大模型如何和用户建模结合?看这篇综述论文

用户建模(UM)旨在从用户数据中发现模式或学习表征,了解特定用户的特征,如个人资料、偏好和个性。用户模型使得在许多在线应用程序中实现个性化和可疑性检测成为可能,例如推荐、教育和医疗健康。常见的两种用户数据类型是文本和图表,因为数据通常包含大量用户生成内容(UGC)和在线互动。文本和图表挖掘的研究正在迅速发展,在过去二十年中贡献了许多值得注意的解决方案。最近,大型语言模型(LLMs)在生成、理解甚至推理文本数据方面显示出卓越的性能。用户建模的方法已经配备了LLMs,并很快变得突出。本文总结了现有研究关于如何以及为什么LLMs是建模和理解UGC的强大工具。然后,它回顾了几类整合了LLMs和基于文本及图表的方法的用户建模大型语言模型(LLM-UM)方法。接着,它介绍了针对各种UM应用的具体LLM-UM技术。最后,它展示了LLM-UM研究中剩余的挑战和未来方向。我们在以下网址维护阅读清单:https://github.com/TamSiuhin/LLM-UM-Reading。

用户建模(UM)旨在从用户行为中提取有价值的见解和模式,使系统能够定制和适应特定用户的需求[124]。UM技术有助于更好地理解用户行为、定制智能辅助,并极大地改善用户体验。例如,当人们在网上寻找晚餐选项并进行搜索时,UM技术会根据互动历史推断他们的特征,预测当前的食物兴趣,并提供个性化推荐。UM在用户数据分析和许多应用程序中都有重大影响,例如电子商务[191, 194, 280]、娱乐[11, 33, 155]和社交网络[1, 2, 212]。UM是一个高度活跃和有影响力的研究领域。用户建模主要是挖掘和学习用户数据,包括用户生成的内容(UGC)和用户与其他用户及物品的互动。用户生成的内容涵盖了广泛的文本数据,如推文、评论、博客和学术论文。丰富的文本可以通过自然语言处理(NLP)技术进行分析。另一方面,用户互动涉及各种行为,如关注、分享、评级、评论和转推。这些互动可能形成一个异构的时间文本属性图[199],因为它具有时间和文本信息,并且具有不同类型的节点和关系。可以使用图挖掘和学习技术对其进行分析。因此,用户建模已分化为基于文本和基于图表的方法,分别专注于从文本和图表数据中提取洞察。基于文本的UM研究如何发展?研究人员使用了多种类型的文本表示,如单词、主题和嵌入。词袋(BoW)模型使用离散词汇创建分布式文本表示,并包含单词频率[67]。