
原创作者:崔涵,宋岩奇 转载须标注出处:哈工大SCIR
摘要
一个一直以来的共识是,模型的规模越大,模型在下游任务上的能力越多、越强。随着最近的新的模型的提出,大规模的语言模型出现了很多超乎研究者意料的能力。我们针对这些在小模型上没有出现,但是在大模型上出现的不可预测的能力——“涌现能力”做了一些归纳和总结,分别简要介绍了涌现能力的定义、常见的激发手段和具体的分类和任务。
缩放法则(Scaling Law)
Kaplan J等人[1]在 2020 年提出缩放法则,给出的结论之一是:模型的性能强烈依赖于模型的规模,具体包括:参数数量、数据集大小和计算量,最后的模型的效果(图中表现为loss值降低)会随着三者的指数增加而线性提高(对于单个变量的研究基于另外两个变量不存在瓶颈)。这意味着模型的能力是可以根据这三个变量估计的,提高模型参数量,扩大数据集规模都可以使得模型的性能可预测地提高。Cobbe等人[2]的工作提出缩放定律同样适用于微调过程。
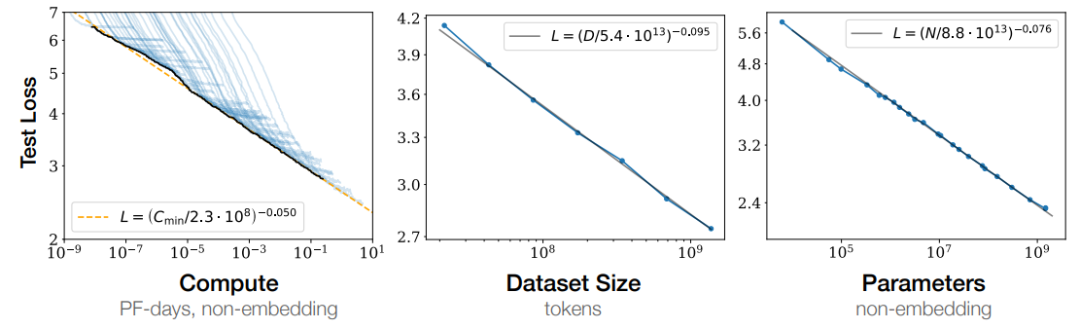
图1:Loss值随计算资源、数据规模大小和参数量的指数提升呈线性下降
缩放定律的一个重要作用就是预测模型的性能,但是随着规模的扩大,模型的能力在不同的任务上并不总表现出相似的规律。在很多知识密集型任务上,随着模型规模的不断增长,模型在下游任务上的效果也不断增加;但是在其他的复杂任务上(例如逻辑推理、数学推理或其他需要多步骤的复杂任务),当模型小于某一个规模时,模型的性能接近随机;当规模超过某个临界的阈值时,性能会显著提高到高于随机(如下图所示)。这种无法通过小规模模型的实验结果观察到的相变,我们称之为“涌现能力”。
涌现能力的概述
涌现能力的定义
在其他的学科中已经有很多与“涌现能力”相关的研究了,不同学科解释的方式和角度也不尽相同。物理学中对“涌现能力”的定义[3]是:
当系统的量变导致行为的质变的现象(Emergence is when quantitative changes in a system result in qualitative changes in behavior)。 对于大规模语言模型的涌现能力,在 Jason Wei 等人的工作中[4]的工作中,给出的定义: 在小模型中没有表现出来,但是在大模型中变现出来的能力"(An ability is emergent if it is not present in smaller models but is present in larger models.)。 涌现能力大概可以分为两种:通过提示就可以激发的涌现能力和使用经过特殊设计的prompt激发出的新的能力。
