

分布外检测(Out-of-distribution,OOD)旨在检测超出训练类别空间的测试样本,这是构建可靠机器学习系统的重要组成部分。现有的关于OOD检测的综述主要聚焦于方法分类,通过对各种方法进行分类来考察该领域。然而,许多最新研究集中在非传统的OOD检测场景,如测试时自适应、多模态数据源和其他新颖背景。在本次综述中,我们首次从问题场景的角度独特地回顾了OOD检测的最新进展。根据训练过程是否完全可控,我们将OOD检测方法分为训练驱动和与训练无关的两类。此外,考虑到预训练模型的快速发展,基于大型预训练模型的OOD检测也被视为一个重要类别,并单独讨论。此外,我们还讨论了评估场景、多种应用以及若干未来的研究方向。我们相信,本综述通过全新的分类法将有助于提出新的方法并扩展更多实际场景的应用。相关论文的精选列表可在GitHub仓库中获取:https://github.com/shuolucs/Awesome-Out-Of-Distribution-Detection
1 引言
机器学习方法[1]在封闭世界假设下取得了显著进展,该假设指的是测试数据与训练集来自相同的分布,称为“同分布”(In-Distribution,ID)。然而,在现实世界中,模型不可避免地会遇到不属于任何训练集类别的测试样本,通常被称为分布外(Out-of-Distribution,OOD)数据。OOD检测[2]旨在识别和拒绝OOD样本,而不是对其做出过度自信的预测[3],同时保持对ID数据的准确分类。具备优秀OOD检测能力的模型更加可靠,并且在众多安全关键场景中具有重要应用。例如,在医疗诊断系统中,一个无法检测到OOD样本的模型可能会对未知疾病作出错误判断,导致严重的误诊[4]。同样,自动驾驶算法[5]应该检测到未知场景,并转交给人类控制,以避免由于任意判断导致的事故。
