存在的情况下的稳健的科学结论。为了找出与LLM相关的计算机科学论文,我们过滤了出版物,将其细分为以下子类别:人工智能 (cs.AI)、机器学习 (cs.LG)、神经和进化计算 (cs.NE)、软件工程 (cs.SE) 和编程语言 (cs.PL)。我们使用查询“Large Language Model”、“LLM”和“GPT”在标题或摘要中进行筛选(我们手动排除了重载缩写,例如将GPT误认为是通用规划工具),结果是L列。最后,我们使用相同的查询来识别基于LLM的软件工程论文,这些论文位于软件工程 (cs.SE) 和编程语言 (cs.PL) 类别中。这些查询本质上是近似的,因此我们只局限于基于总体趋势得出的结论,而这些总体趋势有强有力的证据支持,而不是观察到的数字的具体细节。尽管如此,我们报告了观察到的原始数字,以支持其他人的复制。
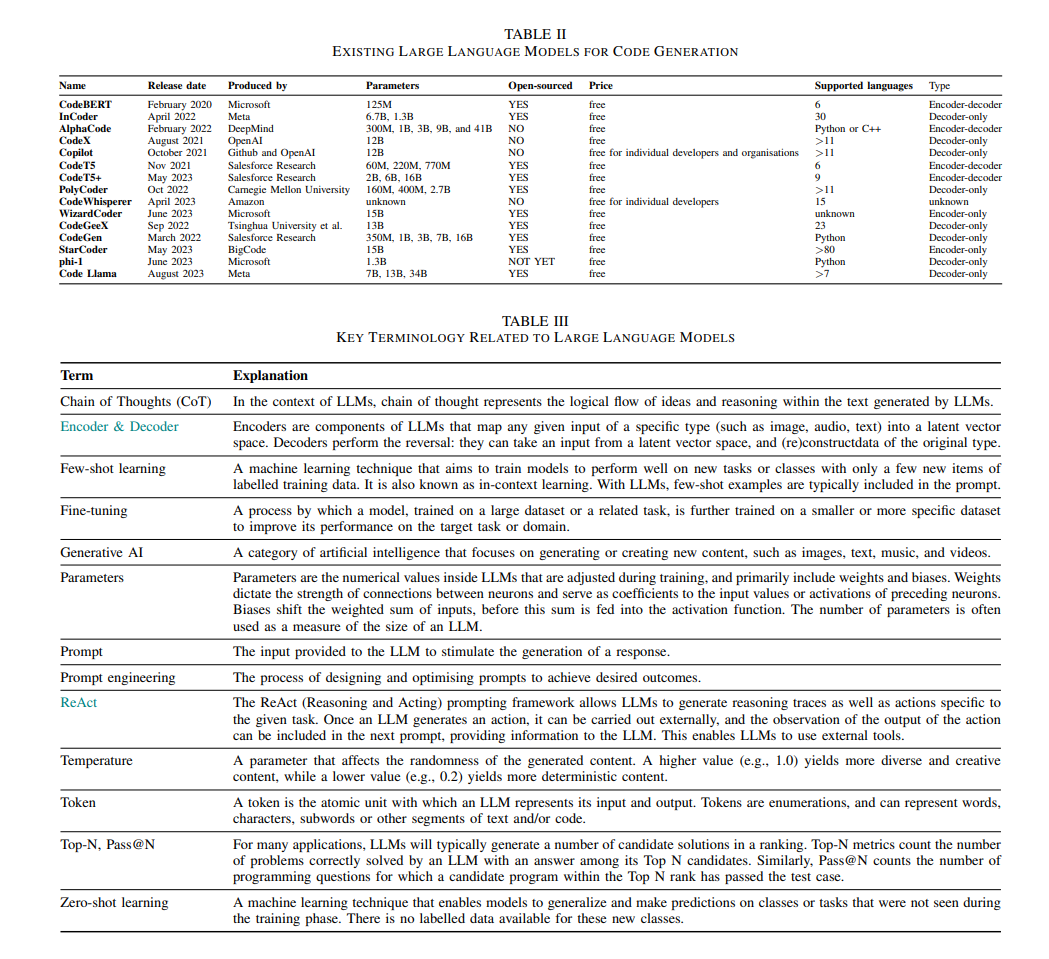
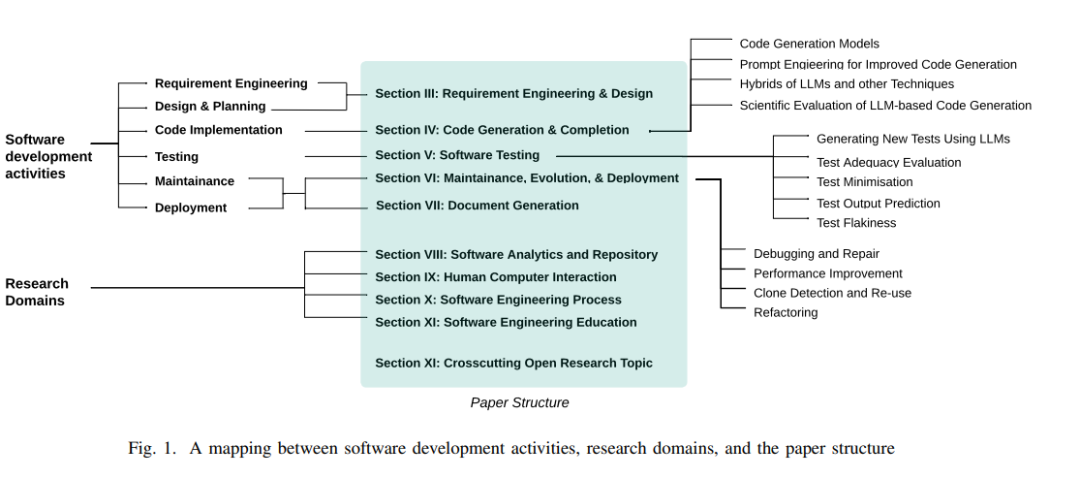
图2展示了arXiv上发布的计算机科学论文数量(|A|,以蓝色表示)和LLM相关论文的数量(|L|,以橙色表示)的增长。特别是与软件工程和LLM相关的论文以绿色表示(|L ∩ S|)。考虑到总体发表量的快速增长,我们为纵轴使用了对数刻度。