基于普通提示的涌现能力
通过 prompt 激发大模型能力的方法最早在GPT3[5]的论文中提出提示范式的部分加以介绍:给定一个提示(例如一段自然语言指令),模型能够在不更新参数的情况下给出回复。在此基础上,Brown等在同一篇工作中提出了Few-shot prompt,在提示里加入输入输出实例,然后让模型完成推理过程。这一流程与下游任务规定的输入输出完全相同,完成任务的过程中不存在其他的中间过程。 下图展示了来自不同的工作的对于大模型的在few-shot下测试结果。其中,横坐标为模型训练的预训练规模(FLOPs:floating point operations,浮点运算数。一个模型的训练规模不仅和参数有关,也和数据多少、训练轮数有关,因此用FLOPs综合地表示一个模型的规模);纵轴为下游任务的表现。可以发现,当模型规模在一定范围内时(大多FLOPs在10^22以内),模型的能力并没有随着模型规模的提升而提高;当模型超过一个临界值时,效果会马上提升,而且这种提升和模型的结构并没有明显的关系。 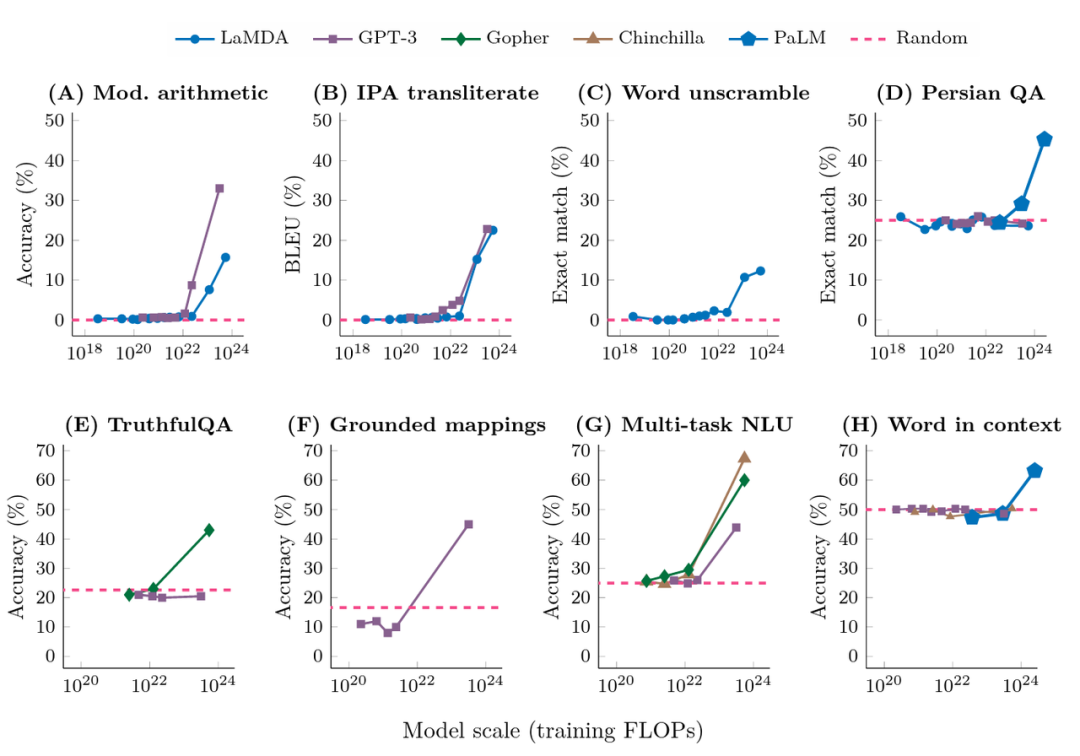
基于增强提示的激发方法
随着对大规模语言模型的研究越来越深入,为大模型添加prompt的方式也越来越多,主要表现出的一个趋势是,相比于普通的 few-shot 模式(只有输入输出)的 prompt 方式,新的方法会让模型在完成任务的过程中拥有更多的中间过程,例如一些典型的方法:思维链(Chain of Thought)[6]、寄存器(Scratchpad)[7]等等,通过细化模型的推理过程,提高模型的下游任务的效果。 下图展示了各种增强提示的方法对于模型的作用效果,具体的任务类型包括数学问题、指令恢复、数值运算和模型校准,横轴为训练规模,纵轴为下游任务的评价方式。与上图类似,在一定的规模以上,模型的能力才随着模型的规模突然提高;在这个阈值以下的现象则不太明显。当然,在这一部分,不同的任务采用的激发方式不同,模型表现出的能力也不尽相同,我们会在下文分类介绍。
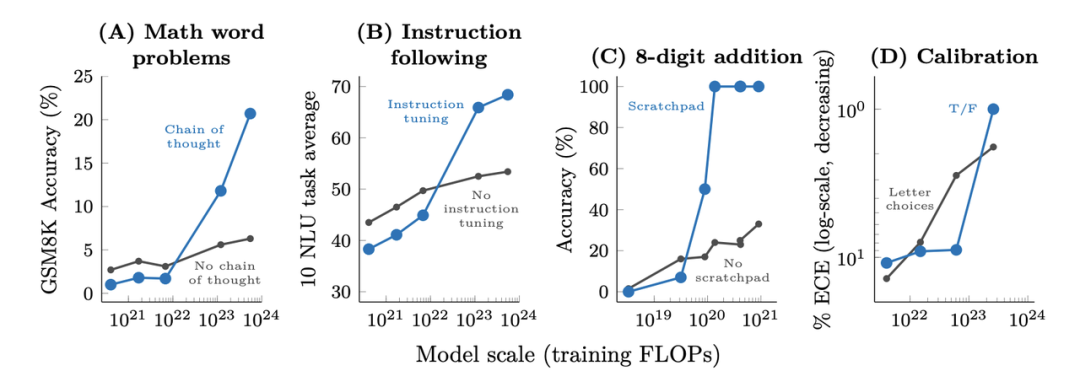
图3:在增强的prompt方式下,一些复杂任务的效果随模型训练的计算量提升而提升
不同的涌现能力的介绍
在这一部分,我们并没有沿用Jason Wei 等人[4]的工作中以使用方法分类的脉络,因为同一种方式激发出的能力可能能应用于多个任务,多种激发方式也可能只是不同程度地提升同种能力;我们采用Yao等人[8]的方式,从能力出发,对不同的方法激发出的能力和激发效果进行总结。
