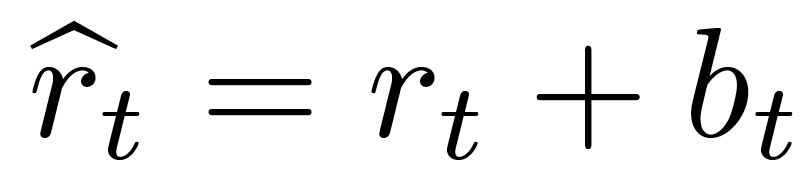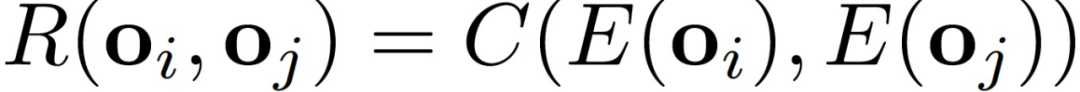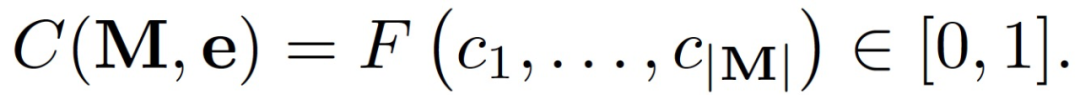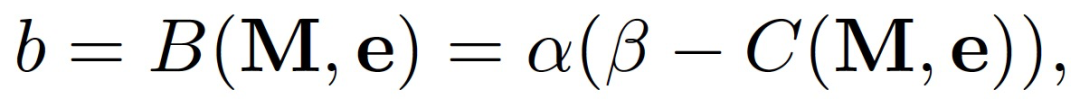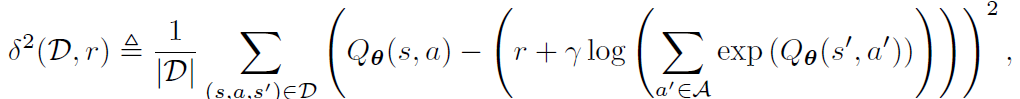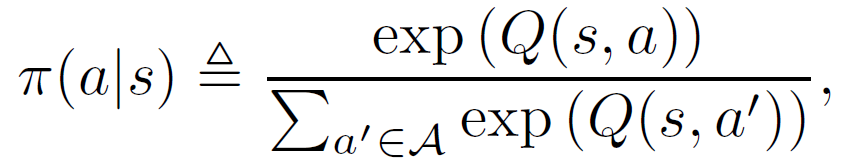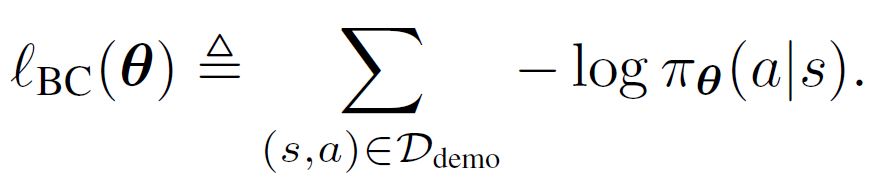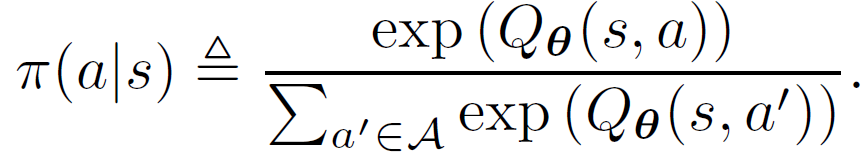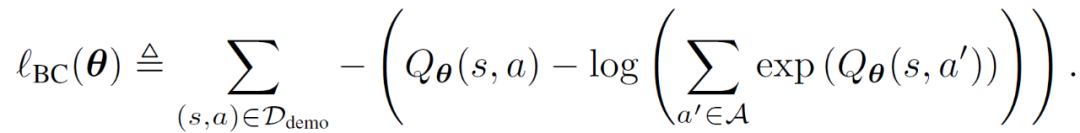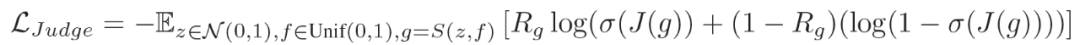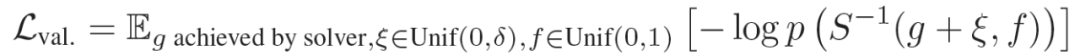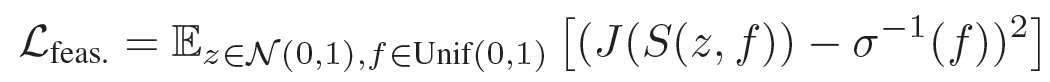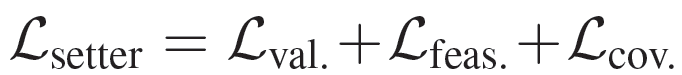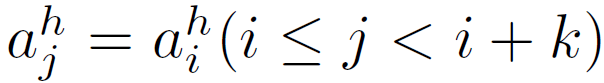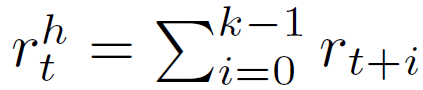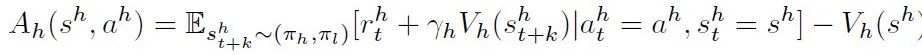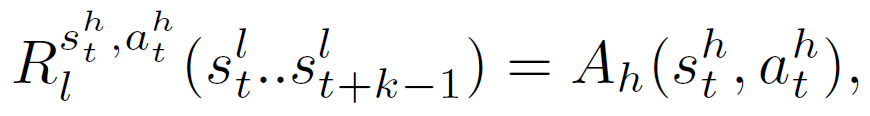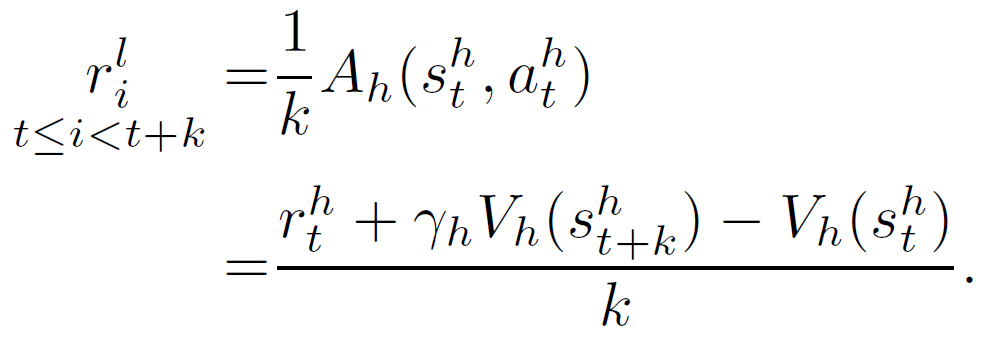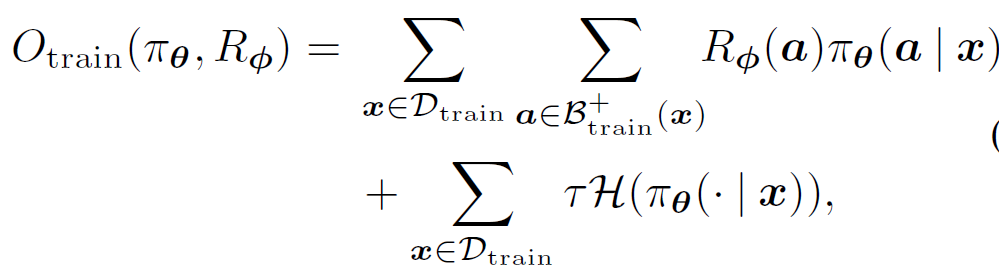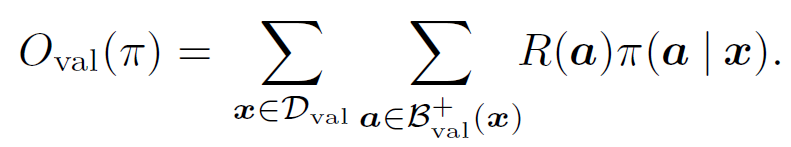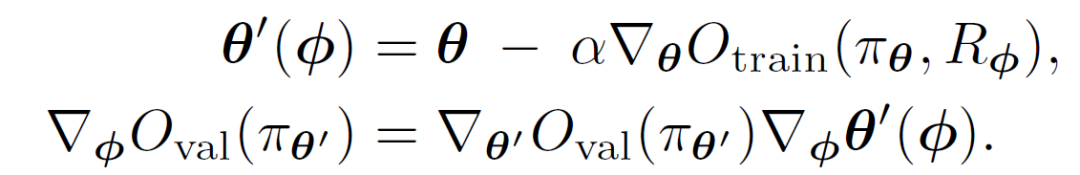深度强化学习实验室
作者:仵冀颖,Joni Zhong
编辑:DeepRL
如何解决稀疏奖励下的强化学习?本文将介绍常用方法以及相关论文。
强化学习(Reinforcement Learning,RL)是实现强人工智能的方法之一,在智能体(Agent)与环境的交互过程中,通过学习策略(Policy)以最大化回报或实现特定的目标。在实际应用场景中,RL 面临一个重要的问题:agent 无法得到足够多的、有效的奖励(Reward),或者说 agent 得到的是稀疏奖励(Sparse Reward),进而导致 agent 学习缓慢甚至无法进行有效学习。
然而对于人类来说,即便在稀疏奖励的状态下仍然能够持续学习。人类的学习也可以看做是内在动机和外在动机激励下的学习过程,关于内在动机和外在动机的激励机器之心也有过专门介绍,感兴趣的读者可以具体看一下这篇文章。
人类在日常生活中其实每天能够收获的奖励很少,但是也在持续的学习,改进自己的知识和能力,我们当然希望 agent 也能如此,也能够在得到稀疏奖励的情况下持续的进行有益的学习。本文重点探讨的就是在存在稀疏奖励的情况下引导 agent 继续学习或探索的强化学习问题。
目前解决稀疏奖励下的强化学习主要有两类方法:一是,
利用数据改进 agent 的学习
,包括已有数据、外部数据等;二是,
改进模型
,提升模型在大状态、大动作空间下处理复杂问题的能力。具体的,利用数据改进 agent 学习的方法包括好奇心驱动(Curiosity Driven)、奖励重塑(Reward Shaping)、模仿学习(Imitation Learning)、课程学习(Curriculum Learning)等等。改进模型的方法主要是执行分层强化学习(Hierarchical Reinforcement Learning),使用多层次的结构分别学习不同层次的策略来提高模型解决复杂问题的能力,以及元学习(Meta-Learning)的方法。
本文针对每一类方法选择了一篇近两年的文章进行示例性介绍,以了解稀疏奖励下的强化学习的最新研究进展。
1. 好奇心驱动(Curiosity Driven)
论文:Episodic Curiosity through Reachability
![]()
论文地址:https://arxiv.org/pdf/1810.02274.pdf
本文是 Google、Deepmind 和苏黎世联邦理工学院的研究人员提出「好奇心驱动」的强化学习新方法,发表在 ICLR 2019 中。该方法改变了 agent「好奇心」的生成方式和奖励机制,将 agent 对环境信息观察的记忆信息引入奖励机制中,有效降低了 agent「原地兜圈」、「拖延」等不良行为,提升了强化学习模型的性能。
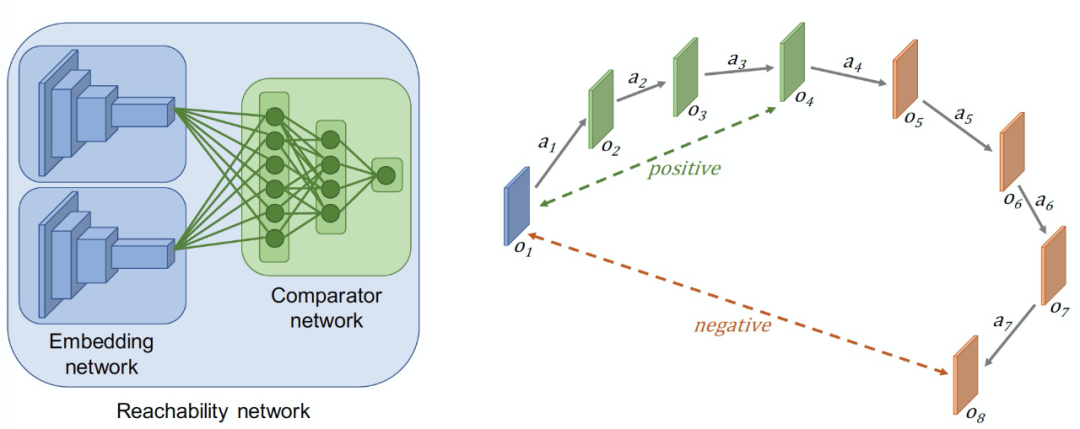
本文引入「好奇心(Curiosity)」的基本思路是:只对那些需要花费一定努力才能达到的结果给予奖励(这部分结果一定是在已经探索过的环境部分之外)。以探索环境所需要的步骤数量来衡量这些努力。为了估计步骤数量,本文训练了一个神经网络近似器:给定两个观测值,预测将它们分开需要执行多少步。图 1 给出了通过可达性(Reachability)来说明行动的新颖性(Novelty)的概念。图中的节点是观测值,边是可能的转换。蓝色的节点已经在记忆内存中,绿色的节点可以在 k=2 步内从记忆内存中到达(不新颖),橙色的节点距离较远—需要超过 k 步才能到达(新颖)。
本文方法的工作原理如下。Agent 在一个周期(Episode)开始时从一个空的记忆内存开始,在每一步都将当前观察结果与记忆中的观察结果进行比较,以通过可达性来确定新颖性。如果当前观察确实是新颖的,即从记忆中的观察到达到阈值需要更多的步骤,则 agent 会奖励自己并将当前观察添加到记忆内存中。这个过程一直持续到当前周期结束,且将内存清空。
![]()
1.1 周期好奇性(Episodic Curiosity)
本文讨论的 agent 在有限的持续时间 T 的周期内以离散时间步长与环境进行交互。在 t 时刻,基于观察环境空间 O,环境提供给 agent 一个观察值 o_t,以概率策略π(o_t)从一系列动作 A 中采样到动作 a_t,同时收获奖励 r_t、新的观察结果 o_t+1 以及周期结束的标识。agent 的目标是优化奖励的加权组合期望。
在存在稀疏奖励 r_t 的情况下,本文引入一个周期好奇性(Episodic Curiosity,EC)模块。EC 模块的目的是在生成奖励 r_t 的同时生成一个奖励红利:b,从而得到增强奖励:
![]()
从 RL 的角度分析,该增强奖励是一个密集奖励(Dense Reward)。在这样的密集奖励下学习,速度更快、更稳定,往往能获得更好的最终任务累积奖励 S。
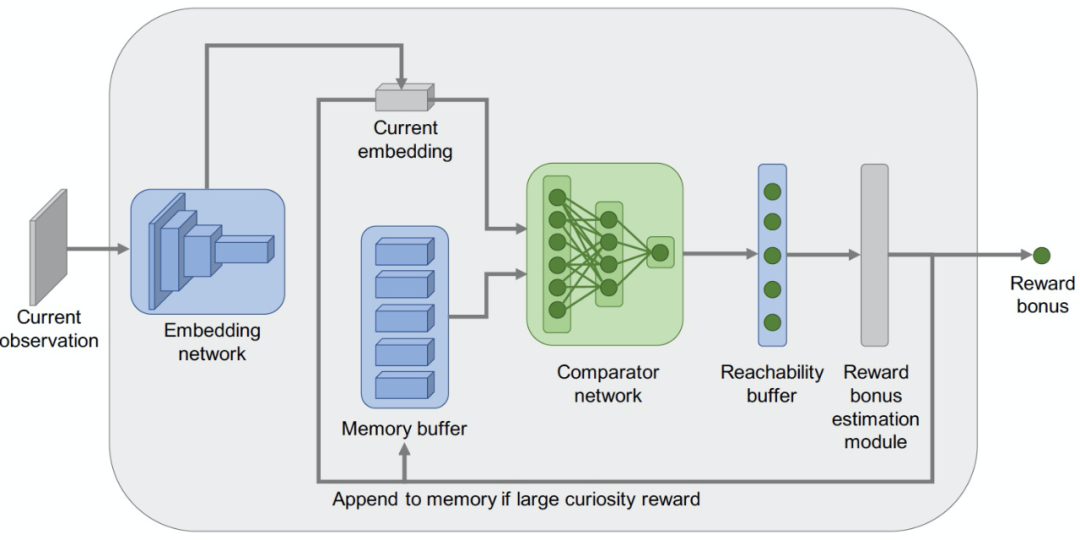
EC 模块的输入是当前的环境 o,输出为奖励红利 b。EC 模块包括参数组件和非参数组件。其中,参数组件包括一个嵌入网络 E 和一个比较网络 C。E 和 C 同时训练以预测可达网络,具体见图 2。
![]()
图 2. 左:可达(R)网络架构。右图:R 网络内部结构。R 网络是根据 agent 在行动中遇到的一系列观察结果进行训练的。
此外,图 2 中的 EC 模块中还包括两个非参数组件:一个周期性一个记忆缓冲区 M 和一个奖励红利估计函数 B。完整的 EC 模块见图 3。该模块将当前的观测值作为输入,并计算出一个奖励红利。对于新的观测值,该奖励红利会更高。这个红利随后与任务奖励相加,用于训练 RL 的 agent。
![]()
嵌入网络和比较器网络(Embedding and comparator networks)。
这两个网络被设计成共同作用于估计一个观测值 o_i 从另一个观测值 o_j 作为可达性网络的一部分的在 k 步内可到达的情况:
![]()
R 网络是一个用逻辑回归来作为训练损失(logistic regression lost)的分类器网络:如果两个观测值在 k 步内可以相互到达的概率低,它预测的值接近于 0。当这个概率高时,它预测的值接近于 1。在周期好奇性里面,这两个网络是分开使用的,以节省计算和内存。
周期性记忆(Episodic memory)。
记忆缓冲区 M 存储了使用嵌入网络 E 计算得到的当前事件中过去观测值的嵌入,记忆缓冲区的容量 K 有限,以避免内存和性能问题。每一个计算步骤中,当前观察的嵌入可能会被添加到内存中。超出容量时怎么办?作者发现一个在实践中行之有效的解决方案是用当前元素替换内存中的随机元素。这样一来,内存中的新元素仍然比旧元素多,但旧元素并没有被完全忽略。
奖励红利估算模块(Reward bonus estimation module)。
该模块的目的是检查内存中是否有可达到的观测值,如果没有发现,则为当前时间步长分配更大的奖励红利。该检查是通过比较器网络将内存中的嵌入与当前嵌入进行比较。本质上,这种检查保证了在内存中没有任何观测值可以通过从当前状态中只采取几个动作来达到,这也是本文对新颖性(Novelty)的描述。
在计算红利的算法中,比较器网络使用下列数值填充可达性缓冲区:
![]()
其中,e 是记忆缓存中的嵌入值。然后,从可达性缓冲区计算出内存缓冲区和当前嵌入的相似度分数为:
![]()
其中,F 为聚合函数。理论上,F=max 是一个很好的选择,然而,在实践中,它很容易出现来自参数嵌入和比较器网络的离群值。本文发现以 90% 作为最大值的稳健替代效果很好。
![]()
其中,参数 α 的选择取决于任务奖励的尺度,参数β决定了奖励信号,一般 β=0.5 适合于固定周期,β=1 适合于周期长度变化的场景。
当计算得到的红利 b 大于预先确定的阈值,将 b 增加到内存中。引入阈值检查的原因是,如果每一个观测嵌入都被添加到内存缓冲区,那么当前步骤的观测总是可以从上一步到达。因此,奖励将永远不会被授予。最后,本文还探索了训练可达性网络的两种设置:使用随机策略和与任务解决策略一起使用(在线训练)。
本文在不同的环境中验证了所提出的方法,包括 VizDoom,DMLab 和 MuJoCo。VizDoom 中的实验验证了本文能够正确复现之前最先进的好奇心方法 ICM(Pathak 等人,2017)[1]。DMLab 中的实验能够广泛测试本文方法的泛化性能以及其它基线算法—DMLab 提供了方便的程序级生成功能,使作者能够在数百个级别上训练和测试 RL 方法。最后,在 MuJoCo 中的实验展示了本文方法的通用性。三种环境下的任务见图 4。
![]()
图 4. 实验中考虑的任务实例。(a)VizDoom 静态迷宫目标,(b)DMLab 随机迷宫目标,(c)DMLab 钥匙门谜题,(d)MuJoCo 第一人称视角的好奇心蚂蚁运动。
本文使用的对比基线算法包括经典的开源 RL 算法 PPO(https://github.com/openai/baselines),引入 ICM 的 PPO(PPO+ICM)[4]以及 PPO+Grid Oracle。PPO+Grid Oracle 方法的理念是:由于我们可以访问 agent 在所有环境中的当前 (x; y) 坐标,我们也能够直接将世界分解为 2D 单元(2D cells),并奖励 agent 在周期中访问尽可能多的单元(奖励红利与访问的单元数量成正比)。在一个周期结束时,单元格访问次数归零。
![]()
图 5. 任务奖励作为 VizDoom 任务训练步骤的函数(越高越好)。
图 5 给出了将任务奖励作为 VizDoom 任务训练步骤的函数变化曲线。通过分析,作者得出以下几点结论。首先,本文对 PPO+ICM 基线算法的复现是正确的,结果符合文献[4]。其次,本文方法在最终性能上与 PPO+ICM 基线不相上下,三个子任务的成功率都很快达到 100%。最后,在收敛速度方面,本文算法明显快于 PPO+ICM—本文方法达到 100% 成功率与 PPO+ICM 相比至少快 2 倍。
![]()
图 6. 任务奖励作为 DMLab 任务训练步骤的函数(越高越好)。
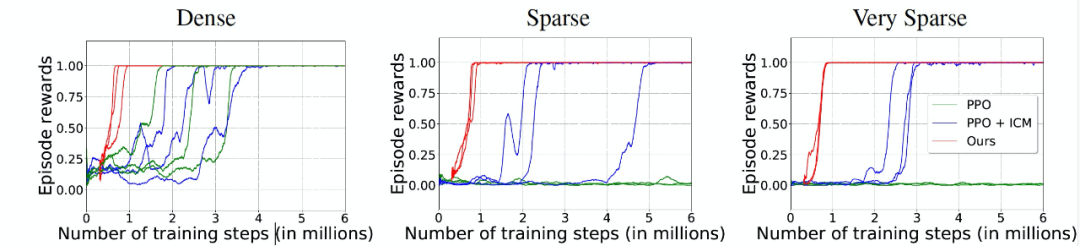
图 6 给出了将任务奖励作为 DMLab 任务训练步骤的函数变化曲线。这个实验旨在评估大规模的迷宫目标任务的泛化性能。作者在数百个关卡上进行训练,同时也在数百个保持关卡上进行测试。作者在 DMLab 模拟器中使用「探索目标位置大」(表示为 「Sparse」)和「探索障碍目标大」(表示为「Sparse+Doors」)级别。在这些关卡中,agent 从随机生成的迷宫中的一个随机位置开始(布局和纹理在周期开始时都是随机的)。在 1800 步 4 次重复的时间限制内(相当于 2 分钟),agent 必须尽可能多次地达到目标。每到达一个目标,它就会被重置到迷宫中的另一个随机位置,并必须再次前往目标。每次达到目标,agent 就会获得奖励 + 10,其余时间奖励为 0。