值得注意的是,近年来已有多项研究致力于综述和总结OOD检测。Yang等人[6]讨论了OOD检测与多个相似话题,并将现有工作分类为基于分类、基于密度、基于距离和基于重建的方法。Cui和Wang[7]从方法论角度对OOD检测进行了综述,但使用了不同的分类标准,包括监督、半监督和无监督方法。此外,Lang等人[8]对自然语言处理中的OOD检测方法进行了回顾。然而,之前的工作过多地关注于从方法角度的讨论,缺乏从任务场景角度的深入探讨。建立明确的任务场景分类能够增强对该领域的全面理解,并帮助从业者选择合适的方法。此外,鉴于近期新范式(例如测试时学习范式[9])和基于大型预训练模型[10]的方法的引入,迫切需要一个整合最新技术的综述。
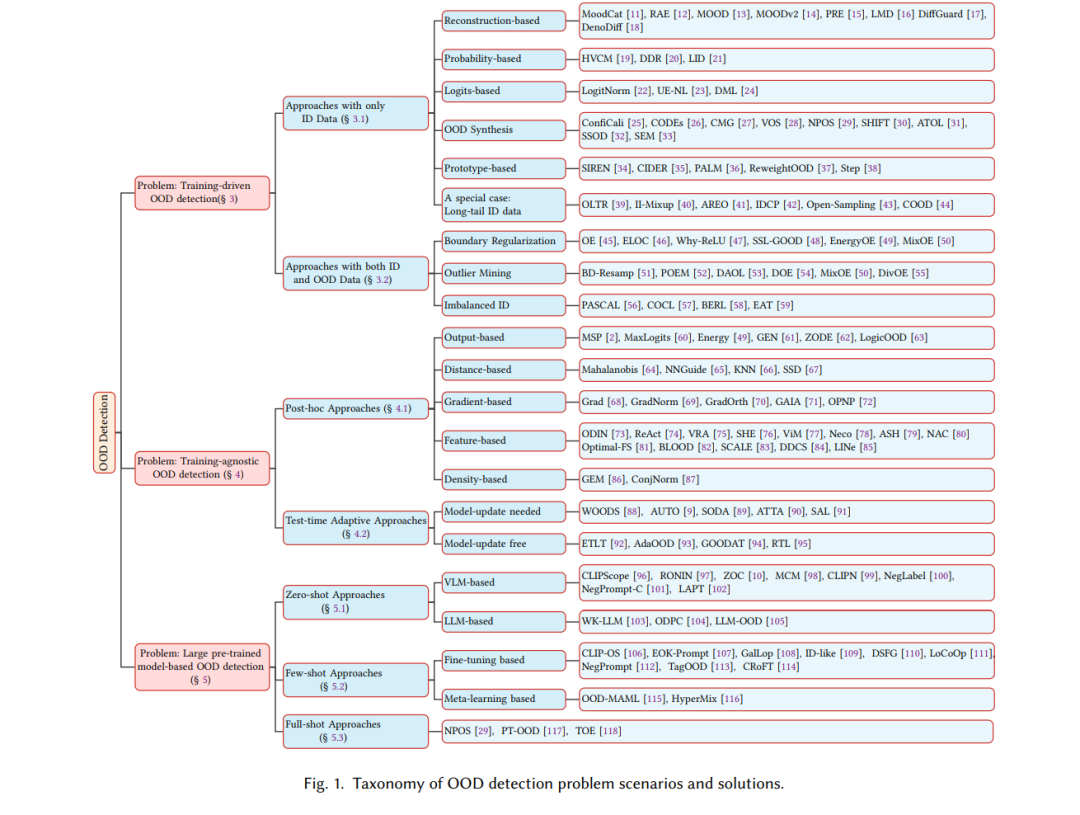
在本次综述中,我们首次以问题为导向的分类法回顾了OOD检测的最新进展,如图1所示。根据方法是否需要控制预训练过程,我们将OOD检测算法分为训练驱动型和训练无关型方法。考虑到当前大型预训练模型的快速发展,我们还将基于大型预训练模型的OOD检测作为一个单独的部分进行讨论。具体来说,训练驱动型方法通过设计训练阶段的优化过程实现高效的检测能力。根据训练过程中是否使用OOD数据,这些方法被进一步分类和讨论。训练无关型方法基于一个已训练好的模型来区分OOD数据和ID数据,避免了实际中耗时且昂贵的预训练过程。根据是否利用测试样本进一步提高OOD检测性能,我们将其分类为事后方法和测试时方法。基于大型预训练模型的OOD检测方法关注于如视觉语言模型或大型语言模型等模型,这些模型在大量数据集上预训练,擅长完成多种任务。我们从是否使用少量样本的角度对其进行讨论,包括零样本、少样本和全样本场景。