**优秀的上下文学习能力
大规模的语言模型展现出了优秀的上下文学习能力(In-context learning)。这种能力并非大模型专属,但是大模型的足够强大的上下文学习能力是之后各种涌现能力激发的基础。类似于无监督的预测,在上下文学习过程中,不需要对模型进行参数调整,只需要在输入测试样例之前输入少量带有标注的数据,模型就可以预测出测试样例的答案。 有关上下文学习的能力来源仍然有很多讨论。在 Min等人[9]的实验中,分析了上下文学习能力的作用原理。实验表明,上下文学习的过程中,prompt中的ground truth信息并不重要,重要的是prompt中实例的形式,以及输入空间与标签空间是否与测试数据一致。Xie 等人的工作[10]将上下文学习的过程理解为一个贝叶斯推理的过程,在in-context learning的过程中,模型先基于prompt推测concept,然后基于concept和prompt生成output。在对多个样例进行观测的过程中,prompt中的数据会给concept提供“信号”(与预训练过程中的相似之处)和“噪声”(与预训练过程分布差别较大之处),当信号大于噪声时,模型就可以推理成功。
**可观的知识容量
-
在问答和常识推理任务上需要模型具有较好的知识推理能力,在这种情况下,对大型模型进行提示不一定优于精调小型模型。但是大模型拥有更高的标注效率,因为:
-
在许多数据集中,为了获得所需的背景/常识知识,小模型需要一个外部语料库/知识图谱来检索,或者需要通过多任务学习在增强的数据上进行训练
-
对于大型语言模型,可以直接去掉检索器,仅依赖模型的内部知识,且无需精调
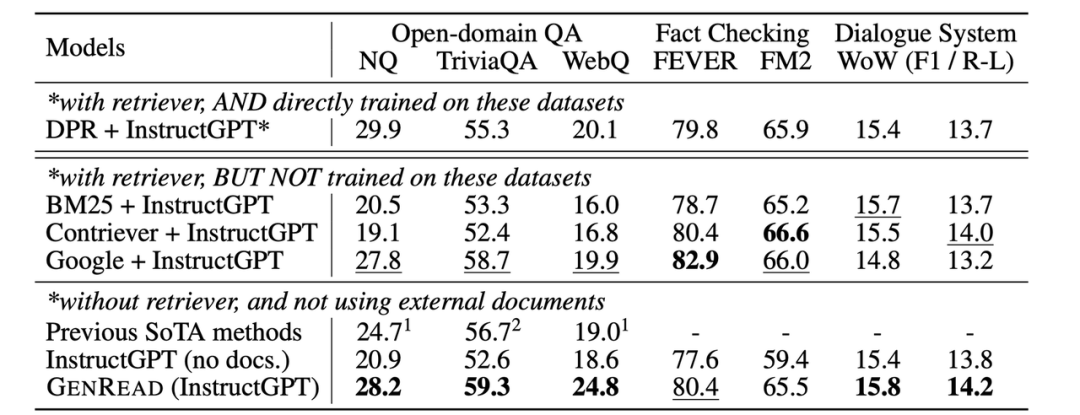
图4:之前的需要外部检索的SOTA和GPT-3的性能对比
上表来自于 Yu等人[11]的工作。如表中所示,虽然在常识/开放域问答任务上GPT-3 并没有明显优于之前的精调模型,但它不需要从外部文档中检索,因为其本身就包含了知识。
为了理解这些结果的重要性,我们可以回顾一下NLP的发展历史:NLP 社区从一开始就面对着如何有效编码知识的挑战。研究者们一直在不断探索如何把知识保存在模型外部或者内部的方法。上世纪九十年代以来,研究者们一直试图将语言和世界的规则记录到一个巨大的图书馆中,将知识存储在模型之外。但这是十分困难的,毕竟我们无法穷举所有规则。因此,研究人员开始构建特定领域的知识库,来存储非结构化文本、半结构化(如维基百科)或完全结构化(如知识图谱)等形式的知识。通常,结构化知识很难构建,但易于推理,非结构化知识易于构建,但很难用于推理。然而,语言模型提供了一种新的方法,可以轻松地从非结构化文本中提取知识,并在不需要预定义模式的情况下有效地根据知识进行推理。下表为优缺点对比:
构建推理结构化知识难构建需要设计体系结构并解析容易推理有用的结构已经定义好了非结构化知识容易构建只存储文本即可难推理需要抽取有用的结构语言模型容易构建在非结构化文本上训练容易推理使用提示词即可
**优秀的泛化性
在 2018 年至 2022 年期间,NLP、CV 和通用机器学习领域有大量关于分布偏移/对抗鲁棒性/组合生成的研究,人们发现当测试集分布与训练分布不同时,模型的行为性能可能会显著下降。然而,在大型语言模型的上下文学习中似乎并非如此。

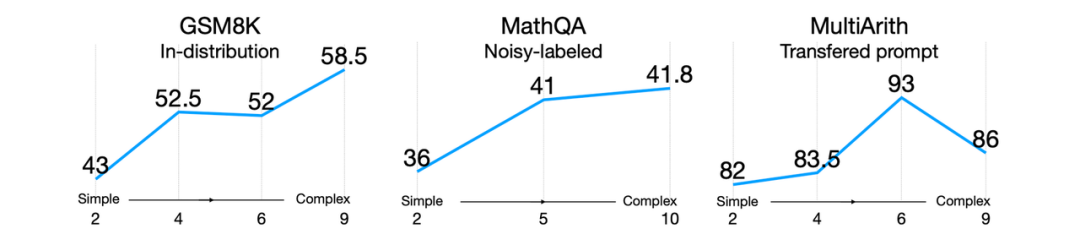
**复杂推理能力
复杂推理能力包含若干方面,如数学推理能力、代码生成、脚本生成等等,以下的介绍我们以数学推理能力为例。数学推理的一个典型的数据集是GSM8K,其由8.5K个人工标注的高质量的小学数学问题组成。数据集的标注内容不仅包含最终结果,还包含得到结果的2~8个推理步骤。
在最开始的GPT3的论文中,对于这个任务的学习方式仍然是微调的方式,得到的结果基本符合缩放定律。作者在论文里得出一个结论:
175B的模型仍然需要两个额外数量级的训练数据才能达到80%的准确率。 但是在之后的工作中,通过其他的方式大大提高了该任务上的结果。Wei等人[6]通过思维链的方式,将540B的PaLM模型上的准确率提高到56.6%,这一过程并没有微调,而是将8个提示示例作为prompt,通过few-shot的方式激发模型的推理能力。在此基础上,Wang等人[14]通过多数投票的方式,将这一准确率提高到74.4%。Yao等人[15]提出Complexity-based Prompting,通过使用更复杂、推理步骤更多的样例作为prompt,进一步提高模型的效果。在此之外,数据集的难度也越来越高:Chung等人[16]将测试范围扩展到高中的各个学科;Minerva[17]的工作将测试范围扩展到大学的各个学科;Jiang等人[18]进一步将测试范围扩展到国际数学奥林匹克问题上。