作者发现,即使对于普通的 PPO 算法来说,标准任务「Sparse」其实也是相对容易完成的。原因是 agent 的起点和目标在地图上的采样是相互独立的,例如有时两者恰好在同一个房间,这就简化了任务。由图 6,在使用 20M 4 重复步数的相同环境交互的情况下,本文方法在三个环境中的表现都优于基线方法 PPO+ICM。「Sparse」环境相对简单,所有方法都能合理的完成目标任务。在「Very Sparse」和「Sparse+Doors」的环境下,本文方法相对于 PPO 和 PPO+ICM 的优势更加明显。
在 MuJoCo 实验中,通过引入 EC 模块,MuJoCo 蚂蚁学会了基于第一人称视角的好奇心移动。标准的 MuJoCo 环境是一个带有统一或重复纹理的平面—没有什么视觉上的好奇心。为了解决这个问题,作者将 400x400 的地板铺成 4x4 大小的方块。每个周期开始时,都会从一组 190 个纹理中随机分配一个纹理给每块方块。蚂蚁在 400x400 的地板的中间的 200x200 的范围内随机初始化一个位置。一个周期持续 1000 步。如果蚂蚁质量中心的 z 坐标高于 1.0 或低于 0.2,则周期提前结束(即满足标准终止条件)。为了计算好奇心奖励,作者只使用安装在蚂蚁上的第一人称视角摄像头(这样就可以使用与 VizDoom 和 DMLab 中相同架构的好奇心模块)。
此外,作者还进行了一个实验,任务奖励极其稀少 -- 称之为「Escape Circle」。奖励的发放方式如下:在半径为 10 的圆圈内奖励为 0,从 10 开始,每当 agent 通过半径为 10+0.5k 的同心圆时,给予一次性奖励 1。最终的实验结果见表 1。本文方法明显优于基线(优于最佳基线 10 倍)。
![]()
本文提出了一种基于周期性记忆内存和可达性思想的新的好奇心模块,利用「好奇心」的概念本质上拓展了强化学习中的奖励(reward)。而且作者表示引入该模块的方法效果远超已有的方法。在今后的工作中,作者希望让 RL 的策略(Policy)能够不仅是通过奖励(Reward)来意识到记忆,而是通过行动(Action)。作者设想,是否能在测试时间内,利用基于可达性检索的记忆内容来指导探索行为?这将为小样本环境下(few-shot)新任务的探索和完成提供新的研究方向。
论文:Reward-Free Exploration for Reinforcement Learning
![]()
论文地址:https://arxiv.org/pdf/2002.02794.pdf
本文是最新的关于奖励重塑方法的文章,它将强化学习分为两个阶段:探索阶段(exploration phase)和规划求解(planning phase)阶段。其中,在探索阶段不接受任何奖励信息,只是在状态空间上探索并得到一个探索性的策略,执行该策略得到数据集 ;在规划阶段,对于任意一个给定的奖励函数,利用数据集估计出来的迁移函数(Transition Function),应用标准的强化学习方法求解策略。
本文工作最主要的技术挑战是处理那些难以到达的状态环境。在这种情况下,由于无法到达这些状态环境进行数据收集,很难学习到准确度较高的转移算子(Transition operator)。令λ(s)表示遵循任意策略访问状态 s 的最大概率,本文关注的问题是将状态空间划分为两组:
(1) λ(s)较小的、对奖励优化共享极小的状态,以及(2) 其它所有的状态
。作者引入了一种严格的分析方法,使得能够完全「忽略」难以访问的状态,只要求以概率比例 λ(s) 访问其余的状态。
本文是一篇重点阐述数学理论分析和证明的文章。我们对算法的主体进行了了解,关于数学证明相关的具体内容,感兴趣的读者可阅读文献原文。
本文提出的方法包括如下步骤:(1)学习到一个策略ψ,允许以合理的概率访问所有「重要」的状态;(2)通过执行策略ψ收集到足够多的数据;(3)使用收集到的数据计算经验转移矩阵;(4)对于每个奖励函数 r,利用转移矩阵和奖励 r 激活规划算法找到近似最优的策略。其中,探索阶段执行前两个步骤,规划求解阶段执行后两个步骤。
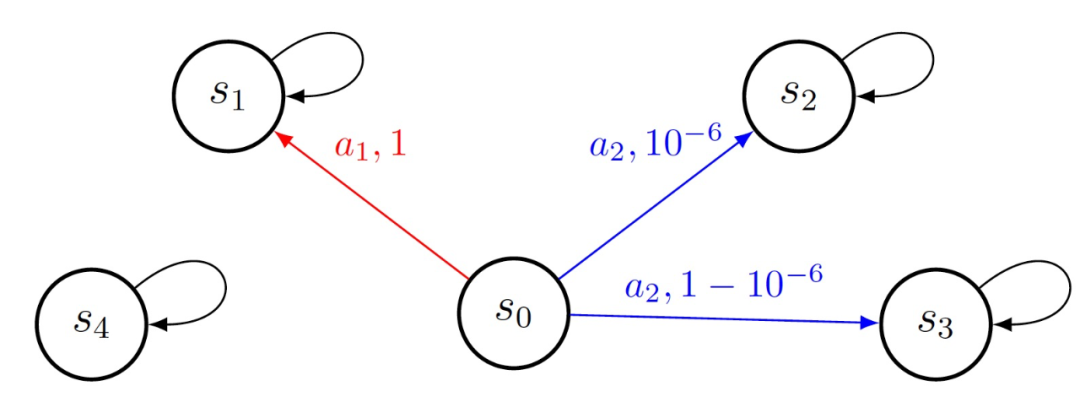
探索的目标是访问所有可能的状态,以便 agent 能够收集足够的信息,以便最终找到最优策略。然而,在马尔可夫决策过程(Markov decision process, MDP)中,无论 agent 采取何种策略,都有可能出现某些状态很难达到的情况。首先,图 1 给出了「重要」状态的概念。图 1 中共 5 个状态,s0 为初始状态。agent 仅能从 s0 迁移到其它状态,无论 agent 采取什么动作其它状态都会消失,也就是都会产生状态转移。对于状态 s0,使用蓝色箭头表示如果采取 a1 行动时的过渡,用红色箭头表示如果采取 a2 行动时的过渡。行动后箭头上的数字是过渡概率。在这个例子中,s4 是不重要的,因为它永远不可能达到。
![]()
作者在文章中证明了利用算法 2,可以从底层分布μ中收集数据。也就是说,所有重要的状态和动作都会以合理的概率被μ分布所访问。对于步骤 h 的每一个状态 s,算法 2 首先创建一个奖励函数 r,除了步骤 h 的状态 s 之外,这个奖励函数 r 始终为零,然后当 agent 与环境交互时,可以适当地给这个设计好的奖励 r 来模拟一个标准的 MDP。这个奖励 r 的 MDP 的最优策略正是最大化到达(s,h)的概率的策略。本文使用 Euler 算法逼近这个最优政策 [5]。
![]()
在规划阶段,赋予 agent 奖励函数 r,并根据 r 和探索阶段收集的数据集 D 找到一个接近最优的策略。具体见算法 3。作者在文章中证明了只要探索阶段收集的数据数量足够多,输出策略不仅是具有过渡矩阵的估计 MDP 的近优策略,也是真正 MDP 的近优策略。
![]()
作者在文章中真对这一算法给出了大量数学证明,感兴趣的读者可以阅读原文。文章最后,作者对未来的研究方向进行了展望。作者认为,在技术层面上,一个有趣的研究方向是理解无奖励 RL 的样本复杂度,其预先指定的奖励函数在探索阶段是不可观察的。另一个有趣的方向是为具有函数逼近的设置设计无奖励的 RL 算法。本文的工作突出并引入了一些在函数逼近环境中可能有用的机制,例如重要状态的概念和覆盖保证。未来研究将重点关注如何将这些概念推广到函数逼近的环境中。
3. 模仿学习(Imitation Learning)
论文:SQIL: Imitation Learning via Reinforcement Learning with Sparse Rewards
![]()