本次综述的其余部分组织如下。我们将在第2节回顾与OOD检测相关的工作。接下来,我们在第3节总结了训练驱动型的OOD检测方法,并在第4节介绍了训练无关的OOD检测方法。然后在第5节,我们介绍了基于大型预训练模型的OOD检测。第6节提供了评估指标、实验协议和应用的概述。随后,我们在第7节讨论了有前景的趋势和尚未探索的挑战,以期为潜在的关键研究方向提供启发。最后,我们在第8节总结了本次综述。
问题:训练驱动的OOD检测
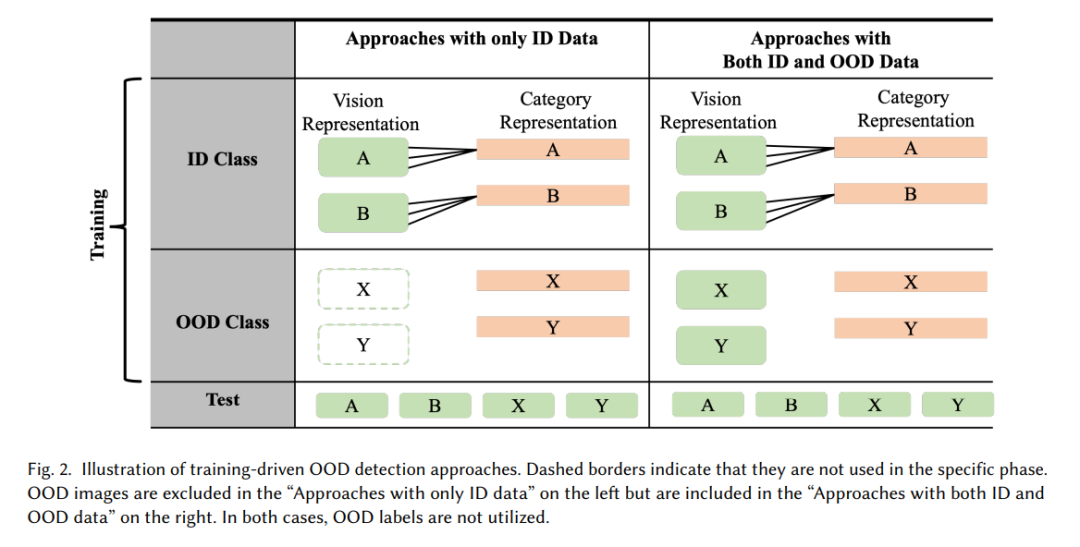
在训练驱动的OOD检测问题中,研究人员设计预训练过程,以获得具备优越OOD检测能力的模型。根据训练过程中是否可以访问OOD数据,我们将这一场景下的方法进一步分为两类:仅使用ID数据进行训练,以及同时使用ID和OOD数据进行训练,如图2所示。
问题:训练无关的OOD检测
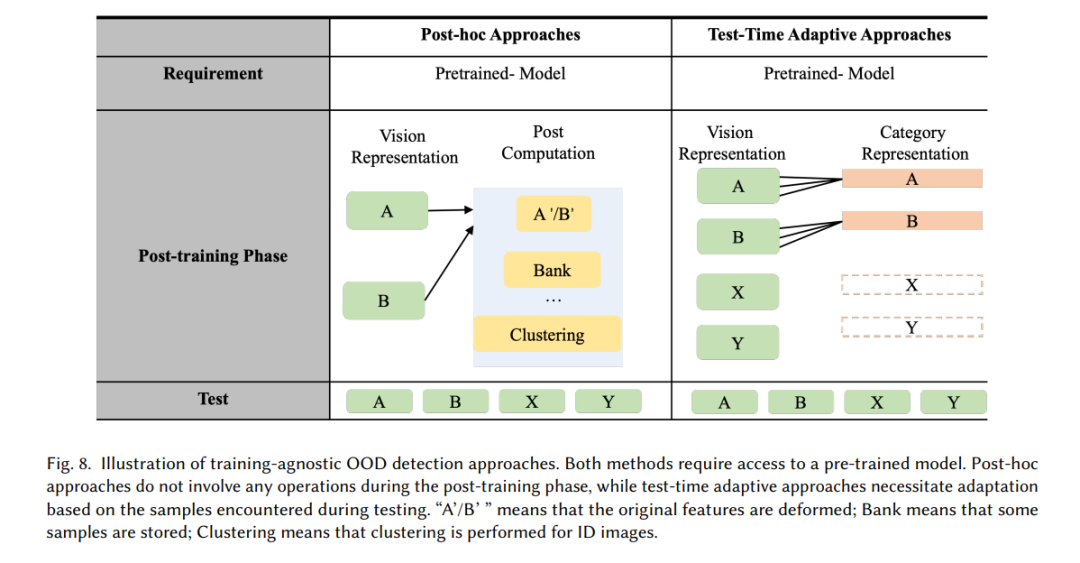
训练无关的OOD检测主要强调测试时的适应策略,而不是像训练驱动的OOD检测那样注重分类器性能。根据是否依赖测试数据之间的相关性,这类方法被分为两类:事后方法和测试时自适应方法,如图8所示。事后方法独立计算每个样本的结果,不受其他样本变化的影响。相反,测试时自适应方法在测试样本之间表现出依赖性。**
**
问题:基于大型预训练模型的OOD检测
