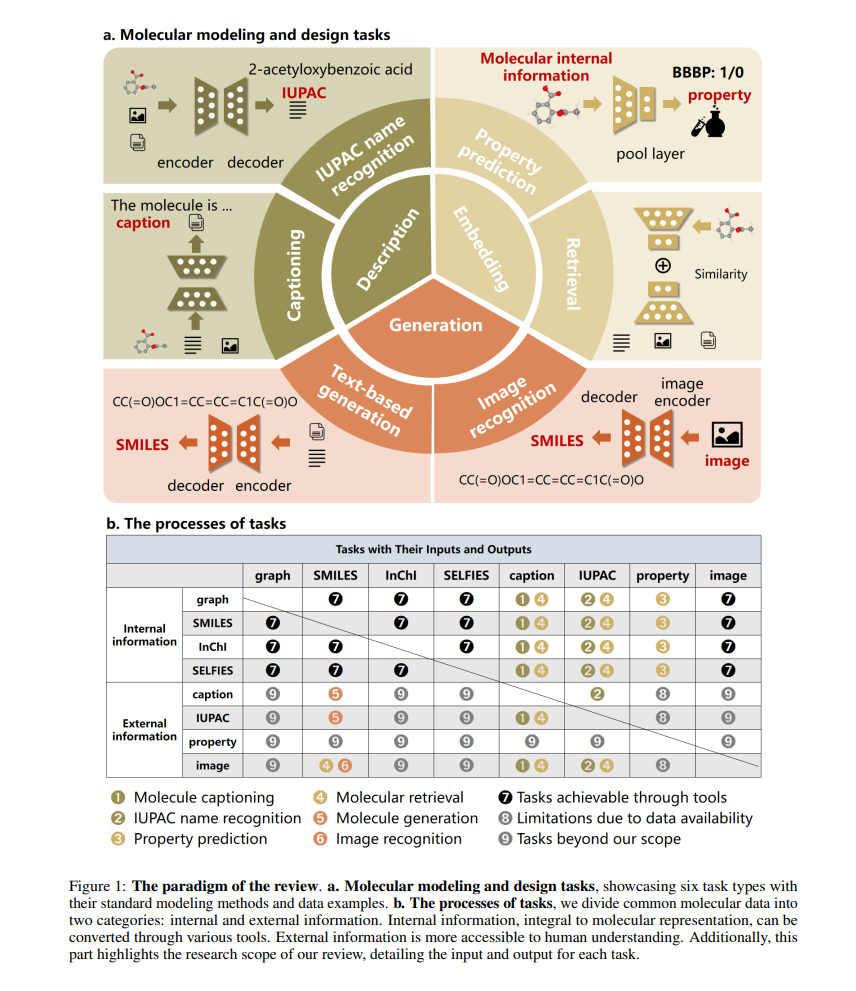
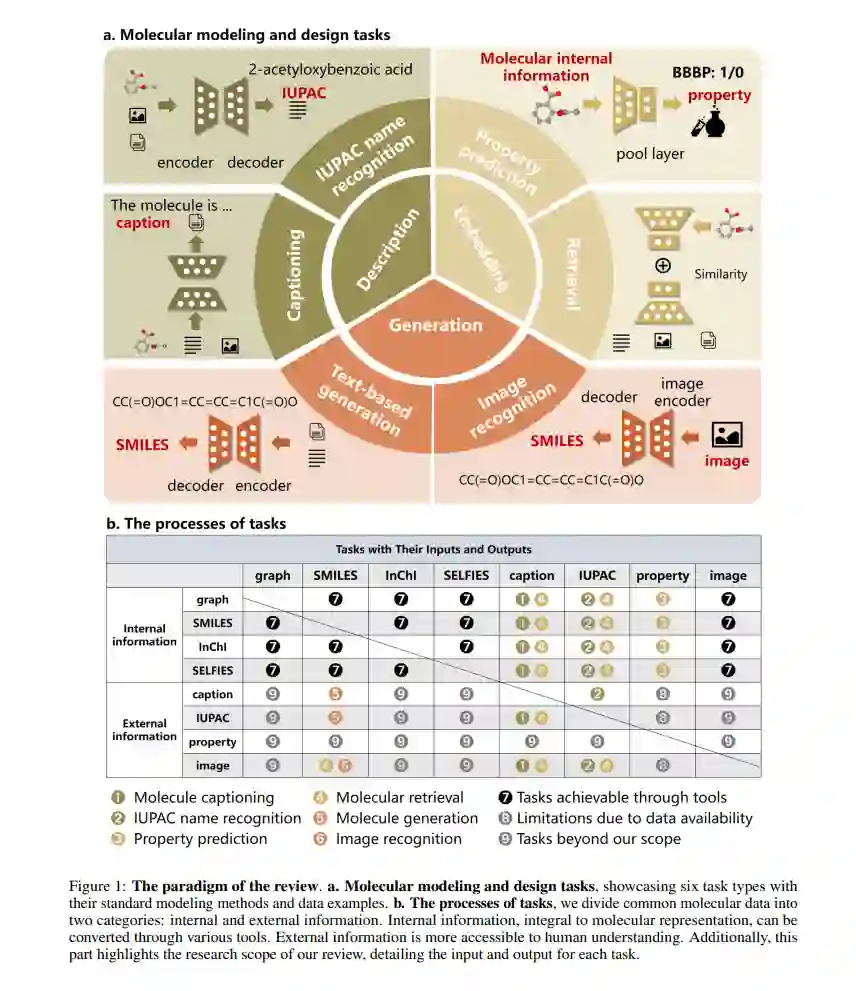
高效的分子建模和设计对于新分子的发现和探索至关重要,深度学习方法的引入已经彻底改革了这一领域。特别是,大型语言模型(LLMs)提供了一种全新的方法来从自然语言处理(NLP)的角度解决科学问题,引入了一种称为科学语言建模(SLM)的研究范式。然而,仍有两个关键问题:如何量化模型与数据模态之间的匹配度以及如何识别模型的知识学习偏好。为了应对这些挑战,我们提出了一个多模态基准,命名为ChEBI-20-MM,并进行了1263次实验来评估模型与数据模态和知识获取的兼容性。通过模态转换概率矩阵,我们提供了关于任务最适合的模态的见解。此外,我们引入了一种统计上可解释的方法,通过局部特征过滤发现特定上下文的知识映射。我们的先驱性分析提供了对学习机制的探索,并为推进分子科学中的SLM铺平了道路。 Transformers[8]以其强大的文本编码和生成能力提供了优势。这些模型可以通过最小的任务特定调整进行微调,使它们在分子建模和设计中更加多才多艺和高效。此外,自从ChatGPT[9]和GPT-4[10]的出现以来,大型语言模型(LLMs)已成为尤其在分子科学中的一种突破性趋势。LLMs凭借其在处理和生成类人文本的先进能力,提出了一个理解和设计分子结构的新范式。它们吸收和分析大量文本数据的能力可以提供前所未有的洞察,克服了传统AI方法的一些限制。这种新能力结合了准确性和新颖性,以改善结果,被称为化学知识。其有效性取决于输入数据、模型架构和训练策略等因素。