论文地址:https://arxiv.org/abs/1905.11108v3
本文是对强化学习中行为克隆(Behavioral Cloning,BC)方法的改进,最新接收于 ICLR2020。本文使用了一个简单、稳定的奖励:将与示范状态下的示范动作相匹配的动作奖励 + 1,而其它动作奖励为 0,引入 Soft-Q-Learning 算法,提出了适用于高维、连续、动态环境的模仿学习算法。
基于行为克隆的标准方法是利用监督学习来贪婪地模仿演示的动作,而不推理动作的后果。由此产生的复合错误可能会导致 agent 逐渐偏离了所演示的状态。因此,行为克隆面对的最大问题是,当 agent 偏离到标准分布之外的状态时,agent 不知道如何回到所标准的演示状态。
为了解决这个问题,该论文利用生成对抗网络(generative adversarial imitation learning,GAIL)引入行为克隆的基本思想就是训练 agent 不仅要模仿演示的动作,而且要访问演示的状态。
直观地讲,对抗式方法通过为 agent 提供(1)在演示状态下模仿演示行动的激励,以及(2)在遇到新的、分布外的状态时采取引导其回到演示状态的行动的激励来鼓励长时段的模仿(Long-horizon imitation)。本文所提出的方法是在不进行对抗性训练的情况下实现 (1) 和(2),即使用恒定的奖励(Constant Reward)代替学习的奖励。
本文使用 Soft-Q Learning(SQIL)来实例化方法[6],使用专家演示来初始化代理的经验记忆缓存区,在演示经验中设置奖励为常数 r=+1,在 agent 与环境交互时收集的所有新经验中设置奖励为常数 r=0。此外,由于 SQIL 并没有采取策略强化型学习,所以 agent 不一定要访问演示状态才能获得积极的奖励。相反,agent 可以通过重播最初添加到其经验记忆缓存区中的演示来获得积极奖励。因此,SQIL 可以用于高维、连续的随机环境中。具体 SQIL 的算法流程见算法 1:
![]()
![]()
δ^2 表示平方软贝尔曼误差(soft Bellman error),Q_θ表示 Soft Q 函数。r 为不依赖于状态或动作的常数。作者在文章中证明了 SQIL 相当于行为克隆的一种变体,它使用正则化来克服状态分布的转变。
SQIL 相当于在行为克隆的基础上增加了一个正则化项,将状态转换为动态信息纳入到模仿策略中,从而实现长时段模仿
。作者对这个观点进行了进一步证明:
在具有连续状态空间 S 和离散行动空间 A 的无限边际马尔科夫决策过程 (infinite-horizon Markov Decision Process,MDP) 中,假设专家遵循的政策 Π 能够最大化奖励 R(s;a)。政策 Π 形成基于动作 actions 的波茨曼分布(Boltzmann distribution)
![]()
其中,Q 表示 Soft Q 函数,给定软贝尔曼误差,Q 值为奖励和动态变化的函数值:
![]()
在本文的的模仿任务环境(imitation setting)中,奖励和动态变化都是未知的。专家通过在环境中推演政策并产生状态转换(s,a,s’)∈D_demo,生成一组固定的演示 D_demo。
用标准行为克隆训练模仿策略,相当于拟合一个参数模型,使负对数似然损失最小化:
![]()
本文使用一个 Soft Q 函数 Q_θ来表示政策,而不直接显式地对政策进行建模:
![]()
![]()
本文在四个基于图像的游戏—赛车(Car Racing)、Pong、Breakout 和太空入侵者(Space Invaders)—以及三个基于状态的任务—Humanoid、HalfCheetah 和 Lunar Lander 上对 SQIL 与基线算法 BC 和 GAIL 进行了实验。
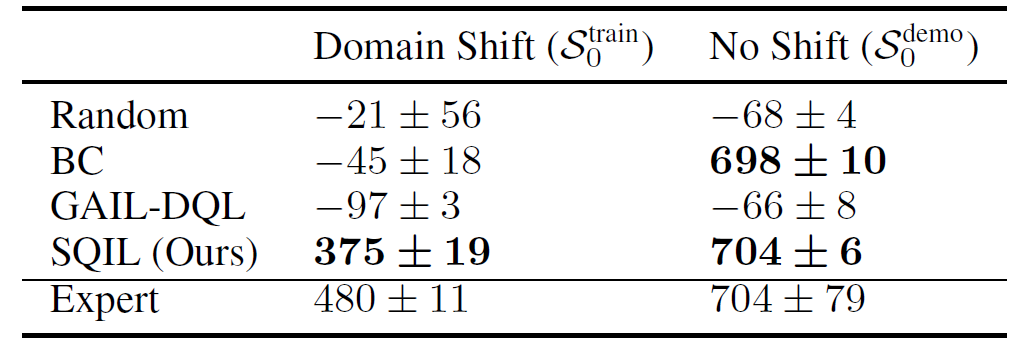
表 1 中的结果显示,当初始状态没有变化时,SQIL 和行为克隆(BC)的表现同样好。该任务非常简单,即使 BC 也能获得高额奖励。在无扰动条件下(右列),尽管 BC 有众所周知的缺点,但 BC 的表现仍大幅超过 GAIL。这表明 GAIL 中的对抗式优化会大幅阻碍学习。当从 S_0^train 开始时,SQIL 的表现比 BC 好得多,表明 SQIL 能够泛化到新的初始状态分布,而 BC 不能。
![]()
![]()
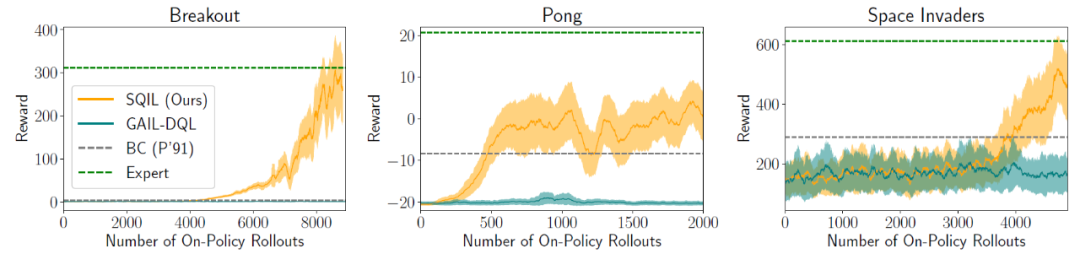
图 1 给出了几个基于图像的任务结果。图 1 中的结果显示,SQIL 在 Pong、Breakout 和 Space Invaders 上的表现优于 BC。BC 存在复合误差,而 SQIL 则没有。
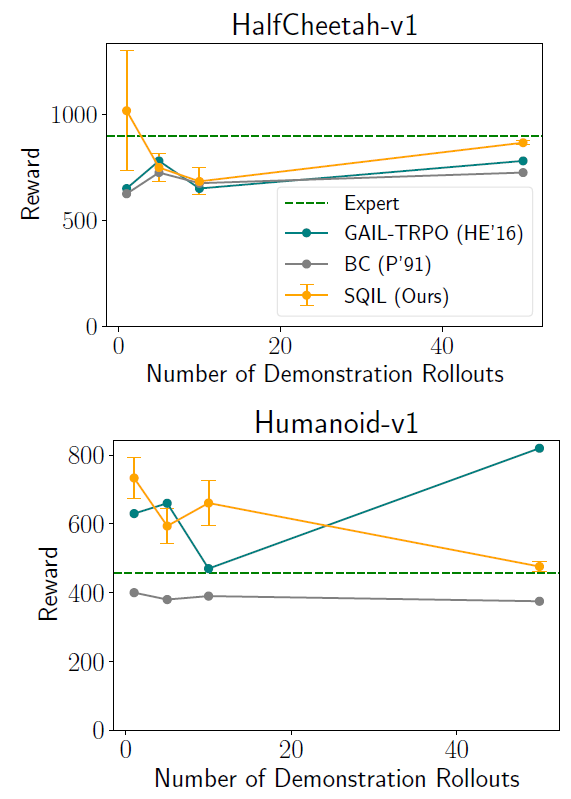
图 2 给出在低维 MuJoCo 中实现连续控制的 SQIL 实例。这个 SQIL 的实例与 MuJoCo 的 Humanoid(17 DoF)和 HalfCheetah(6 DoF)任务的 GAIL 进行了比较。结果显示,SQIL 在这两个任务上的表现都优于 BC,并且与 GAIL 的表现相当,这说明 SQIL 可以成功地部署在具有连续动作的问题上,并且 SQIL 即使在少量演示的情况下也能表现良好。
![]()
本文作者在文章的结论部分对 SQIL 的工作进行了小结。作者表示,本文尚未证明 SQIL 是否与专家的状态占有率相匹配,作者未来工作的将会尝试验证 SQIL 是否具有这一特性。此外,后续研究的另一个方向是使用 SQIL 来恢复奖励函数。例如,通过使用一个参数化的奖励函数,以软贝尔曼误差项来模拟奖励,而不是使用恒定奖励。这可以为现有的对抗式逆增强学习(inverse Reinforcement Learning, IRL)算法提供一个更简单的替代方案。
4. 课程学习(Curriculum Learning)
论文:Automated curricula through setter-solver interactions
![]()
论文地址:https://arxiv.org/pdf/1909.12892.pdf
课程学习是一种从简单概念到复杂问题逐步学习的方法,1993 年,RNN 的鼻祖 Jeffrey Elman 首次提出了采用课程学习的方式来训练神经网络。在他的文章中[1],Jeffrey Elman 说到「人类在许多方面与其他物种不同,但有两个方面特别值得注意:人类具有超乎寻常的学习能力,以及,人类达到成熟所需的时间特别长。人类学习的适应性优势是明显的,可以说,学习为行为的非遗传性传承创造了基础,这可能会加速我们物种的进化。」
