【NeurIPS 2020 Tutorial】离线强化学习:从算法到挑战,80页ppt
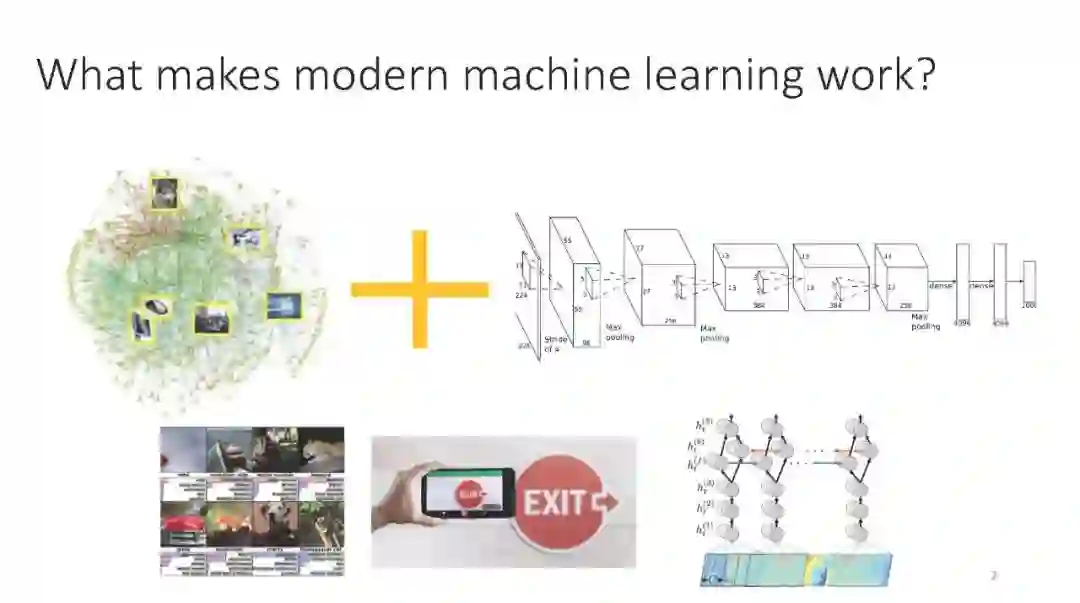
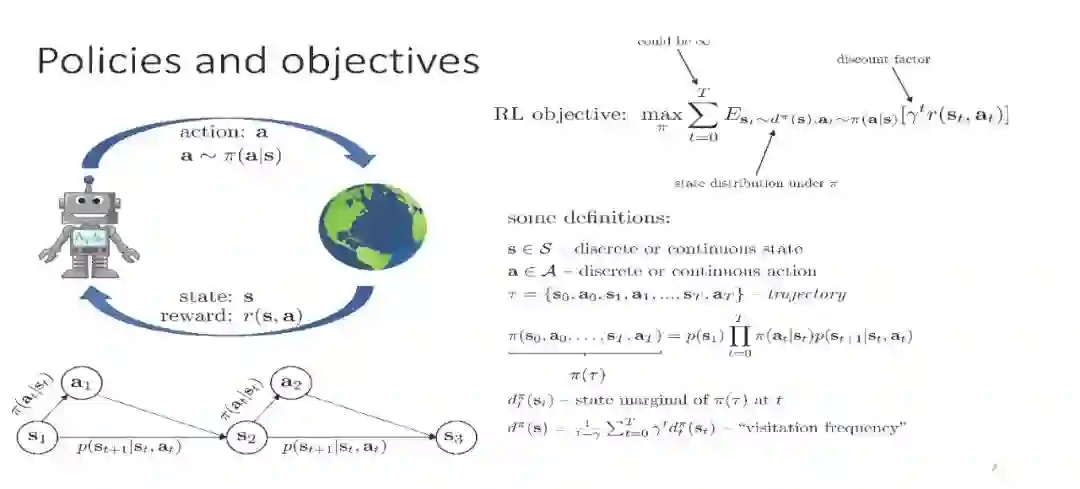
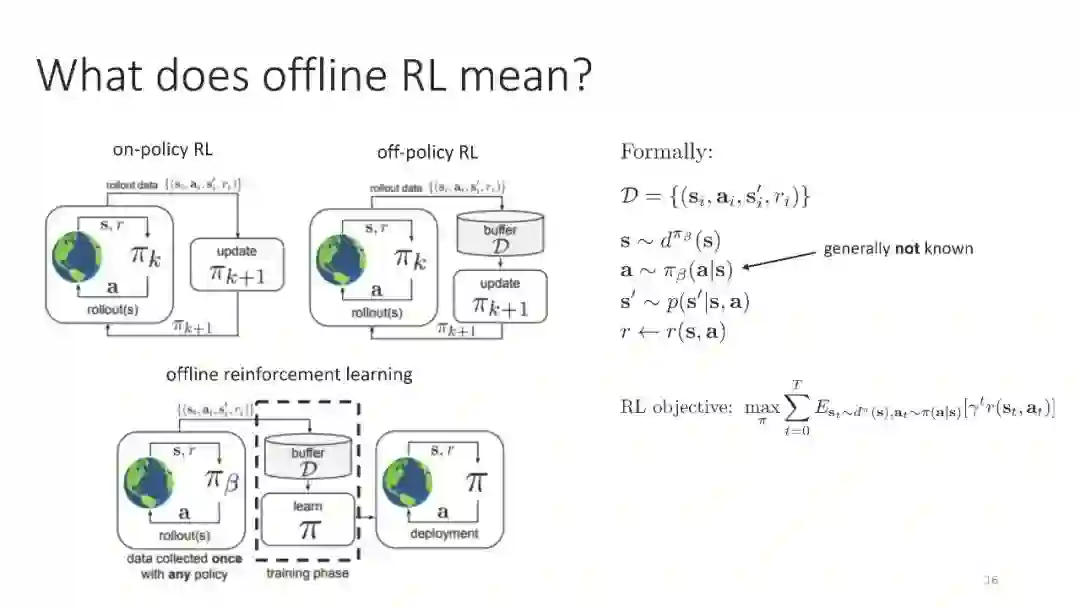
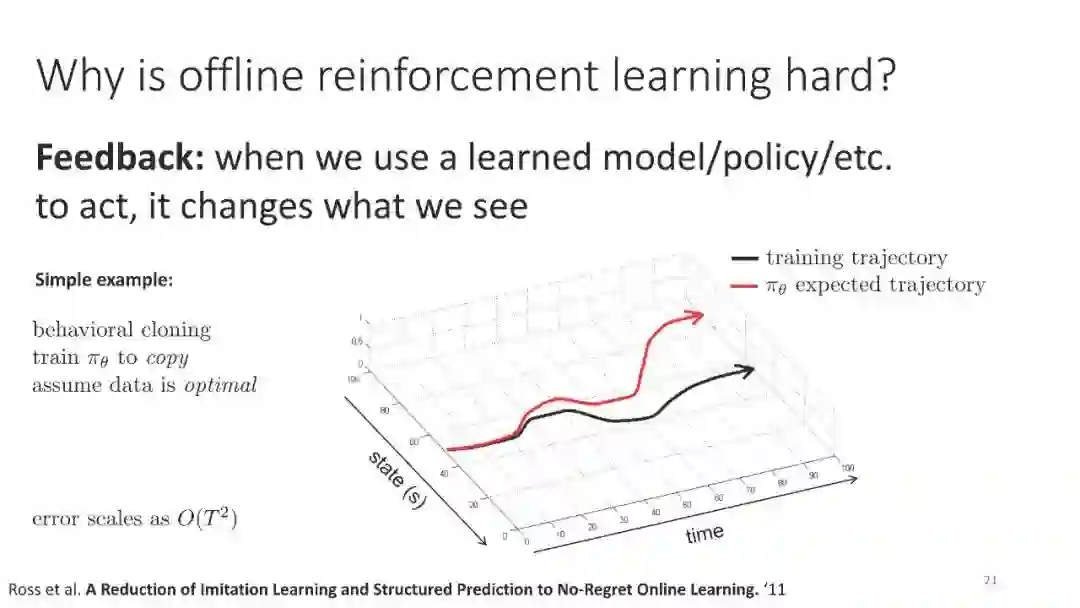
强化学习(RL)为基于学习的控制提供了一种数学形式,允许通过优化用户指定的奖励函数来获得接近最优的行为。最近,由于在许多领域的出色应用,RL方法受到了相当多的关注,但事实上,RL需要一个基本的在线学习范式,这是其广泛采用的最大障碍之一。在线交互通常是不切实际的,因为数据收集是昂贵的(例如,在机器人或教育代理中)或危险的(例如,在自动驾驶或医疗保健中)。另一种方法是利用RL算法,在不需要在线交互的情况下有效地利用以前收集的经验。这被称为批处理RL、脱机RL或数据驱动RL。这样的算法对将数据集转化为强大的决策引擎有着巨大的希望,类似于数据集在视觉和NLP中被证明是成功的关键。在本教程中,我们的目标是为读者提供既可以利用离线RL作为工具,又可以在这个令人兴奋的领域进行研究的概念性工具。我们的目标是提供对离线RL的挑战的理解,特别是在现代深度RL方法的背景下,并描述一些潜在的解决方案。我们将以一种从业者易于理解的方式呈现经典和最新的方法,并讨论在这一领域开展研究的理论基础。我们将以讨论待解问题来结束。
https://sites.google.com/view/offlinerltutorial-neurips2020/home








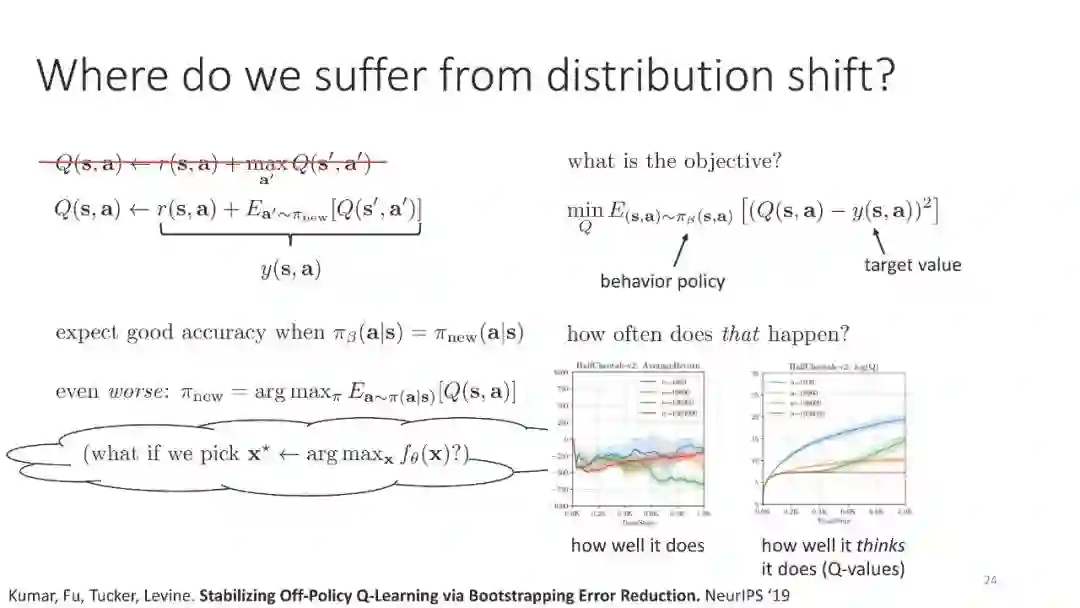
References