为了解决BoW表示的稀疏性,主题建模技术统计发现文档集中的潜在主题,例如潜在狄利克雷分配(LDA)[15]。但它们无法捕捉语义意义,即单词语义相似性。Word2Vec采用非线性神经层开发连续词袋(CBOW)和连续跳跃-gram模型[148]。它从多种类型的UGC文本数据中提取语义嵌入,如博客、评论和推文。然而,神经层太浅,无法捕捉大量单词标记之间的深层序列模式。随着Transformer架构[219]的突破,预训练语言模型(PLMs)显著改变了UGC理解的格局,采用了预训练-微调范式。新范式在大型未标注语料库上训练模型,使用自监着学习,并使用数百或数千个示例微调模型以适应下游任务[102]。最近,大型语言模型(LLMs)在这一领域引发了革命,展现了包括前所未有的推理[241, 256]、泛化[181, 239]和知识理解[163, 205]等新兴能力。
LLMs在极大规模的语料库上进行预训练,更新数十亿参数。大量研究表明,LLMs可以以零样本方式理解UGC,即不需要微调的示例集合。LLMs在摘要[176]方面超越了人类表现,在几个考试中表现优于大多数人类[159],并展示了强大的推理能力,包括提示工程,如思维链[241]、最少到最多[290]和思维树[256]。LLMs为UM研究开启了一个新时代,重新思考UGC挖掘。基于图表的UM研究如何发展?用户与在线内容和用户的互动自然定义为连接用户或事物节点的边。用户数据可以定义为图表。异构图包含多种类型的节点(例如,用户、物品、地点)和关系。时间/加权图在互动上有时间戳/权重标记。属性图允许节点具有一组属性-值对(例如,用户的年龄,产品的颜色)。在文本丰富的图中,节点具有长形文本属性。随机游走重启提供加权图中两个节点之间的亲近度得分,它已在许多设置中成功使用(例如,个性化PageRank[162])。矩阵分解(MF)将用户-物品互动矩阵分解为两个矩阵的乘积,或称为用户和物品的潜在特征[91, 94, 107]。关于协同过滤,MF在明确反馈评级方面表现更好,而RWR利用物品的全球普及性。它实际上是一个基本的嵌入模型[272]。随着深度学习的发展,Node2Vec通过随机游走从图中提取序列,并使用Word2Vec学习节点嵌入[65]。然而,将图编码为序列会导致信息丢失。图神经网络(GNNs)采用消息传递机制对图进行深度表征学习。特别是,图卷积网络(GCN)[105]的家族极大地改善了推荐[49, 69]、用户档案建立[24, 250]、用户行为预测[224, 263]和可疑用户检测[54, 55]的性能。