中文预训练模型研究进展

近年来,预训练模型在自然语言处理领域蓬勃发展,旨在对自然语言隐含的知识进行建模和表示,但主流预训练模型大多针对英文领域。中文领域起步相对较晚,鉴于其在自然语言处理过程中的重要性,学术界和工业界都开展了广泛的研究,提出了众多的中文预训练模型。文中对中文预训练模型的相关研究成果进行了较为全面的回顾,首先介绍预训练模型的基本概况及其发展历史,对中文预训练模型主要使用的两种经典模型Transformer和BERT进行了梳理,然后根据不同模型所属类别提出了中文预训练模型的分类方法,并总结了中文领域的不同评测基准,最后对中文预训练模型未来的发展趋势进行了展望。旨在帮助科研工作者更全面地了解中文预训练模型的发展历程,继而为新模型的提出提供思路。
1 引言
自然语言处理(NaturalLanguageProcessing,NLP)是计 算机利用人类定义的算法对自然语言形式的输入进行加工处 理的过程,旨在让计算机可以像人类一样理解和生成语言,具 备如人类一样的听、说、读、写、问、答、对话、聊天等的能力,并 利用已有知识和常识进行推理分析.自然语言处理技术的发 展经历了从基于规则到基于统计的过程.随着深度学习的发 展,图像、文本、声音、视频等不同形式的信息载体被自然语言 处理技术突破,大量的神经网络被引入自然语言理解任务中, 如循环神经网络[1](RecurrentNeuralNetworks,RNN)、卷积神经网络[2](ConvolutionalNeuralNetworks,CNN)、注意力 机制[3](AttentionMechanism)等.在特定的自然语言处理任 务中,神经网络可以隐性地学习到序列的语义表示与内在特 征,因此,神经网络成为了解决复杂自然语言处理任务最有效 的方法.随着计算力的不断增强,深度学习在自然语言处理 领域中不断发展,分布式表示占据了主导地位,不仅在指定任 务中可以端到端地学习语义表示,而且可以在大规模无标注 的文本上进行自主学习,能更灵活地运用在各种下游任务中. 然而,早期在有监督数据上训练浅层模型往往存在过拟合和 标注数据不足等问题,在训练深层模型参数时,为了防止过拟 合,通常需 要 大 量 的 标 注 数 据,但 有 监 督 的 标 注 数 据 成 本较高,因此模型主要利用网络中现存的大量无监督数据进行 训练.在此背景下,预训练技术被广泛地应用在自然语言处 理领域.其中,最经典的预训练模型是 BERT [4]模型,在多个 自然语言处理任务中取得了最好结果(StateoftheArt,SOG TA).此后出现了一系列基于 BERT 的预训练模型,掀起了 深度学习与预训练技术的发展浪潮。
随着国内外研究者在预训练模型方面的深入研究,目前 已有很多关于预训练模型的综述,但缺少专门针对中文领域 的相关综述.当前,中文预训练模型蓬勃发展并取得一定的 成绩,因此,对现有研究成果进行全面的分析和总结非常必 要.本文期望能为中文预训练相关领域的学者提供参考,帮 助科研工作者了解目前的研究现状和未来的发展趋势.本文 第2节概述预训练模型的基本情况;第3节主要介绍两种基 本模型,即 Transformer和 BERT;第4节根据不同模型的所 属类别提出典型的中文预训练模型的分类方法,并汇总了中 文预训练模型的相关资源;第5节梳理了中文领域的不同评 测基准;最后总结全文并展望未来.