本文是 ICLR 2020 中的一篇文章。文章将课程学习模拟人类教育依赖于课程的概念,通过将任务分解为更简单、静态的挑战,并给予密集的奖励,从而建立起复杂的行为。虽然课程对 agent 也很有用,但手工制作课程很耗时。本文探索在丰富的动态环境中自动生成课程。利用设定者 - 求解者(setter-solver)范式,展示了考虑目标有效性、目标可行性和目标覆盖率对构建有用课程的重要性。
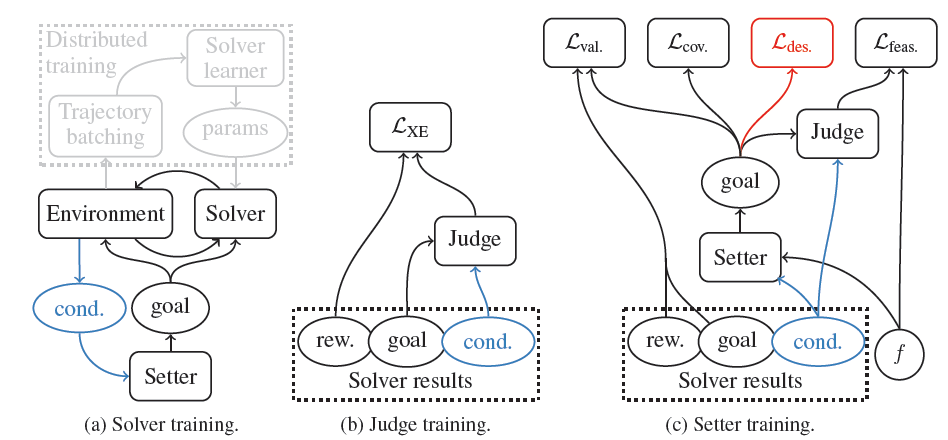
本文模型由三个主要部分组成:解算器(Solver) - 用来训练的目标条件 agent;设定器(Setter,S)—用来为 agent 生成目标课程的生成模型;判断器(Judge,J)—可以预测 agent 目前目标可行性的判别模型。训练机制见图 1。解算器 agent 使用分布式学习设置对设置者生成的目标进行训练,以计算策略梯度。对于设定器训练来说,有三个概念很重要:目标有效性、目标可行性和目标覆盖率。如果存在一个解算器 agent 策略,它实现这个目标的概率是非零,则称这个目标是有效的。这个概念与解算器的现行政策无关。可行性表达了目标目前是否可以由解算器实现。具体来说,如果解算器实现目标的概率为 f,则称该目标具有可行性 f∈[0,1]。因此,可行性目标的集合将随着解算器的学习而演变。判断器是一个可行性的学习模型,通过监督学习对解算器的结果进行训练。最后,目标覆盖率表示设定器产生的目标的可变性(熵)。
![]()
在每个周期开始时,agent 会收到一个由设定器采样的目标 g,并在周期结束时获得一个单一的奖励 R_g。如果解算器实现了目标,则奖励 R_g 为 1,如果在固定的最大时间后没有实现目标,则奖励 R_g 为 0。可以用任何 RL 算法来训练该解算器。
判断器被训练成一个二元分类器来预测奖励。本文使用交叉熵损失函数来训练判断器,输入分布则由设定器定义,标签是通过在这些目标上测试解算器获得的:
![]()
本文为设定器定义了三种损失,体现了目标有效性、可行性和覆盖率的概念。
有效性(Validity)
:描述为能够增加设定器生成解算器已经实现的目标的概率的生成性损失,具体为:
![]()
其中,g 是解算器实现的目标中的样本,不管它在该周期中的任务是什么。ξ 是少量的噪声,以避免过度拟合。p() 表示在固定的高斯先验知识下对 S 的潜在状态进行抽样的概率。
可行性(Feasibility)
:描述鼓励设定器选择与判断器当前对解算器的可行性估计最为匹配的目标的损失,具体为:
![]()
该损失均匀地采样一个期望的可行性 f(以训练设定器在一定难度范围内提供目标),然后试图使设定器产生判断器评定为与该期望可行性相匹配的目标。
覆盖率(Coverage)
:描述鼓励设定器选择更加多样化目标的损失。该损失有助于使设定器覆盖尽可能多的目标空间。具体为:
![]()
该损失使设定器的条件熵的平均值最大化。设置器被训练成使总损失最小化
![]()
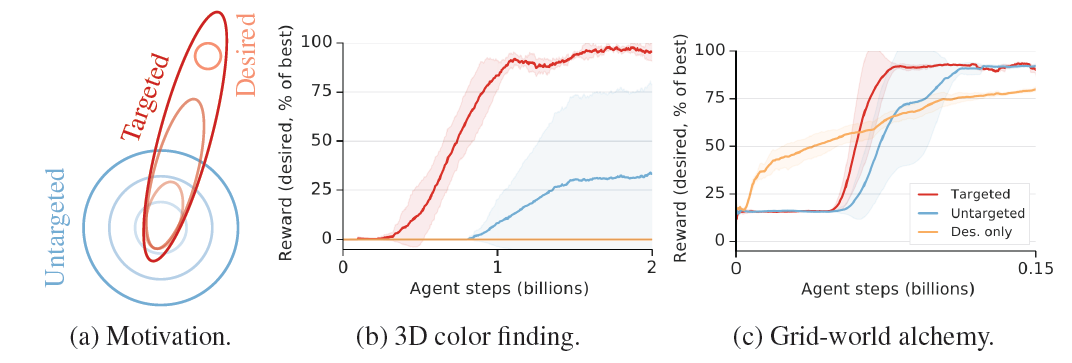
(1)三维寻色(3D color finding)。一个用 Unity(http://unity3d.com)构建的半现实的 3D 环境,由一个包含彩色物体和家具的房间组成(图 2a)。agent 可以移动和查看周围的情况,并可以拿起、操作和放下物体。这就形成了一个复杂的 46 维行动空间。在每个周期开始时,物体和家具被随机放置在房间周围。agent 收到一种颜色(或一对颜色)作为目标,如果在其视图中心的一个 patch(或两个相邻的 patch)包含接近这个目标的平均颜色,就会得到奖励。本文还使用了这种环境的一个扩展版本,其中房间的墙壁、天花板和地板,以及所有的物体,都被程序化地重新着色成每个周期随机选择的两种颜色之一(图 2b)。
(2)网格世界的炼金术(Grid-world alchemy)。二维网格世界环境,包含各种双色物体(图 2c)。每个周期对物体的颜色随机取样。解算器可以在网格中移动,并可以走过一个物体来拾取它。它一旦拿起一个物体,就无法放下。如果它已经携带了另一个对象,两个对象将系统性地组合成一个新的对象。解算器接收一个目标对象作为输入,如果它产生一个类似的对象,就会得到奖励。
在每个实验中,无论使用什么设置器进行训练,作者都在一个固定的任务测试分布上进行评估,以便在不同条件下有一个公平的比较。在这两种环境中,有效任务的空间(可以由专家完成)在设定器可表达的任务空间中占据很小的体积。
![]()
在复杂的任务环境中,通过基于难度的探索来发现期望的行为可能并不可行。一个任务可能有很多困难的方式,其中大部分与最终希望代理实现的目标无关。通过针对期望目标分布与期望目标损失,设定器可以推动解算器更高效地掌握期望任务(图 3a)。作者首先在 3D 寻色环境中进行探索。实验目标是 12 种亮色对的分布。在没有设定器的情况下发现这些亮色对是非常困难的。因此,只对期望的分布进行训练的结果是没有学习。无目标的 setter-solver 设置最终可以学习这些任务。在炼金术任务中,情况有些不同(图 3b)。
本文实验所选择的分布是困难的任务:该分布包括了房间中一半的物体。然而,由于设定器面临着学习条件生成分布(它是内置在期望分布中的)的困难挑战,作者发现从期望分布中学习(如果有的话)会导致更早的学习。这也再次强调了学习生成目标的复杂性,特别是当有效的目标分布是以复杂的、非线性的方式存在于环境状态中时。
![]()
图 3. 在已知目标分布的情况下的理想目标分布。((b)和 (c) 的性能分别是过去 5000 次和 1000 次实验的平均数)。
本文通过理论分析和实验验证了 setter-solver 方法的有效性,以及使其能够在不同环境的复杂任务中工作的扩展。本文的工作是这一思想的起点,作者认为,本文概述的策略是一个非常有意义的研究方向,有希望能够实现在日益复杂的任务中自动设计 agent 的学习课程。
5. 分层强化学习(Hierarchical Reinforcement Learning)
论文:Hierarchical Reinforcement Learning with Advantage-Based Auxiliary Rewards
![]()
论文地址:https://papers.nips.cc/paper/8421-hierarchical-reinforcement-learning-with-advantage-based-auxiliary-rewards.pdf