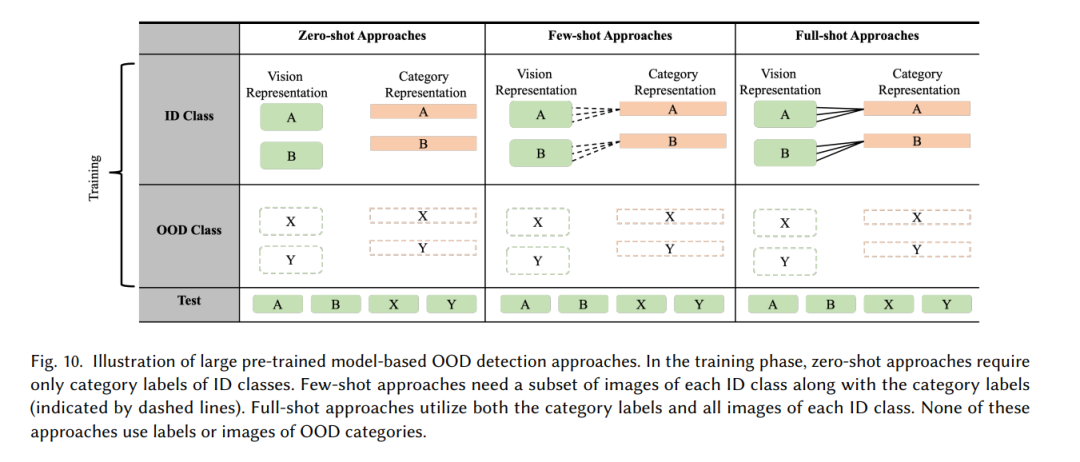
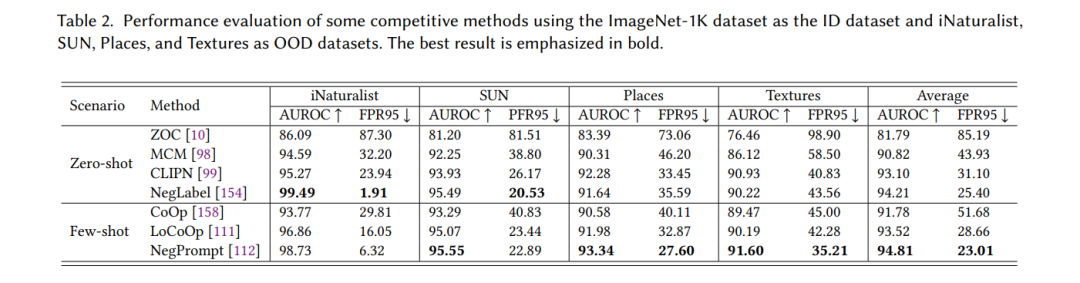
大型预训练模型在众多下游同分布(ID)分类任务中展示了卓越的性能,但它们在OOD检测任务中的潜力尚未被广泛探索。近期的研究[145]指出,较高的ID分类准确率与更好的OOD检测性能之间存在关联。因此,基于大型预训练模型的OOD检测问题应运而生。近年来,各种类型的大型预训练模型,包括单模态模型(如ViT [146]、BERT [147]、Diffusion [148]),视觉语言模型(VLMs)(如CLIP [149]、多模态Diffusion [150]、ALIGN [151]),以及大型语言模型(LLMs)(如GPT-3 [152]),逐渐被应用于OOD检测任务,如图9所示。利用大型预训练模型强大的表征能力,进一步放宽了OOD检测任务的限制,推动了更具挑战性和现实性的场景成为研究热点。根据大型预训练模型接触到的ID样本数量,基于大型预训练模型的OOD检测可以分为零样本、少样本和全样本OOD检测,如图10所示。表2总结了几种相关竞争方法的性能评估,以提供该领域OOD检测性能水平的理解。**
**
结论
OOD检测对于可信赖的机器学习至关重要。在本文中,我们首次从问题场景的角度,全面回顾了OOD检测的最新进展,重点介绍了训练驱动、训练无关和基于大型预训练模型的OOD检测。我们还总结了广泛使用的评估指标、实验协议和多样化的应用场景。我们相信,本文对现有论文的新分类法以及对新兴趋势的深入讨论,将有助于更好地理解当前的研究现状,帮助从业者选择合适的方法,并激发新的研究热点。