
指令调优(IT)领域中的研究工作,这是增强大型语言模型(LLM)能力和可控性的关键技术。来自浙江大学等学者最新的《大模型指令调优》综述,总结了关于 LLM 中指令调优最新工作。
本论文综述了在快速发展的指令调优(IT)领域中的研究工作,这是增强大型语言模型(LLM)能力和可控性的关键技术。指令调优是指以监督方式进一步训练LLM,使用由(指令,输出)成对组成的数据集,从而弥合LLM的下一个词预测目标与用户使LLM遵循人类指令目标之间的差距。
在这项工作中,我们对文献进行了系统的回顾,包括IT的一般方法、IT数据集的构建、IT模型的训练,以及在不同模态、领域和应用中的应用,还分析了影响IT结果的因素(例如,指令输出的生成、指令数据集的大小等)。
我们还回顾了IT的潜在问题,以及对IT的批评,同时指出了现有策略的不足之处,并提出了一些有益研究的方向。

近年来,大型语言模型(LLMs)领域取得了显著进展。诸如GPT-3(Brown et al., 2020b)、PaLM(Chowdhery et al., 2022)和LLaMA(Touvron et al., 2023a)等LLMs在各种自然语言任务中展现出令人印象深刻的能力(Zhao et al., 2021; Wang et al., 2022b, 2023a; Wan et al., 2023; Sun et al., 2023c; Wei et al., 2023; Li et al., 2023a; Gao et al., 2023a; Yao et al., 2023; Yang et al., 2022a; Qian et al., 2022; Lee et al., 2022; Yang et al., 2022b; Gao et al., 2023b; Ning et al., 2023; Liu et al., 2021b; Wiegreffe et al., 2021; Sun et al., 2023b,a; Adlakha et al., 2023; Chen et al., 2023)。
LLMs面临的一个主要问题是训练目标与用户目标之间的不匹配:LLMs通常在大规模语料库上以最小化上下文词预测误差为训练目标,而用户希望模型能"有益且安全地遵循他们的指令"(Radford et al., 2019; Brown et al., 2020a; Fedus et al., 2021; Rae et al., 2021; Thoppilan et al., 2022)。
为了解决这种不匹配,提出了指令调优(IT)作为一种有效的技术,用于增强大型语言模型的能力和可控性。它涉及进一步使用(指令,输出)对来训练LLMs,其中指令表示模型的人类指令,而输出表示遵循指令的期望输出。指令调优的好处有三个:(1)在指令数据集上微调LLMs弥合了LLMs的下一个词预测目标与用户遵循指令目标之间的差距;(2)与标准LLMs相比,指令调优可以实现更可控且更可预测的模型行为。指令有助于约束模型的输出,使其与期望的响应特性或领域知识保持一致,为人类提供介入模型行为的途径;以及(3)指令调优在计算上效率高,可以使LLMs在不需要大规模重新训练或架构更改的情况下快速适应特定领域。
尽管指令调优具有一定的效果,但也存在挑战:(1)制定高质量的指令,以适当覆盖所需的目标行为并非易事:现有的指令数据集通常在数量、多样性和创造性方面存在限制;(2)越来越多的担忧表明指令调优仅在在指令调优训练数据集中受到重点支持的任务上取得了改进(Gudibande等,2023);以及(3)有强烈批评认为指令调优仅捕捉了表面级别的模式和风格(例如,输出格式),而未理解和学习任务本身(Kung和Peng,2023)。提高指令遵循性和处理意料之外的模型响应仍然是开放的研究问题。