本文为 NeurIPS 2019 中的一篇文章,主要介绍了一种分层强化学习的框架。
分层强化学习(Hierarchical Reinforcement Learning,HRL)是一种用于解决具有稀疏和延迟奖励的长时段问题(Long-horizon problems)的有效方法。
本文提出了一个引入基于先进函数的辅助奖励的 HRL 框架(HRL with Advantage function-based Auxiliary Rewards,HAAR),HAAR 能够基于高层政策的优势函数对低层技能训练设置辅助奖励。引入这种辅助奖励,可以实现在不使用特定任务知识的情况下,高效、同步地学习高层政策和低层技能。
![]()
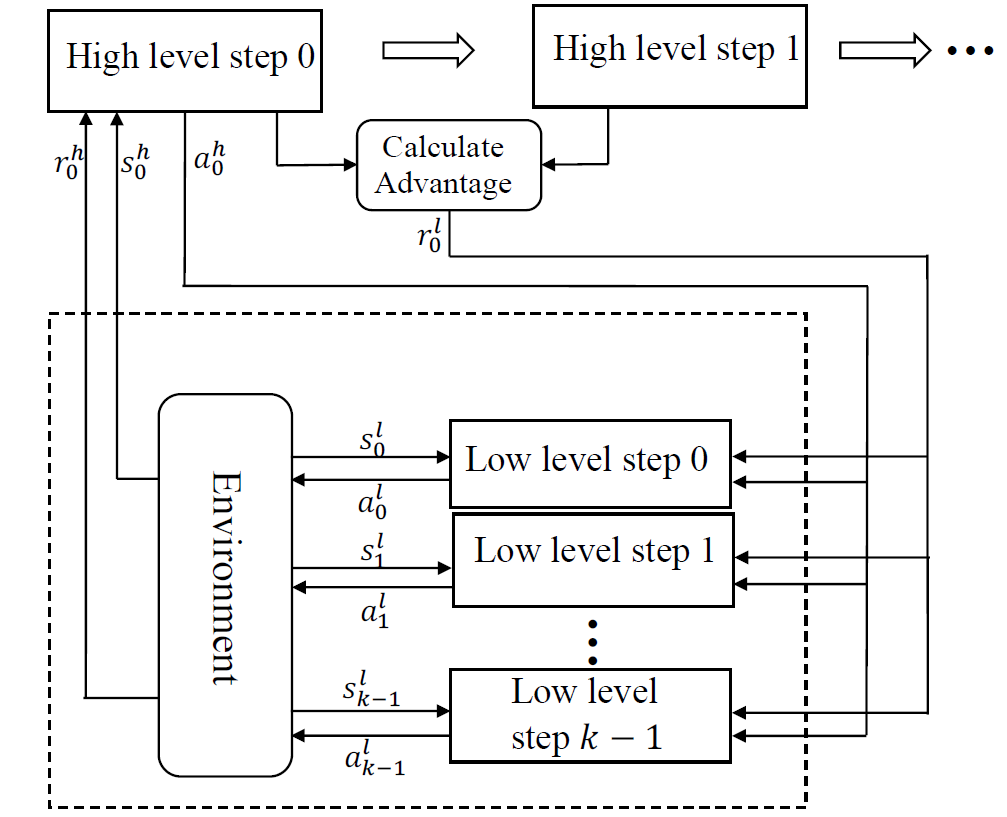
图 1 给出了 HAAR 的工作流程。在 i 时刻,agent 的状态(s_i)^h 采取了一个使用独热向量(one-hot vector)表征的高层动作(a_i)^h。π_l 为使用动作 (a_i)^h 和状态 (s_i)^l 作为输入的神经网络,输出一个低层动作 (a_i)^l。不同的低层技能表示为 (a_i)^h 分别输入到该神经网络中。神经网络 π_l 可以表征低层技能。选中的低层技能执行 k 个步骤:
![]()
之后,高层政策输出新的动作。高层奖励(r_t)^h 为 k 个步骤的环境反馈累积值:
![]()
基于高层的先进函数的计算低层奖励(r_t)^l。HAAR 的算法如下:
![]()
在每一轮迭代过程中,首先通过运行联合策略 π_joint 对一批 T 个低层时间步长进行抽样调查(算法 1 第五行)。之后,计算辅助奖励 (r_t)^l 并替换环境反馈的奖励 r_t(算法 1 第六行)。最后,利用可信区域政策优化(Trust Region Policy Optimization,TRPO)算法[7] 更新 π_h 和 π_l(算法 1 第七、八行)。
单靠稀疏的环境奖励很难提供足够的监督以使低层技能适应下游任务。本文引入高层优势函数(high-level advantage function)设置低层技能的辅助奖励。针对状态 (s_t)^h 的动作 (a_t)^h 的函数定义为:
![]()
为了鼓励选定的低层技能能够达到数值较大的状态,本文将估计的高层优势函数设置为对低层技能的辅助奖励。
![]()
为了简化计算,本文对优势函数进行一步估算(one-step estimation)。由于低层的技能是任务无关的(task-agnostic)且不区分高层状态,本文将总的辅助奖励平均分配给每一个低层步长:
![]()
这种辅助奖励功能的直观解释是,当技能的时间扩展执行将稀疏的环境奖励快速备份到高层状态时,可以利用高层值函数来指导低层技能的学习。此外,作者在文中还证明了 HAAR 保留了用于每一层级训练的优化算法的单调性,并且单调地改进了联合策略。
本文使用文献 [8] 提出的基准分层任务进行实验。实验设计的观察空间使得低层技能不受任务的限制,而高层的政策则尽可能的更具普遍性。低层只能访问 agent 存储在 s_l 中的关节角度。这种低层观察的选择需要在预训练阶段获得最少的领域知识,这样才能将技能成功迁移到不同的领域集合中。与其他 HRL 实验不同,agent 无法访问任何直接显示其绝对坐标的信息(x、y 坐标或自顶向下的视图,如 HRL 研究实验中常用的那样)。这使得本文实验中的任务对 agent 来说更难,但缺可以减轻对环境的过度适应,并向 π_h 和 π_l 引入潜在的可迁移性。
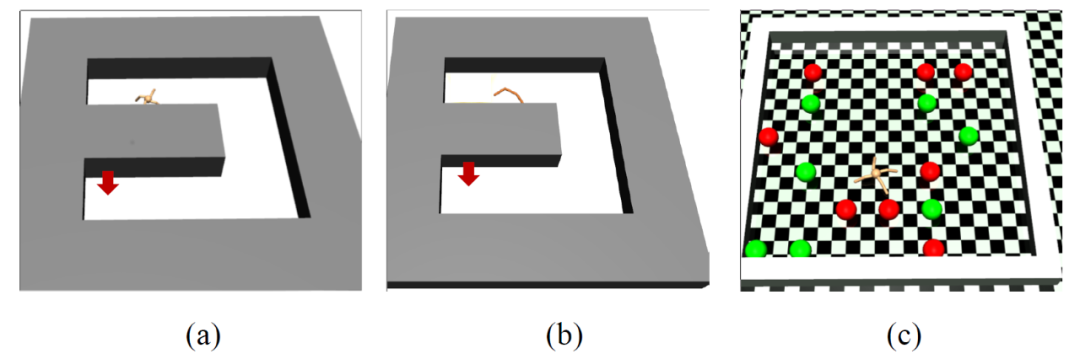
图 2 给出了本文实验环境的图示。其中,图 2(a)为蚂蚁迷宫(Ant Maze)。蚂蚁到达如图 2(a)所示的迷宫中的指定位置会得到奖励,随机化蚂蚁的起始位置以获得均匀的状态采样;图 2(b)为游泳者迷宫(Swimmer Maze)。游泳者在如图 2(b)所示的迷宫中到达目标位置时将获得奖励;图 2(c)为蚂蚁聚集(Ant Gather)。蚂蚁因收集分布在有限区域的食物而受到奖励,同时因触碰炸弹而受到惩罚。
![]()
作者使用几个效果较好的 HRL 方法作为基线方法进行对比实验,包括:SNN4HRL[9]、HAC[10]、HIRO[11]和非分层方法 TPRO[7]。
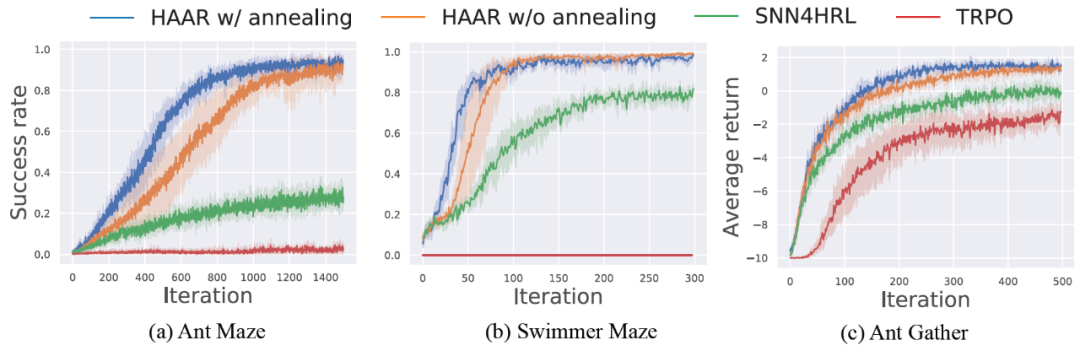
由图 3 的实验结果可以看出,HAAR 明显优于其它基线方法。所有曲线的结果取超过 5 次的平均值,阴影误差条表示 95% 的置信区间。SNN4HRL 在游泳者迷宫任务中的成功率高于蚂蚁迷宫任务,这是因为即使低层的技能没有得到很好的调整,游泳者也不会被绊倒。然而,在游泳者迷宫中,HAAR 仍然优于 SNN4HRL。在不到 200 次迭代之后,HAAR 达到了几乎 100% 的成功率。
蚂蚁采集任务面临的主要挑战不是稀疏的奖励,而是问题的复杂性,因为蚂蚁采集任务中的奖励比迷宫环境中的奖励要密集得多。尽管如此,HAAR 仍然取得了比基准算法更好的结果。这表明,HAAR 虽然最初是为稀疏奖励任务设计的,但也可以应用于其他场景。TRPO 本身是非层的,不适用于长时间稀疏奖励问题。TRPO 在所有迷宫任务中的成功率几乎为零。在蚂蚁收集任务中,TRPO 的平均回报率有所上升,这是因为蚂蚁机器人学会了保持静止,而不会因为接收到死亡奖励 - 10 而摔倒。
![]()
图 3. 蚂蚁迷宫、游泳者迷宫和蚂蚁聚集任务的成功率或平均回报率的学习曲线。
为了进一步展示 HAAR 与其他最先进的 HRL 方法相比是如何取得如此优异的性能,作者对上述实验结果进行了更深入的研究。在图 4 中,作者比较了蚂蚁迷宫任务训练前后的低层技能。在图 4 中,(a)和(b)分别展示了在训练前后收集的一批低层技能经验。蚂蚁总是在中心进行初始化,并使用单一技能在任意时间内行走。比较(b)和(a),我们注意到蚂蚁学会了右转(黄色的技能 1)和前进(红色的技能 0),并且在(c)的迷宫任务中很好地利用了这两种技能。
![]()
图 4:(a)蚂蚁初始低层技能的可视化图,(b) 蚂蚁迷宫辅助奖励训练后的低层技能,(c) 在蚂蚁迷宫中用 HAAR 训练蚂蚁后的样本轨迹。