[1] Rishabh Agarwal, Dale Schuurmans, and Mohammad Norouzi. An optimistic perspective on offline reinforcement learning. arXiv preprint arXiv:1907.04543, 2019.
[2] Serkan Cabi, Sergio Gómez Colmenarejo, Alexander Novikov, Ksenia Konyushkova, Scott Reed, Rae Jeong, Konrad Zo ̇ łna, Yusuf Aytar, David Budden, Mel Vecerik, et al. A framework for data-driven robotics. arXiv preprint arXiv:1909.12200, 2019.
[3] Xinyue Chen, Zijian Zhou, Zheng Wang, Che Wang, Yanqiu Wu, and Keith Ross. Bail: Best-action imitation learning for batch deep reinforcement learning. Advances in Neural Information Processing Systems, 33, 2020.
[4] Thomas Degris, Martha White, and Richard S Sutton. Off-policy actor-critic. arXiv preprint arXiv:1205.4839, 2012.
[5] Miroslav Dudík, Dumitru Erhan, John Langford, Lihong Li, et al. Doubly robust policy evaluation and optimization. Statistical Science, 29(4):485–511, 2014.
[6] Frederik Ebert, Chelsea Finn, Sudeep Dasari, Annie Xie, Alex Lee, and Sergey Levine. Visual foresight: Model-based deep reinforcement learning for vision-based robotic control. arXiv preprint arXiv:1812.00568, 2018.
[7] Lasse Espeholt, Hubert Soyer, Remi Munos, Karen Simonyan, Volodymir Mnih, Tom Ward, Yotam Doron, Vlad Firoiu, Tim Harley, Iain Dunning, et al. Impala: Scalable distributed deep-rl with importance weighted
actor-learner architectures. arXiv preprint arXiv:1802.01561, 2018.
[8] Amir-massoud Farahmand and Csaba Szepesvári. Model selection in reinforcement learning. Machine learning, 85(3):299–332, 2011.
专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复“ORL” 就可以获取《【NeurIPS 2020 Tutorial 】离线强化学习:从算法到挑战,80页ppt》专知下载链接