**为什么LLMs正在革新基于文本和图表的UM研究?**用户建模涉及文本和图表数据上的一系列机器学习任务,如文本分类、节点分类、链接预测和时间序列建模。放入上下文中,任务可以是情感分析、自然语言推理(NLI)、用户和产品分类、社交关系预测和时间行为预测。传统上,解决方案必须是针对特定类型数据的特定模型,并在特定注释集上进行训练。例如,由于模式差异,情感分析和NLI任务必须分别训练两个文本分类器。同样,图神经网络(GNN)中的两个网络或至少两个模块被训练来分别预测用户是否交到新朋友和购买物品。此外,由于长尾分布,用户和/或产品档案的文本信息对于学习和预测非常有限。
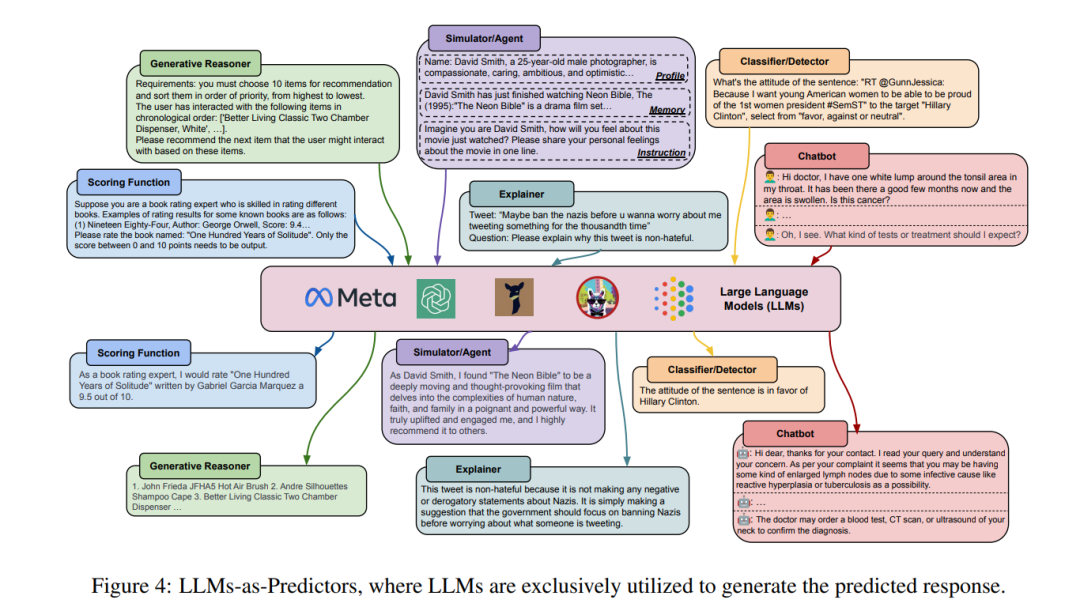
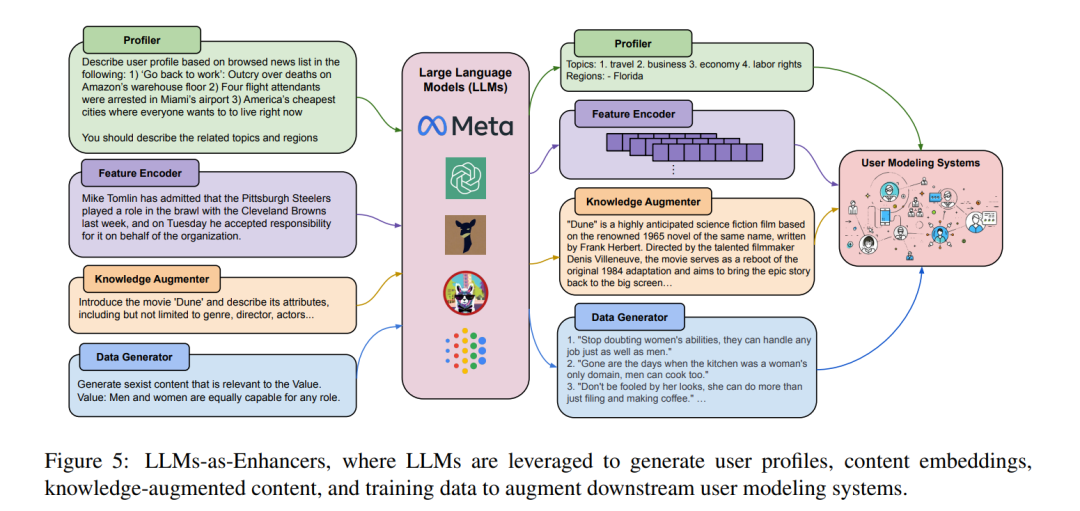
大型语言模型(LLMs)改变了解决方案开发的范式。首先,如果设计得当,提示能够将大型语言模型中的大多数文本到标签的任务处理为统一的文本生成任务;这样就不急切需要注释数据;而且性能甚至可以与传统模型相媲美或更好。这是因为大型语言模型在极大的语料库上进行了预训练,并微调以遵循提示中的指令。其次,提示可以为图数据上的学习任务而设计。例如,可以问大型语言模型“如果一个用户昨天买了苹果手表,他会考虑购买一双跑鞋吗?”大型语言模型的“分析”可以为现有的用户-商品链接预测器提供额外信息。第三,所有文本信息都可以由大型语言模型自动扩展。相关的参数化知识增强了机器学习模型的输入,降低了任务难度。大型语言模型在表征用户个性[184]、辨别用户立场[271]、确定用户偏好[52]等方面展现出了强大的能力。同时,它们在节点分类[259]、节点属性预测[70]和图推理[226]方面也表现出了显著的熟练程度。初步研究聚焦于利用大型语言模型进行用户建模(LLM-UM),以整合基于文本和基于图的方法。对于用户画像,GENRE [135] 利用ChatGPT作为用户画像工具,通过输入用户的行为历史,并提示模型推断用户偏好的主题和地区。这些由大型语言模型生成的画像作为点击率推荐模型的重要特征,解决了在收集用户画像中的匿名问题。在推荐方面,Kang等[100]使用大型语言模型预测用户基于其行为历史的评分,并发现大型语言模型通常需要较少的数据,同时保持了关于人类和物品的世界知识。在个性化方面,LaMP[189]提出了一个基准,包括个性化文本生成和分类任务,以及检索增强方法。大型语言模型可以作为个性化工具,因为它们理解用户数据。在可疑性检测方面,Chiu等[29]使用GPT-3来检测仇恨言论,发现大型语言模型能够在有限的标签下识别滥用语言。