本文使用 TRPO 进行在线策略训练,样本效率不高,计算能力成为 HAAR 在非常复杂的环境下应用的主要瓶颈。将非政策性训练与本文提出的层级结构结合起来可能有助于提高样本效率。由于低层技能初始化方案对性能有着显著的影响,探索低层技能初始化方案的最佳工作方式也是未来的研究方向。
论文:Learning to Generalize from Sparse and Underspecified Rewards
![]()
论文地址:https://arxiv.org/pdf/1902.07198.pdf
本文是 Google AI 最新发布的一篇文章。本文提出了一种元奖励学习(Meta Reward Learning, MeRL)来解决未指定奖励不足的问题。MeRL 通过优化辅助奖励函数向 agent 提供更精细的反馈。MeRL 引入了一个用于保存成功轨迹(Successful trajectory)的记忆缓存,使用一种新的探索策略来学习稀疏奖励。MeRL 在不使用任何专家演示的情况下自动学习辅助奖励函数,使其能够获得更广泛的应用,这有别于以往的奖励学习方法(例如上一篇分析的文章)。
本文重点研究语义分析中的弱监督问题,其目标是从问答对中自动发现逻辑程序,而不需要任何形式的程序监督。例如,给定一个问题「哪个国家获得银牌最多?」和一个相关的 Wikipedia 表,agent 需要能够生成一个类似 SQL 的程序来得到正确的答案(即「Nigeria」)。
![]()
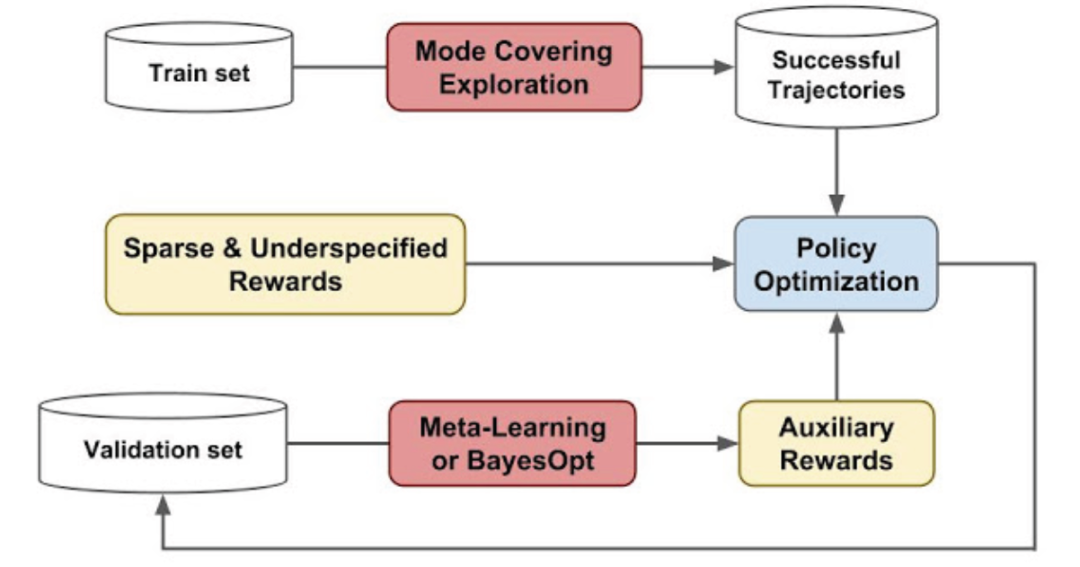
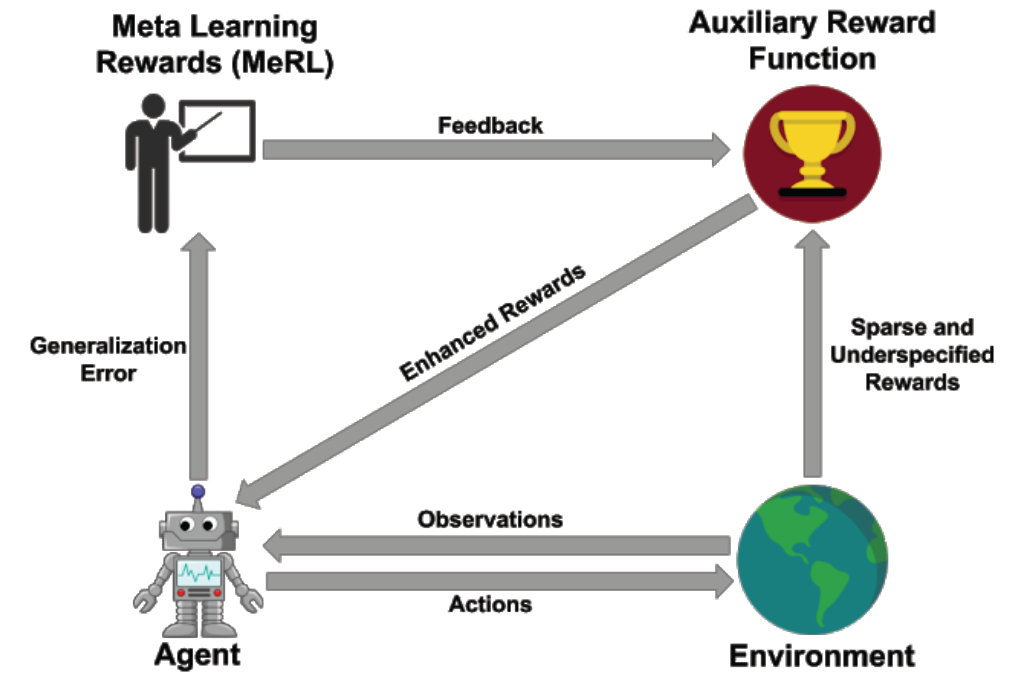
MeRL 在处理未指定奖励时的思路是:实现意外成功的虚假轨迹和程序对 agent 的泛化性能是有害的。为了解决这一问题,MeRL 优化了一个更加复杂的辅助奖励函数,该函数可以根据动作轨迹的特征区分意外成功和有目的成功。通过元学习,在保持验证集上最大化训练代理的性能,优化辅助奖励。图 2 为 MeRL 的原理图示。
![]()
图 2. MeRL 原理图:利用辅助奖励模型得到的奖励信号训练 agent,利用 agent 的泛化误差训练辅助奖励。
图 2 表示,智能体在学习过程中应该能够学习一个辅助的奖励函数,这个函数是基于在一个保持有效的集合上(包括元学习奖励、环境和智能体本身的奖励)都能使用该奖励函数训练的良好的策略。换言之,我们希望学习到有助于政策更好地推广的奖励功能。
本文提出了两种具体的方法来实现这一思想。(1) 基于基于梯度的 MetaLearning (MAML) (Finn et al., 2017)(算法 1)[2](关于 MAML 算法我们也有介绍);(2) 使用 BayesOpt (Snoek et al., 2012) 作为无梯度黑盒优化器(算法 2)[3]。使用经典 MAML 实现的方法记做 MeRL。作者将使用 BayesOpt 优化算法的方法记做(Bayesian Optimization Reward-Learning, BoRL)。
首先,我们来介绍 MeRL 方法。MeRL 的完整算法如下:
![]()
在 MeRL 的每次迭代中,同时更新策略参数 θ 和辅助奖励参数 ϕ。训练策略 π_θ 以最大化目标函数:
![]()
使用训练数据集和辅助奖励优化该目标函数,以使验证数据集上的元训练目标 O_val 最大化
![]()
MeRL 要求 O_val 可微。为了解决这个问题,本文只使用缓冲区(B_val)^+ 中包含 D_val 上下文成功轨迹的样本来计算 O_val。由于无法访问真实程序(ground truth programs),在非交互环境中使用波束搜索(Beam Search)、在交互环境中使用贪婪解码,使用未指定奖励的训练策略生成成功的轨迹。验证目标是使用训练目标上一个梯度步骤更新后获得的策略计算的,因此,辅助奖励通过更新的策略参数 θ' 影响验证目标,如下所示:
![]()
其次, 我们介绍 BoRL。BoRL 算法的完整流程如下:
![]()
在 BoRL 的每次实验中,通过最大化使用验证目标上的后验分布计算的获取函数来采样辅助奖励参数。在对奖励参数进行采样后,在固定迭代次数下优化训练数据集上的 O_RER 目标。训练结束后,在验证数据集上评估策略,以更新后验分布。BoRL 不要求验证目标函数 O_val 相对于辅助奖励参数是可微的,因此可以直接优化所关心的评价指标。
BoRL 比 MeRL 更具灵活性,因为可以使用 BoRL 优化验证集中的任何不可微目标,但 MeRL 只能用于可微目标。BoRL 算法相对于 MeRL 算法的另一个优点是,与基于局部梯度的优化算法相比,它对奖励参数进行全局优化。然而,由于可以访问要优化的目标的梯度,MeRL 比 BoRL 在计算效率上要高得多。此外,MeRL 能够在整个策略优化过程中适应辅助奖励,而 BoRL 只能表达在策略优化过程中保持不变的奖励函数。
作者在两个弱监督语义分析基准任务 WIKITABLEQUESTIONS[12]和 WIKISQL[13]上评估了本文方法。用一个简单的指令跟踪环境进行实验,这个环境是一个大小为 NxN 的简单迷宫,迷宫中随机分布着 K 个致命陷阱。位于迷宫四角之一的球门。具体如图 3。向盲 agent 输入一系列(左、右、上、下)指令。它勾勒出一条最优路径,agent 可以通过该路径达到目标而不被困住。如果 agent 在一定数量的步骤内成功达到目标,则它将获得 1 的奖励,否则为 0。
![]()
![]()
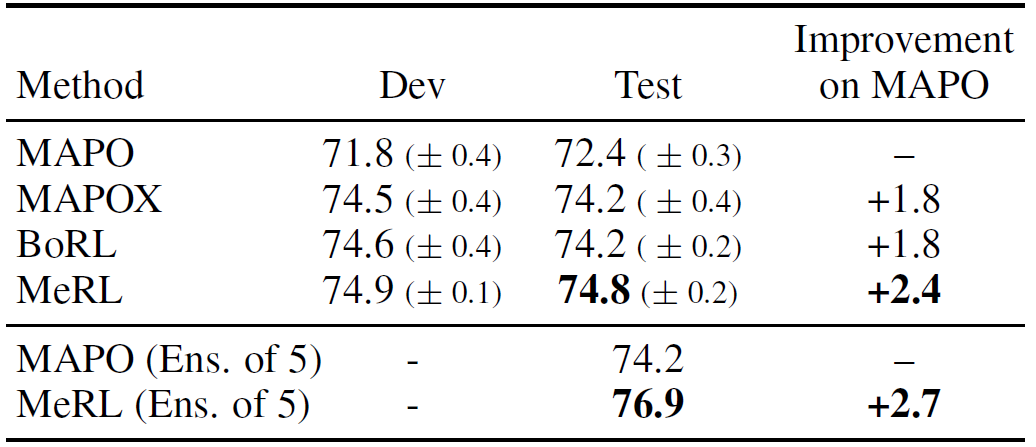
表 1. WIKITABLEQUESTIONS 上的结果
![]()
表 2. 在 WIKISQL 上只使用弱监督的结果
表 1 和表 2 分别给出了两个基准任务上的实验结果。对比算法包括 MAPO[14]以及 MAPOX(IML 的探测能力与 MAPO 的泛化能力相结合)。MeRL 在 WikiTableQuestions 和 WikiSQL 基准上的实验分别比以前的工作提高了 1.2% 和 2.4%。通过执行更好的探索,MAPOX 在两个数据集上的效果都优于 MAPO。此外,MeRL 和 BoRL 在 WIKITABLEQUESTIONS 中的效果都优于 MAPOX。
设计区分最优和次优行为的奖励函数对于将 RL 应用于实际应用是至关重要的。本文的研究朝着无需任何人监督的奖励函数建模方向迈出了一小步。在以后的工作中,作者希望从自动学习密集奖励函数的角度来解决 RL 中的信用分配问题。