2 预训练模型
2.1 预训练模型发展史
从预训练语言模型的发展时间来看,可以将其分为静态 预训练模型和动态预训练模型.2013年,Mikolov等[5]在神 经网络语言模型(NeuralNetworkLanguageModel,NNLM) 思想的基础上提出 Word2Vec,并引入大规模预训练的思路, 旨在训练具有特征表示的词向量,其中包括 CBOW 和 SkipG Gram 两种训练方式.相比 NNLM 模型,Word2Vec可以更 全面地捕捉上下文信息,弥补 NNLM 模型只能看到上文信息 的不足,提高模型的预测准确性,Word2Vec极大地促进了深 度学习在 NLP中的发展.自 Word2Vec模型被提出以来,一 批训练词向量的模型相继涌现,例如,Glove [6]和 FastText [7] 等模型均考虑如何得到文本单词较好的词向量表示,虽然对 下游任务性能有所提升,但其本质上仍是一种静态的预训练 模型.
2018年,Peters等[8]提出的 ELMo模型将语言模型带入 动态的预训练时代.ELMo模型采用双层双向的 LSTM [9]编 码器进行预训练,提取上下文信息,并将各层词嵌入输入特定 下游任务中进行微调.该模型不仅可以学习到底层单词的基 础特征,而且可以学到高层的句法和语义信息.然而,ELMo 模型只能进行串行计算,无法并行计算,模型训练的效率较 低;此外,该模型无法对长序列文本进行建模,常出现梯度消 失等问题.而 后,OpenAI提 出 了 GPT(GenerativePreGtraiG ning)[10]模 型.与 ELMo模 型 不 同,GPT 采 用 Transformer 深度神经网络,其处理长文本建模的能力强于 LSTM,仅使用 Transformer解码器进行特征提取,在机器翻译等生成式任务 上表现惊人,但这一特点也导致 GPT 只利用到了当前词前面 的文本信息,并没有考虑到后文信息,其本质上依旧是一种单 向语言模型.为了解决 GPT等模型单向建模的问题,2018年, Devlin等[4]提出了 BERT 模型,该模型是第一个基于 Transformer的 双 向 自 监 督 学 习 的 预 训 练 模 型,在 英 文 语 言 理解评测基准[11]榜单中的多个任务上达到了SOTA 结果,此 后出现了一大批基于 BERT的预训练模型,大幅提升了下游 自然语言处理任务的性能.中文预训练模型虽然起步较晚, 但发展迅速,已经取得了一定成果,本文第4节将对其进行重 点介绍.
2.2 研究中文预训练模型的原因
首先,中文和英文分别是世界上使用人数最多和范围最 广的两种语言,然而在自然语言处理领域,英文预训练模型较 为普遍,例如,以 BERT 为首及其后出现的大量预训练模型 均是在单一语料英文数据集上进行训练,此外模型的设计理 念也更适用于英文,比如分词方式及掩码方式等.其次,中文 和英文语言本质上存在差异,它们的主要区别是,中文文本通 常由多个连续的字符组成,词与词之间没有明显的分隔符. 如果使用英文预训练模型去处理常见的中文任务,效果往往 不佳.因此,为了推动中文领域自然语言处理技术和预训练 模型在多语言任务方面的发展,构建以中文为核心的预训练 模型势在必行.
3 Transformer和 BERT
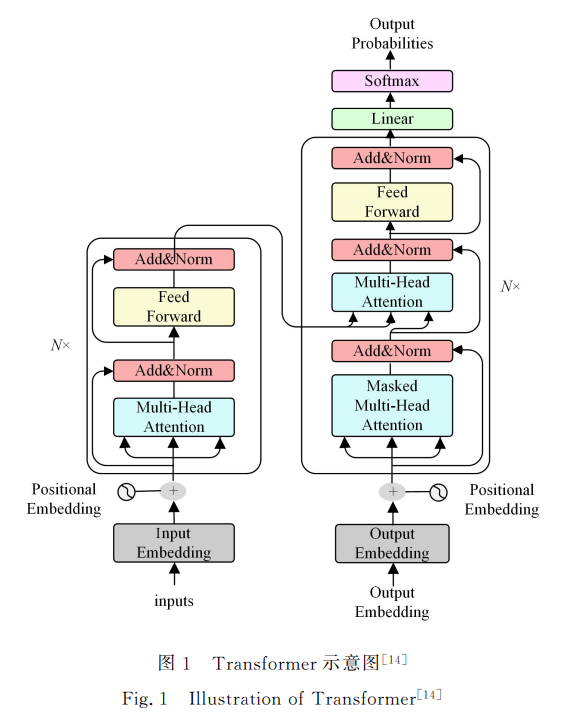
自2021年以来,中文预训练模型进入井喷式的发展阶 段,其架构主要基于 Transformer和 BERT 两种基础模型,本 节主要介绍这两种模型. 图1为典型的 Transformer架构,该架构由6个结构相 同的编码器和解码器堆叠而成.单个编码器由堆叠的自注意 力层和前馈神经网络组成,解码器由堆叠的自注意力层、掩码 注意力层 和 前 馈 神 经 网 络 组 成.有 关 Transformer的 详 细 细节介绍请参考文献[14].