我们看到,从涌现能力的角度讲,模型在在达到一定规模后,用恰当的方式激发出的性能确实远远超过缩放法则所预测的效果;与此同时,各种方法都是few-shot或zero-shot的方式,需要的数据也更少。现在并没有太多工作能够直接对比在同样的足够大的模型上,微调和prompting的方式的性能差距;但是在下游任务数据集的规模往往远小于模型充足训练所需要的数据规模的情境下,利用prompting激发模型本来的能力确实能够显著提高效果,这也是目前大多数任务面临的情况。
涌现能力是海市蜃楼?
在斯坦福大学最新的工作[19]中指出,大模型的涌现能力来自于其不连续的评价指标,这种不连续的评价指标导致了模型性能在到达一定程度后出现“大幅提升”。如果换成更为平滑的指标,我们会发现相对较小的模型的效果也并非停滞不前,规模在阈值以下的模型,随着规模的提高,生成的内容也在逐渐靠近正确答案。 为了验证这一观点,斯坦福的研究人员做了两组实验,第一组是将NLP中不连续的非线性评价指标转为连续的线性评价指标,结果如下图所示,模型的涌现能力消失了(从图2到下图)。 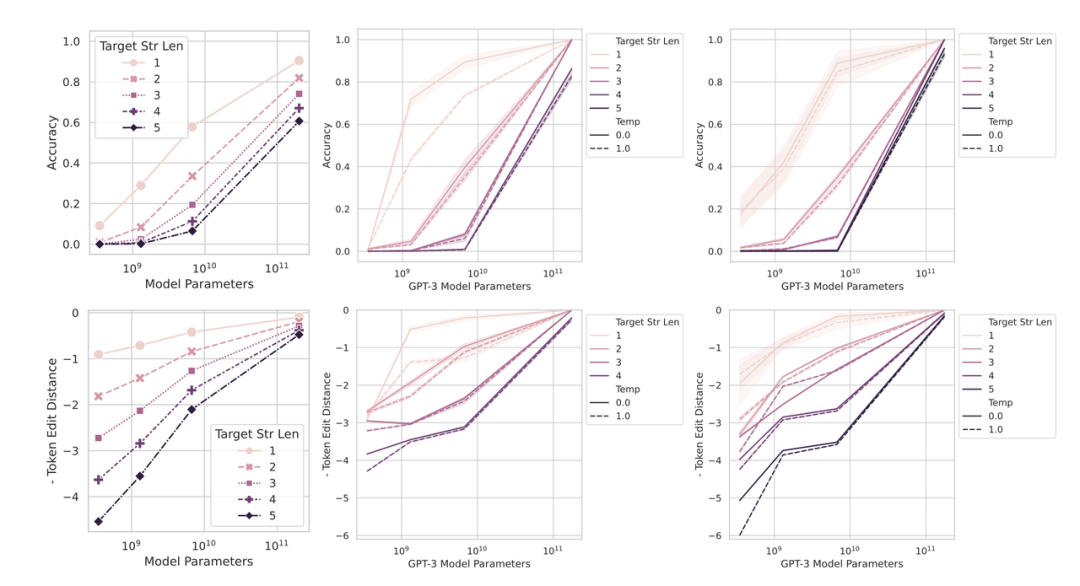
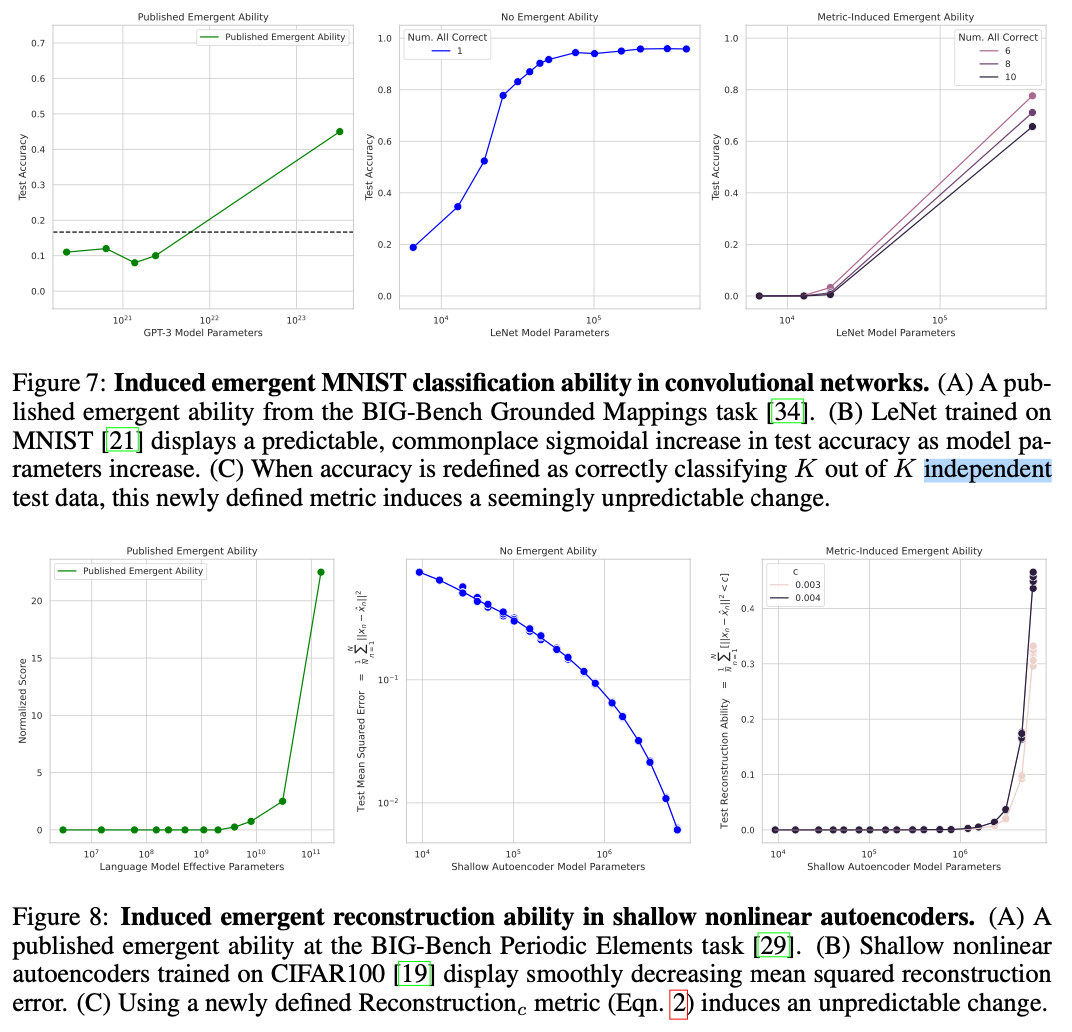
因此LLM中的涌现能力到底是什么,又是如何出现的,依然值得研究者们研究。
结语
本文简要介绍了涌现能力,具体包括涌现能力之前的缩放法则,涌现能力的定义,涌现能力的分类,还简要介绍了不同涌现能力的典型激发方法。当然,归根结底,“涌现能力”只是对一种现象的描述,而并非模型的某种真正的性质,关于其出现原因的研究也越来越多。现有的一些工作认为,模型的涌现能力的出现是和任务的评价目标的平滑程度相关的。在之后的工作中,更好的评级方式,更高的数据质量,更出乎人意料的prompt方式,都可能会更进一步提高模型的效果,并让观测到的效果得到更客观的评价。
参考文献
[1] Kaplan J, McCandlish S, Henighan T, et al. Scaling laws for neural language models[J]. arXiv preprint arXiv:2001.08361, 2020. [2] Cobbe et. al. 2021. Training Verifiers to Solve Math Word Problems. [3] Philip W. Anderson. More is different: Broken symmetry and the nature of the hierarchical structure of science. Science, 177(4047):393–396, 1972. [4] Wei