论文浅尝 | 面向跨语言实体对齐的知识图谱与实体描述协同嵌入方法

来源: IJCAI2018
链接: https://www.ijcai.org/proceedings/2018/0556.pdf
动机
近年来,随着多语言知识图谱嵌入(Multilingual KG embedding)的研究,实体的潜在语义表示以及跨语言知识推理等任务均取得一定成效,因此也推动了许多知识驱动的跨语言工作。然而,受限于各语言知识图谱之间较低的实体对齐(Entity alignment)程度,跨语言推理的准确性往往不够令人满意。
考虑到多语言知识图谱中具有对实体的文字性描述,文章提出一种基于嵌入(Embedding)的策略:通过利用图谱中实体的文字描述,对仅包含弱对齐(KG中的inter-language links,ILLs)的多语图谱做半监督的跨语言知识推理。
为了有效利用图谱知识以及实体的文字描述,文章提出通过协同训练(Co-train)两个模块从而构建模型KDCoE:多语言知识嵌入模块;多语言实体描述嵌入模块。
贡献
文章的贡献有:
(1)提出了一种半监督学习方法KDCoE,协同训练了多语知识图谱嵌入和多语实体描述嵌入用于跨语言知识对齐;
(2)证明KDCoE在Zero-shot实体对齐以及跨语言知识图谱补全(Cross-lingual KG Completion)任务上的有效性;
方法
1. 多语言知识图谱嵌入Monolingual KG Embeddings, KGEM
由知识模型(Knowledge Model)和对齐模型(Alignment Model)两个部分构成,分别从不同角度学习结构化知识。
知识模型:用于保留各语言知识嵌入空间中的实体和关系
文章采用了传统的TransE方法构建知识模型,并认为这种方法有利于在跨语言任务重中保持实体表示的统一性,且不会受到不同关系上下文带来的影响。其对应的目标损失函数如下:
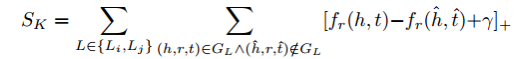
其中,L表示某种语言,(Li,Lj)表示一组语言对,GL 表示语言 L 对应的知识图谱,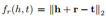
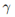
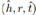
对齐模型:用于在不同语言的嵌入空间中获取跨语言关联
为了将不同语言间的知识关联起来,文章参照MTransE中的线性转换策略,其目标函数如下:
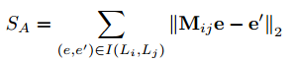
其中(e, e')是一组已知的对齐实体,当知识嵌入向量的维度为 k1 时,Mij 是一个 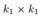
KGEM的目标函数:
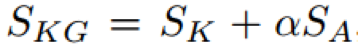
其中,
2. 多语言实体描述嵌入 Multilingual Entity Description Embeddings, DEM
DEM过程包含两个部分:编码和跨语言嵌入
1) 编码:
文章使用 Attentive Gated Recurrent Unit encoder, AGRU 对多语言实体描述进行编码,可以理解为带有 self-attention 的 GRU 循环网络编码器。
文章希望利用self-attention机制使得编码器能够凸显实体描述句子中的关键信息,AGRU中的self-attention可以定义为以下公式:
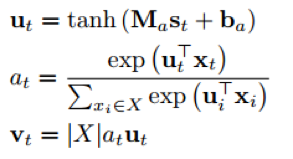
其中,ut 是由 GRU 中 st 产生的隐藏表示,attention 权值 at 则是由一个 softmax 函数计算得到,反映的是单词 xt 对于序列 X 的重要性,而后依据此权重与隐藏表示可以得到 self-attention 的输出 vt,|X|(输入序列的长度)用于防止 vt 失去原有的规模。
在这个部分,作者也尝试了其他的编码框架,包括单层网络,CNN,ALSTM等等,但AGRU取得了最好的性能
2) 跨语言嵌入部分:
为了更好的反映出多语言实体描述的词级别语义信息,文章使用跨语言词嵌入方法用于衡量和找出不同语言间的相似词汇。大致流程可描述如下:
首先,使用跨语言平行语料Europarl V7以及Wikipedia中的单语语料,对cross-lingualBilbowa [Gouws et al., 2015] word embeddings进行预训练。
而后使用上述embeddings将实体描述文本转换为向量序列,再输入进编码器中。
3) DEM学习目标:
文章建立的编码器由两个堆叠的AGRU层构成,用于建模两种语言的实体描述。该编码器将实体描述序列作为输入,而后由第二层输出生成的embedding。
而后,文章引入了一个affine层,将上述各种语言的embedding结果投影到一个通用空间中,其投影过程由以下公式描述:
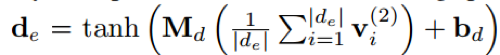
DEM 的目标是最大化各个实体描述 embedding 与对应的其他语言版本之间的 log 相似度,故可以将目标函数描述如下:
3. 迭代 Co-training 的 KDCoE 模型
文章利用 KG 中存在的少量 ILLs 通过迭代的协同过程训练 KGEM 和 DEM 两个模块,过程大致描述如下:
每次迭代中,各模块都进行一系列“训练-生成”的过程:
1) 首先利用已有的ILLs对模型进行训练;
2) 之后利用训练得到的模型从KG中预测得到以前未出现过的新ILLs;
3) 而后将这些结果整合到已有ILLs中,作为下一轮迭代的训练数据;
4) 判断是否满足终止条件:本轮迭代中各模块不再生成新的ILLs
其算法细节描述如下图:

实验
⑴. 实验相关细节
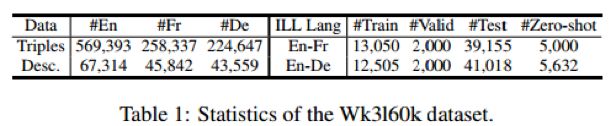
实验数据说明:
文章实验数据来自DBPedia中抽取的子集WK3160k,由英法德三语构成,其中每种语言数据中包含了54k-65k规模的实体
具体统计信息如下表:
文章分别在跨语言实体对齐,Zero-shot对齐以及跨语言知识图谱补全等三个任务上进行实验
其中,跨语言实体对齐选用的基线系统包括:LM,CCA,OT,ITransE以及MTransE的三种策略;
Zero-shot对齐的基线系统为:Single-layer 网络,CNN,GRU,AGRU 的两种策略;
知识图谱补全的基线系统为TransE
⑵. 实验结果
跨语言实体对齐:
如下图所示,文章设置了三组评价指标,分别为:accuracy Hit@1;proportion of ranks no larger than 10 Hit@10;mean reciprocal rank MRR
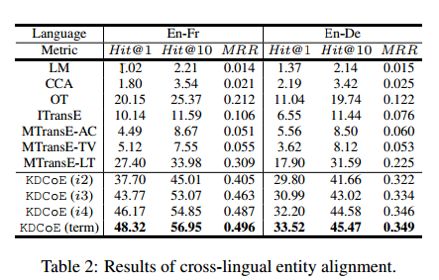
从结果上看,KDCoE模型的性能远优于其他系统,且随着Co-train的迭代次数增加,系统的性能也都有较为明显的提升。
Zero-shot对齐:
Zero-shot采用的评价指标与跨语言实体对齐相同,下图反映了KDCoE在Zero-shot对齐任务中的实验结果:
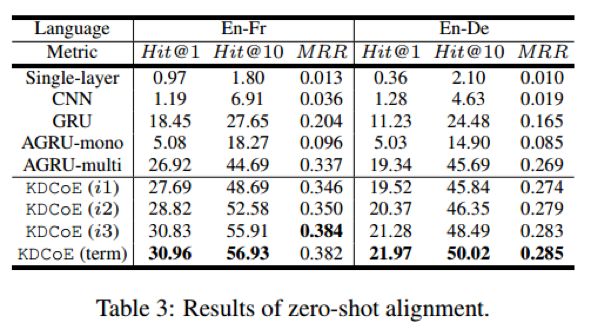
从实验结果上看,KDCoE 的效果依然是随着迭代次数的增加而上升,但从第一次迭代的结果可以发现,其优势的来源基础是 AGRU。这也反映出 AGRU 在编码上相对其他网络模型体现出了更优性能。
跨语言知识补全:
在跨语言知识补全任务中,文章采用proportion of ranks no larger than 10 Hit@10;mean reciprocal rank MRR等两个评价指标
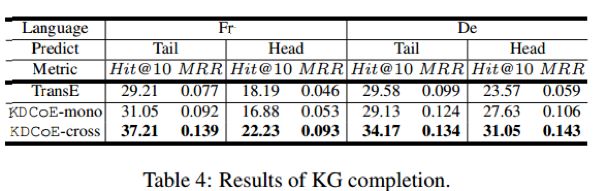
根据 KDCoE-mono 的表现,可以推断,该模型成功继承了 TranE 保持结构化知识中实体和关系的稳定性。而 KDCoE-corss 则反映引入跨语言信息确实对知识补全的效果起到了明显提升。
总结
本文提出了一种基于 embedding 技术的跨语言知识对齐方法,通过引入 Co-train 机制,将 KG 中的关系上下文与实体描述信息有效的利用起来,以现有 KG 中的小规模 ILLs 为基础建立半监督机制,在跨语言实体对齐,知识补全上都起到了明显的效果。
论文笔记整理:谭亦鸣,东南大学博士,研究方向为知识图谱问答、自然语言处理。
OpenKG.CN
中文开放知识图谱(简称OpenKG.CN)旨在促进中文知识图谱数据的开放与互联,促进知识图谱和语义技术的普及和广泛应用。

点击阅读原文,进入 OpenKG 博客。