BERT
BERT [4] (Bidirectional Encoder Representations from Transformers)是由谷歌提出的一种面向自然语言处理任务 的无监督预训练语言模型,由 Transformer的双向编码器表 示.BERT的架构如图2所示.
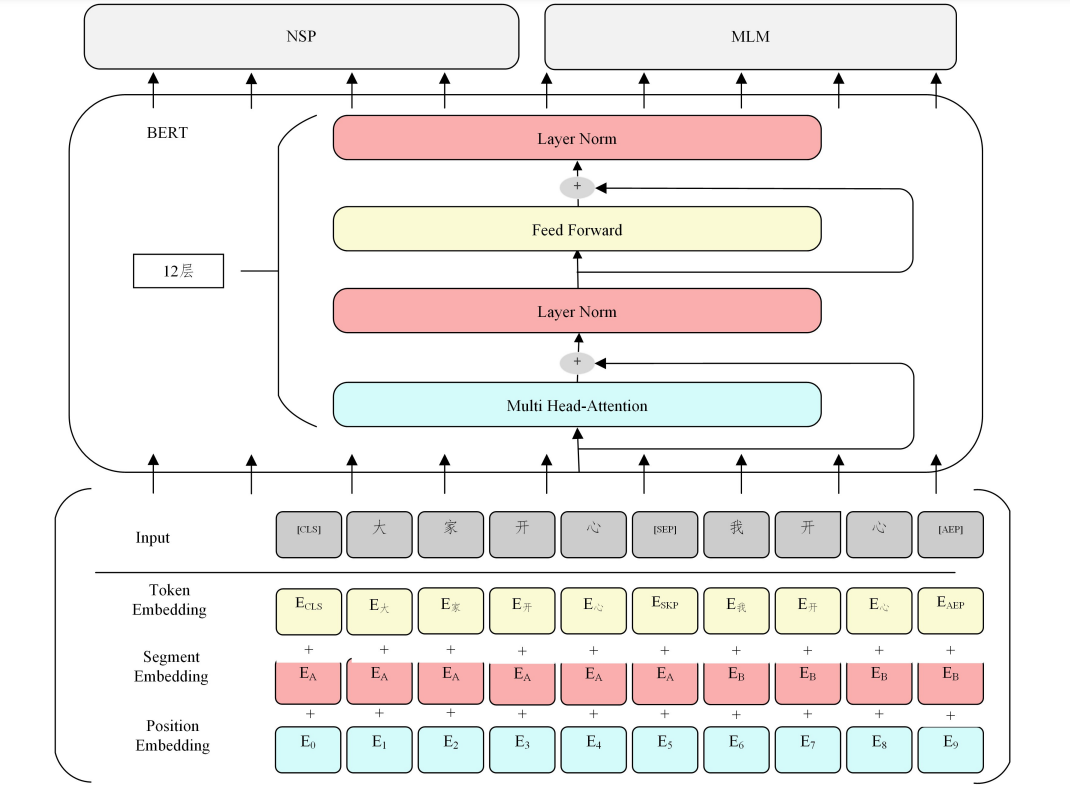
图2 BERT示意图[4]
4 中文预训练模型分类
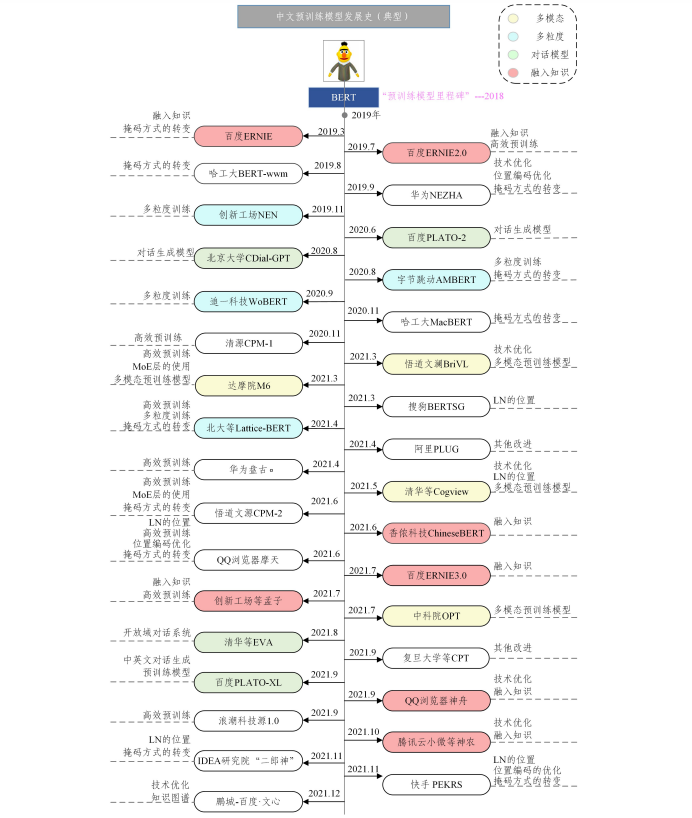

图3 中文预训练模型分类图
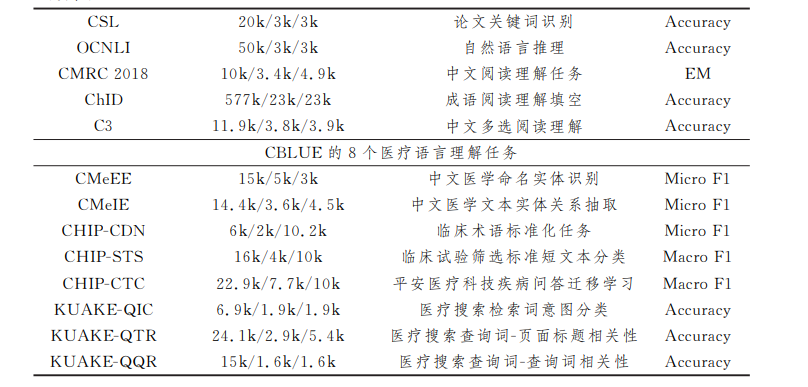
5. 中文领域的评测基准
5.1 为什么建立中文领域的评测基准
首先,从使用人数上看,中国人口占世界人口的五分之 一,人数庞大,因此中文是世界上使用人数最多的语言;其次, 从语言体系上看,中文与英文差异较大;最后,从数据集角度 出发,中文领域公开可用的数据集较少,此前提出的中文预训 练模型在英文评测基准上评估,无法完全体现出模型性能. 当下预训练模型的发展极其迅速,英文领域的评测基准已步 入成熟阶段,而中文领域的缺失必然会导致技术落后,因此中 文领域的评测基准必不可少.本节主要介绍4种不同的评测 基准.
专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复“CTM” 就可以获取《中文预训练模型研究进展》专知下载链接