不出所料,我们看到了计算机科学出版物数量的整体增长。同时,鉴于LLM最近受到的关注增多,LLM相关论文数量的指数增长也相对不足为奇。或许更有趣的是LLM在软件工程应用中的快速采纳,如图中的绿色所示。为了更详细地检查这一趋势,我们在图3中画出了LLM出版物(L)与所有计算机科学出版物(A)的比例(以蓝色表示),以及基于LLM的软件工程出版物(L ∩ S)与所有LLM出版物的比例(以橙色表示)。如图所示,自2019年以来,基于LLM的软件工程论文的比例已经急剧上升。目前,所有关于LLM的论文中已有超过10%与基于LLM的软件工程有关。由于这一增长,我们可以预期将有更多其他的基于LLM的软件工程调查。文献的快速扩展使得进一步的全面软件工程研究不太可能适应单篇论文的空间限制,但我们可以预期会有许多关于感兴趣的子领域的全面调查,以及针对系统评审中的主要文献提出具体研究问题的系统文献回顾(SLRs)。例如,Hou等人[14]提供了一个出色的最新SLR,涵盖了2017年至2023年的229篇研究论文,报告了所处理的软件工程任务、数据收集和预处理技术,以及优化LLM性能的策略(例如提示工程)。本文的其余部分按照主要的顶级软件开发活动和研究领域进行组织。图1显示了软件开发活动、研究领域和我们论文结构之间的映射。