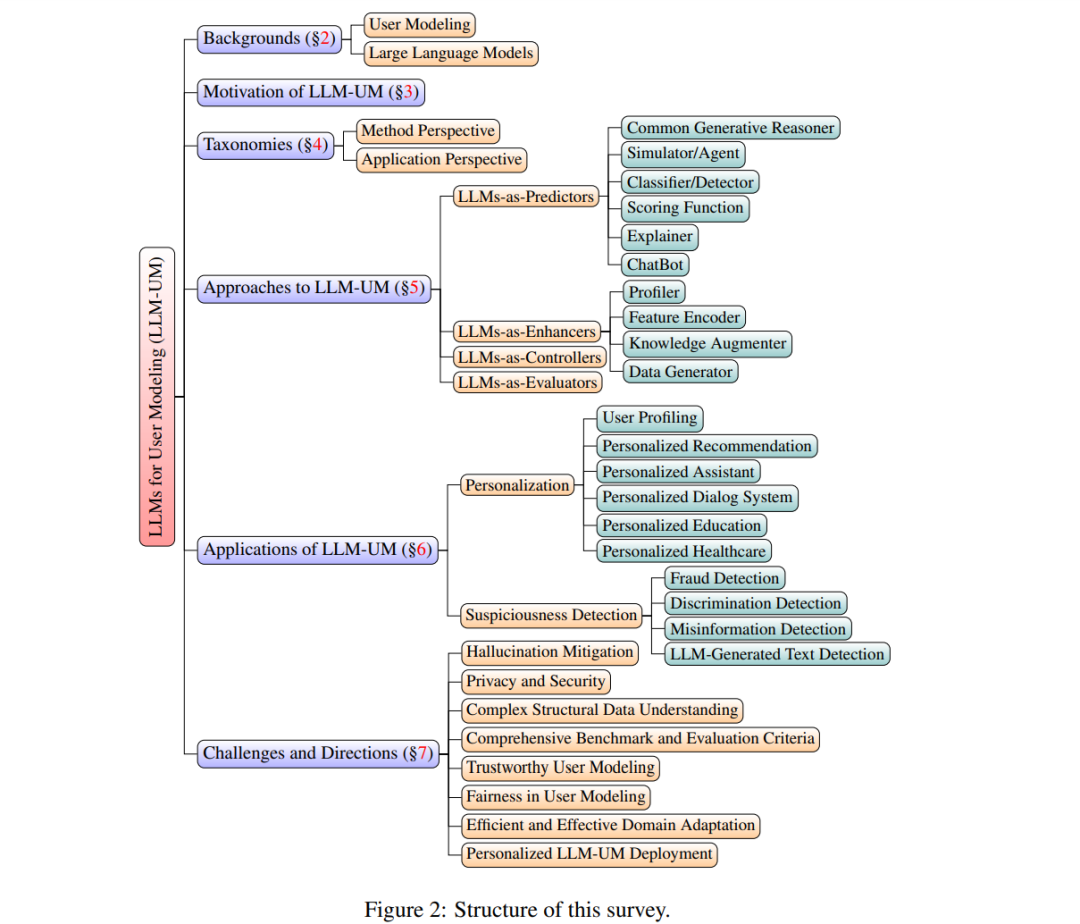
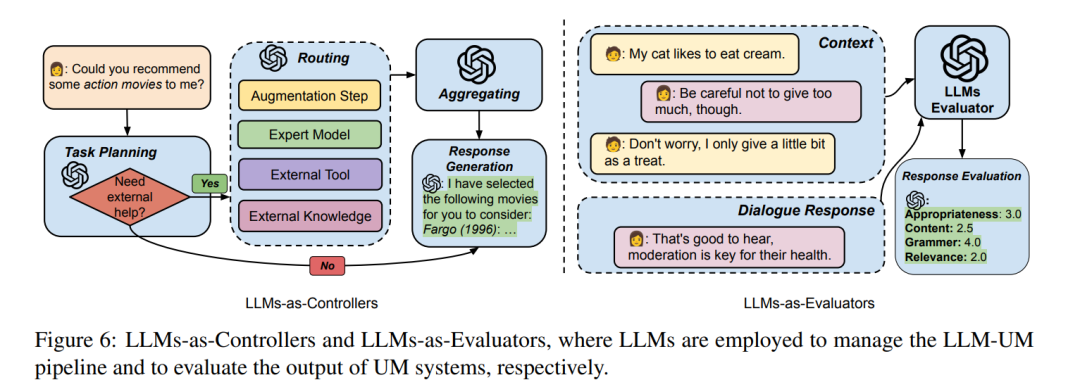
本综述的剩余部分安排如下(见图2)。第2节介绍用户建模技术和大型语言模型的背景,并阐述了为什么LLMs是下一代用户建模的好工具。第4节根据它们的方法和应用,介绍了LLM-UM的两种分类。第5节总结了LLM-UM的方法,以及LLMs如何在现有工作中整合文本和基于图的方法,包括利用LLMs作为增强器、预测器和控制器。第6节详细讨论了LLM-UM的应用,包括个性化和可疑性检测。最后,第7节深入探讨了LLM-UM主题的当前挑战和未来方向。LLM用户建模鉴于大型语言模型(LLMs)在生成[282]、推理[241]、知识理解[205]方面的强大能力,以及对用户生成内容(UGC)的良好理解,如第3节所述,LLMs可以用来增强用户建模(UM)系统。基于LLMs在其中扮演的角色,LLM-UM方法通常可以分为三类,第一类将LLMs视为唯一的预测器,直接生成预测结果;第二类使用LLMs作为增强器,探索更多信息以增强UM系统;第三类赋予LLMs控制UM方法流程的能力,自动化UM过程;最后一类将LLMs用作评估器,评估系统的性能。值得一提的是,在LLM-UM中的“用户模型”形式与之前的定义保持一致,涵盖了借助用户生成内容以及用户-用户/物品交互网络[71]发现的知识和模式。LLM-UM与以前的范式的区别在于方法,其中LLM-UM被LLMs赋能或增强,以获得与用户相关的知识。在以下小节中,我们总结了每种范式,并介绍了代表性的方法。
结论
我们的工作提供了一份全面而结构化的关于大型语言模型在用户建模(LLM-UM)方面的综述。我们展示了为什么LLMs是进行用户建模和理解用户生成内容(UGC)及用户互动的绝佳工具。接着,我们回顾了现有的LLM-UM研究工作,并对它们整合基于文本和基于图的用户建模技术的方法进行了分类,包括LLMs作为增强器、预测器、控制器和评估器的角色。接下来,我们根据它们的应用对现有的LLM-UM技术进行分类。最后,我们概述了LLM-UM领域中剩余的挑战和未来的发展方向。这份综述可作为LLM-UM研究者和从业者的手册,用于研究和使用LLMs来增强用户建模系统,并激发对这个主题的额外兴趣和工作。