J, Tay Y, Bommasani R, et al. Emergent abilities of large language models[J]. arXiv preprint arXiv:2206.07682, 2022. [5] Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D. Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. Language models are few-shot learners. [6] Wei J, Wang X, Schuurmans D, et al. Chain of thought prompting elicits reasoning in large language models[J]. arXiv preprint arXiv:2201.11903, 2022. [7] Maxwell Nye, Anders Johan Andreassen, Guy Gur-Ari, Henryk Michalewski, Jacob Austin, David Bieber, David Dohan, Aitor Lewkowycz, Maarten Bosma, David Luan, et al. Show your work: Scratchpads for intermediate computation with language models. arXiv preprint arXiv:2112.00114, 2021. [8] Fu, Yao; Peng, Hao and Khot, Tushar. (Dec 2022). How does GPT Obtain its Ability? Tracing Emergent Abilities of Language Models to their Sources. Yao Fu’s Notion [9] Min S, Lyu X, Holtzman A, et al. Rethinking the Role of Demonstrations: What Makes In-Context Learning Work?[J]. arXiv preprint arXiv:2202.12837, 2022. [10] Xie S M, Raghunathan A, Liang P, et al. An explanation of in-context learning as implicit bayesian inference[J]. arXiv preprint arXiv:2111.02080, 2021. [11] Yu W, Iter D, Wang S, et al. Generate rather than retrieve: Large language models are strong context generators[J]. arXiv preprint arXiv:2209.10063, 2022. [12] Si C, Gan Z, Yang Z, et al. Prompting gpt-3 to be reliable[J]. arXiv preprint arXiv:2210.09150, 2022. [13] Fu Y, Peng H, Sabharwal A, et al. Complexity-based prompting for multi-step reasoning[J]. arXiv preprint arXiv:2210.00720, 2022. [14] Wang et. al. 2022. Self-Consistency Improves Chain of Thought Reasoning in Language Models. [15] Fu et. al. 2022. Complexity-Based Prompting for Multi-step Reasoning. [16] Chung et. al. 2022. Scaling Instruction-Finetuned Language Models. [17] Lewkowycz et. al. 2022. Minerva: Solving Quantitative Reasoning Problems with Language Models. [18] Jiang et. Al. 2022. Draft, Sketch, and Prove: Guiding Formal Theorem Provers with Informal Proofs. [19] Schaeffer R, Miranda B, Koyejo S. Are Emergent Abilities of Large Language Models a Mirage?[J]. arXiv preprint arXiv:2304.15004, 2023. 本期责任编辑:张 宇本期编辑:李宝航