这些挑战强调了在该领域进一步进行调查、分析和总结的重要性,以优化微调过程并更好地理解经过指令微调的LLMs的行为。在文献中,越来越多的研究关注于对LLMs进行分析和讨论,包括预训练方法(Zhao等,2023)、推理能力(Huang和Chang,2022)、下游应用(Yang等,2023;Sun等,2023b),但很少涉及LLM指令微调的主题。本调查试图填补这一空白,整理关于这一快速发展领域的最新知识状态。
方法
在本节中,我们描述了在指令调优中使用的一般流程。
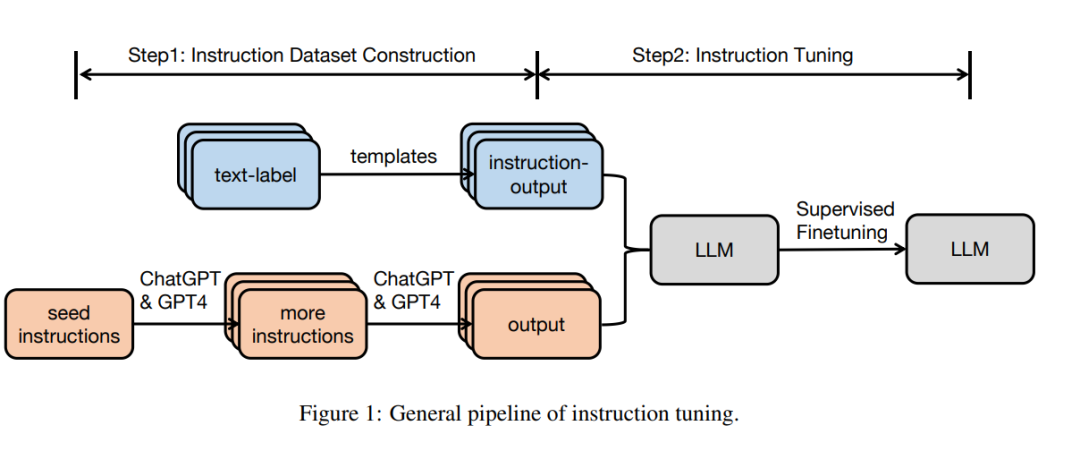
1** 指令数据集构建** 指令数据集中的每个实例由三个元素组成:一个指令,这是一个自然语言文本序列,用于指定任务(例如,写一封感谢信给XX,为XX写一篇关于XX主题的博客等);一个可选的输入,为上下文提供补充信息;以及基于指令和输入的预期输出。通常有两种方法用于构建指令数据集: • 从带注释的自然语言数据集中整合数据。在这种方法中,通过使用模板将文本标签对转换为(指令,输出)对,从现有的带注释的自然语言数据集中收集(指令,输出)对。例如Flan(Longpre等,2023)和P3(Sanh等,2021)数据集是基于数据整合策略构建的。 • 使用LLMs生成输出:一种快速收集给定指令所需输出的替代方法是使用LLMs,如GPT-3.5-Turbo或GPT4,而不是手动收集输出。指令可以来自两个来源:(1)手动收集;或(2)基于使用LLMs扩展的小型手写种子指令。接下来,收集到的指令被输入到LLMs中以获得输出。如InstructWild(Xue等,2023)和Self-Instruct(Wang等,2022c)数据集是按照这种方法生成的。对于多轮会话的指令调优数据集,我们可以让大型语言模型自我扮演不同角色(用户和AI助手),以生成以会话形式的消息(Xu等,2023b)。
** 指令调优**
基于收集的指令调优数据集,可以采用完全监督的方式直接对预训练模型进行微调,其中在给定指令和输入的情况下,模型通过逐个预测输出中的每个令牌来进行训练。
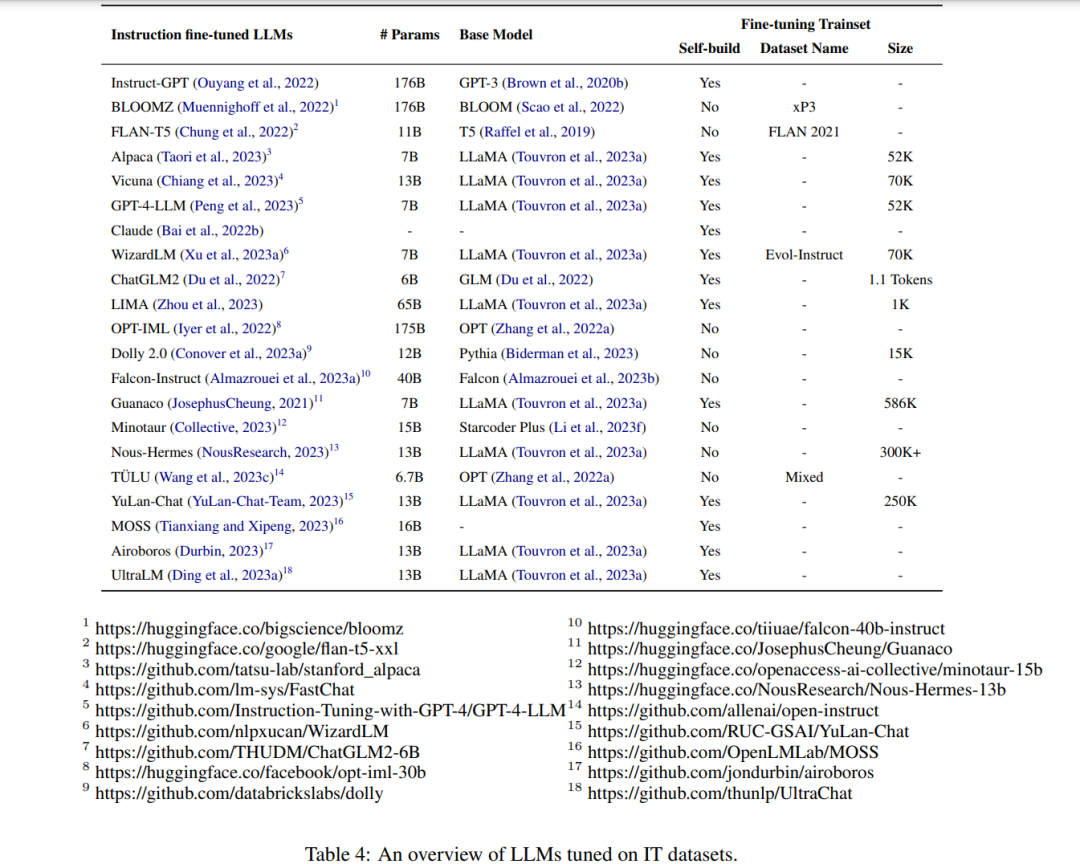
** 指令微调LLM**
多模态指令微调LLM****

高效微调技术
高效微调技术旨在通过多种方式优化少量参数,以使语言模型(LLMs)适应下游任务,包括加法、规范和重新参数化。基于加法的方法引入了额外的可训练参数或模块,这些参数或模块在原始模型中不存在。代表性的方法包括适配器微调(Houlsby等,2019)和基于提示的微调(Schick和Schütze,2021)。基于规范的方法在冻结其他参数的同时,指定了某些固有模型参数进行微调。例如,BitFit(Zaken等,2022)微调了预训练模型的偏置项。重新参数化方法将模型权重转换为更具参数效率的形式进行微调。关键假设是模型自适应是低秩的,因此可以将权重重新参数化为低秩因子或低维子空间(例如LoRA(Hu等,2021))。内在提示微调找到了在不同任务之间调整提示时共享的低维子空间。
结论
本文综述了快速发展的指令调优领域的最新进展。对IT的一般方法论、IT数据集的构建、IT模型的训练、IT在不同模态、领域和应用中的应用进行了系统的回顾。还回顾了对IT模型的分析,以发现它们的优点和潜在的缺陷。我们希望这项工作将作为一种刺激,激励进一步努力解决当前IT模型的不足。