从本文选择的几篇文章可以看出,利用数据改进稀疏奖励下 agent 学习的方法大多还是通过不同的方式改进或者引入新的奖励。例如,对奖励进行重塑(第二种方法)、设计新的奖励模块(第一种方法),以及引入新的奖励学习的方法(第三种方法和第四种方法)等等。而直接改进模型的方法则是直接重新设计经典的 RL 学习模型或框架,例如将其改变为多层的结构(第五种方法)或引入元学习的理念(第六种方法)等等。
针对稀疏奖励下的强化学习对于强化学习在工业场景中的实际应用有着重要意义,在不同的任务中应用哪种方法或哪些方法的组合可以获得更好的效果,值得更加深入的研究和探索。
[1] Elman J L . Learning and development in neural networks: The importance of starting small[J]. Cognition, 1993, 48(1):71-99. http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.128.4487&rep=rep1&type=pdf
[2] Chelsea Finn, Pieter Abbeel, and Sergey Levine. Model-agnostic meta-learning for fast adaptation of deep networks. In Proceedings of the 34th International Conference on Machine Learning (ICML), 2017.
[3] Jasper Snoek, Hugo Larochelle, and Ryan Adams. Practical Bayesian optimization of machine learning algorithms. In NIPS, pages 2960–2968, 2012.
[4] Deepak Pathak, Pulkit Agrawal, Alexei A Efros, and Trevor Darrell. Curiosity-driven exploration by self-supervised prediction. In International Conference on Machine Learning (ICML), volume 2017, 2017.
[5] Andrea Zanette and Emma Brunskill. Tighter problem-dependent regret bounds in reinforcement learning
without domain knowledge using value function bounds. arXiv preprint arXiv:1901.00210, 2019.
[6] Tuomas Haarnoja, Haoran Tang, Pieter Abbeel, and Sergey Levine. Reinforcement learning with deep energybased
policies. arXiv preprint arXiv:1702.08165, 2017.
[7] John Schulman, Sergey Levine, Philipp Moritz, Michael I. Jordan, and Pieter Abbeel. Trust region policy optimization. In ICML, 2015.
[8] Yan Duan, Xi Chen, Rein Houthooft, John Schulman, and Pieter Abbeel. Benchmarking deep reinforcement learning for continuous control. arXiv e-prints, page arXiv:1604.06778, Apr 2016.
[9] Carlos Florensa, Yan Duan, and Pieter Abbeel. Stochastic neural networks for hierarchical reinforcement learning. In Proceedings of The 34th International Conference on Machine Learning, 2017.
[10] Andrew Levy, George Konidaris, Robert Platt, and Kate Saenko. Learning multi-level hierarchies with hindsight. 2018.
[11] Ofir Nachum, Shixiang (Shane) Gu, Honglak Lee, and Sergey Levine. Data-efficient hierarchical reinforcement learning. In Advances in Neural Information Processing Systems 31, pages 3303–3313. 2018.
[12] Pasupat, P. and Liang, P. Compositional semantic parsing on semi-structured tables. ACL, 2015.
[13] Zhong, V., Xiong, C., and Socher, R. Seq2sql: Generating structured queries from natural language using reinforcement
learning. arXiv:1709.00103, 2017.
[14] Liang, C., Norouzi, M., Berant, J., Le, Q. V., and Lao, N. Memory augmented policy optimization for program
synthesis and semantic parsing. In Bengio, S., Wallach, H., Larochelle, H., Grauman, K., Cesa-Bianchi, N., and Garnett, R. (eds.), Advances in Neural Information Processing Systems 31, pp. 9994–10006. 2018.