然而,对这一能力的当前综述和基准评估并不全面。 分子科学中现有的综述,如分子生成综述[11],通常缺乏全面的模型比较,并且任务范围有限。知识驱动的综述[12]对分子学习进行了分类,但缺少详细的方法比较和数据集讨论。而最近的基准测试,如测试ChatGPT的[13],涵盖了八个化学任务,每个任务都提供了独特的化学洞察。Mol-Instructions[14]提供了一个用于微调的数据集,包含各种分子和蛋白质指令,增强了LLMs中的生物分子理解。然而,这些综述和基准测试缺乏多模态内容,也没有充分探索模型的化学知识。 总结来说,本研究全面回顾了Transformers和LLMs在分子建模与设计中的应用。我们将六个常见的分子任务分类为三个不同的目标:描述、嵌入和生成,如图1所生动描绘。此外,我们建立了一个统一的多模态基准ChEBI-20-MM,并进行实验评估数据模态、模型架构和不同任务类型的兼容性,考察它们对任务性能的影响。此外,我们的端到端可视化方法展示了嵌入化学知识的建模洞察的发现。总体来说,我们的主要贡献包括: • 本工作分析了LLMs在分子建模中的应用,分类现有模型,并提出了一个多模态基准(ChEBI-20-MM)进行性能评估,支持1263次实验。 • 我们分析了模态转换概率矩阵,并确定了不同数据模态和模型架构之间的最佳匹配。 • 我们引入了一种统计上可解释的方法,通过局部特征过滤展示了知识获取。 本文的其余部分如下组织。第2节介绍相关定义和背景。然后,我们探讨分子建模和设计中的六个关键任务。第3节展示了我们的基准测试和洞察。第4节讨论了关键结果和限制,第5节总结了我们的贡献和未来研究方向。