https://d223302.github.io/AACL2022-Pretrain-Language-Model-Tutorial/
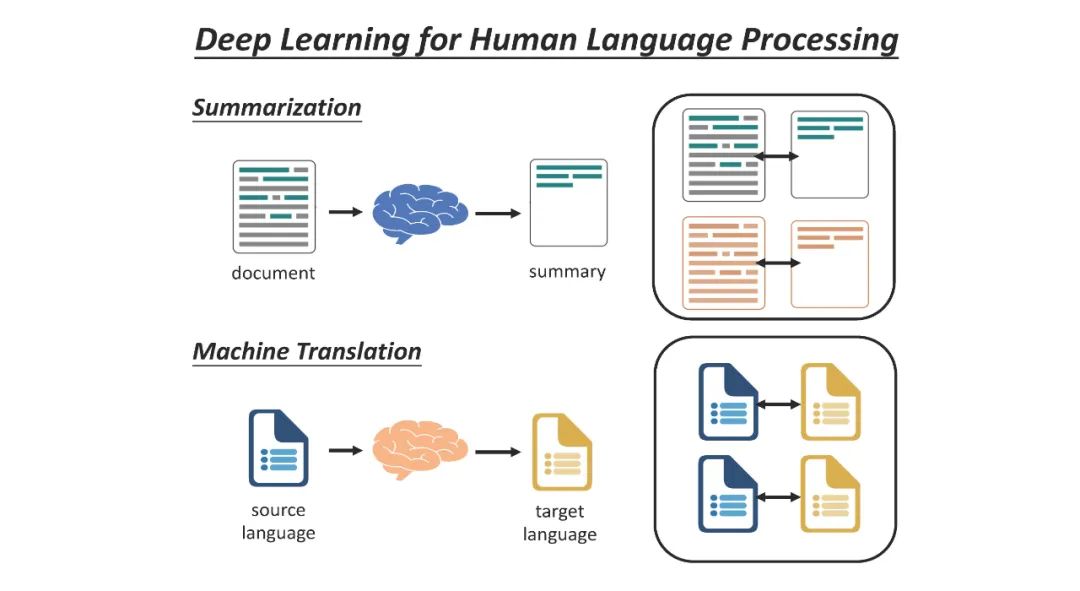
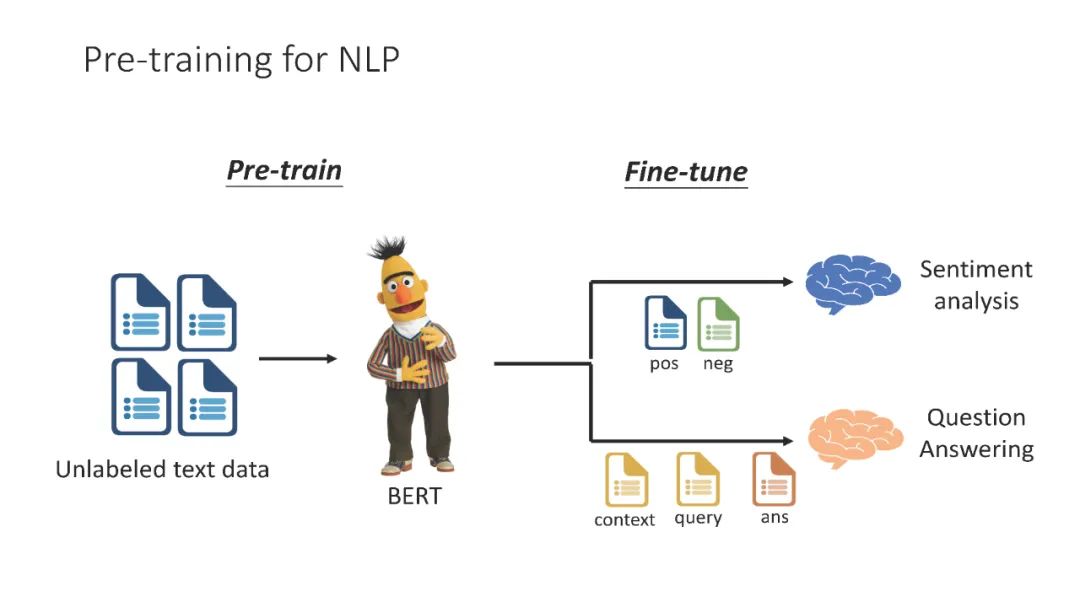
近年来,基于深度学习的自然语言处理(NLP)已经成为主流研究,比传统方法有了显著改进。在所有深度学习方法中,在感兴趣的下游任务上微调自监督预训练语言模型(PLM)已经成为NLP任务中的标准流程。自ELMo (Peters等人,2018年)和BERT (Devlin等人,2019年)于2018年提出以来,从PLM微调的模型在各种任务中占据了许多排行榜,包括问答、自然语言理解、自然语言推理、机器翻译和句子相似度。除了将PLM应用于各种下游任务之外,许多人一直在深入了解PLM的属性和特征,包括PLM表示中编码的语言知识,以及PLM在预训练期间获得的事实知识。虽然PLM第一次被提出已经三年了,但与PLM相关的研究并没有衰退的迹象。
有两个教程专注于自监督学习/ PLM:一个是NAACL 2019的教程(Ruder等人,2019),另一个是AACL 20201的教程。然而,考虑到该领域不断发展的性质,可以想象plm的研究已经取得了重大进展。具体来说,与2019年plm主要由科技巨头持有并用于科学研究相比,如今的PLM被具有不同硬件基础设施和数据量的用户更广泛地应用于各种现实场景中,从而提出了以前从未出现过的问题。已经取得了实质性的进展,包括对PLM的有效性和新的培训范式的可能答案,以使plm更好地部署在更现实的环境中。因此,我们认为通过一个组织良好的教程将PLM的最新进展告知NLP社区是必要和及时的。本教程分为两个部分:为什么PLM工作和PLM如何工作。表1总结了本教程将涉及的内容。本教程旨在促进NLP社区的研究人员对近年来PLM进展有一个更全面的看法,并将这些新出现的技术应用于他们感兴趣的领域。
教程结构预训练语言模型是在大规模语料库上以自监督方式进行预训练的语言模型。传统的自监督预训练任务主要涉及恢复损坏的输入句子,或自回归语言建模。在对这些PLM进行预训练后,可以对下游任务进行微调。按照惯例,这些微调协议包括在PLM之上添加一个线性层,并在下游任务上训练整个模型,或将下游任务表述为句子补全任务,并以seq2seq的方式微调下游任务。在下游任务上对PLM进行微调通常会带来非凡的性能提升,这就是plm如此受欢迎的原因。在教程的第一部分(估计40分钟)中,我们将总结一些发现,这些发现部分解释了为什么PLM会导致出色的下游性能。其中一些结果帮助研究人员设计了更好的预训练和微调方法。在第二部分(估计2小时20分钟)中,我们将介绍如何预训练和微调PLM的最新进展;本部分中介绍的新技术已经被证明在实现卓越性能的同时,在硬件资源、训练数据和模型参数方面带来了显著的效率。