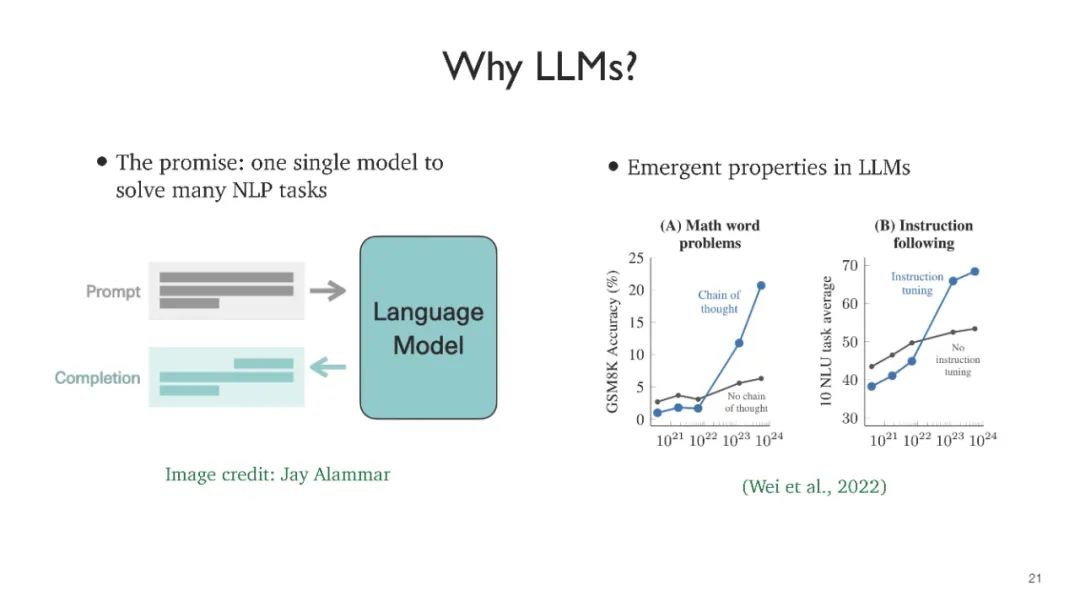
在过去3-4年中,大型语言模型(LLMs)彻底改变了自然语言处理(NLP)领域。它们构成了最先进的系统的基础,在解决广泛的自然语言理解和生成任务时无处不在。随着前所未有的潜力和能力,这些模型也带来了新的道德和可扩展性挑战。本课程旨在涵盖围绕预训练语言模型的前沿研究课题。我们将讨论它们的技术基础(BERT、GPT、T5模型、专家混合模型、基于检索的模型)、新出现的功能(知识、推理、少样本学习、上下文学习)、微调和适应、系统设计以及安全和伦理。我们将涵盖每个主题,并深入讨论重要论文。学生将被期望定期阅读和提交研究论文,并在结束时完成一个研究项目。 这是一门高级研究生课程,所有学生都应该上过机器学习和NLP课程,并熟悉诸如transformer等深度学习模型。
https://www.cs.princeton.edu/courses/archive/fall22/cos597G/
学习目标
-
本课程旨在帮助您在自然语言处理方面进行前沿研究,特别是与预训练语言模型相关的主题。我们将讨论最先进的技术,它们的能力和局限性。
-
练习你的研究技能,包括阅读研究论文,进行文献调查,口头报告,以及提供建设性的反馈。
-
通过期末项目获得实践经验,从头脑风暴到实施和实证评估,再到撰写期末论文。
课程内容:
引言 BERT T5 (encoder-decoder models) GPT-3 (decoder-only models) Prompting for few-shot learning Prompting as parameter-efficient fine-tuning In-context learning Calibration of prompting LLMs Reasoning Knowledge Data

参考论文:On the Opportunities and Risks of Foundation Models
作者:Percy Liang、李飞飞等 * 论文链接:https://arxiv.org/pdf/2108.07258.pdf
**摘要:**最近,斯坦福大学的 Percy Liang、Rishi Bommasani(Percy Liang 的学生) 、李飞飞等 100 多位研究者联名发布了一篇论文。在论文中,他们给大模型取了一个名字——「基础模型(foundation model)」,并系统探讨了基础模型的机遇与风险。「基础」代表至关重要,但并不完备。 论文正文分为四个部分,分别阐述了基础模型的能力、应用、相关技术和社会影响,其具体内容如下:
能力:语言、视觉、机器人学、推理、交互、理解等; * 应用:医疗、法律、教育等; * 技术:建模、训练、适应、评估、系统、数据、安全与隐私、稳健性、理论、可解释性等; * 社会影响:不平等、滥用、环境、法规、经济、伦理等。
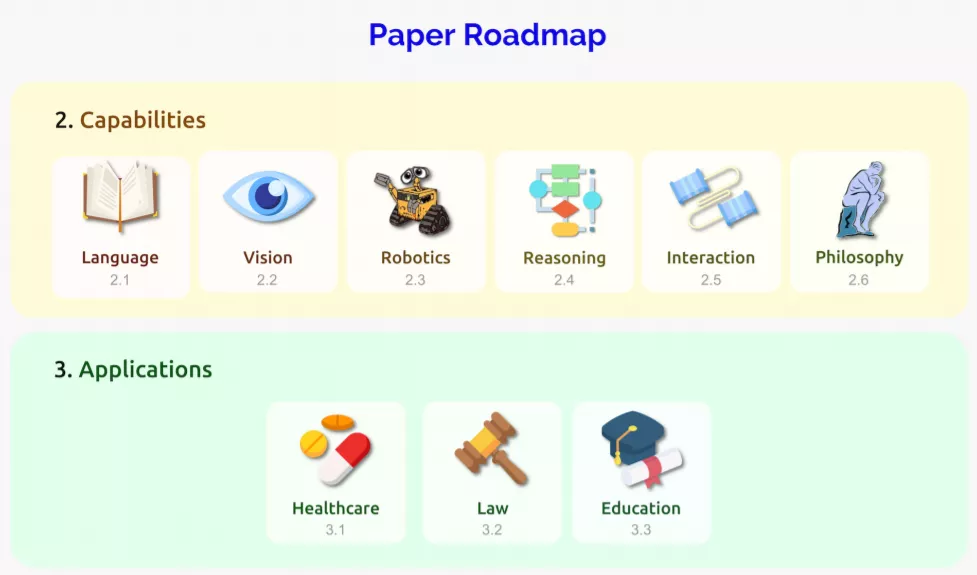
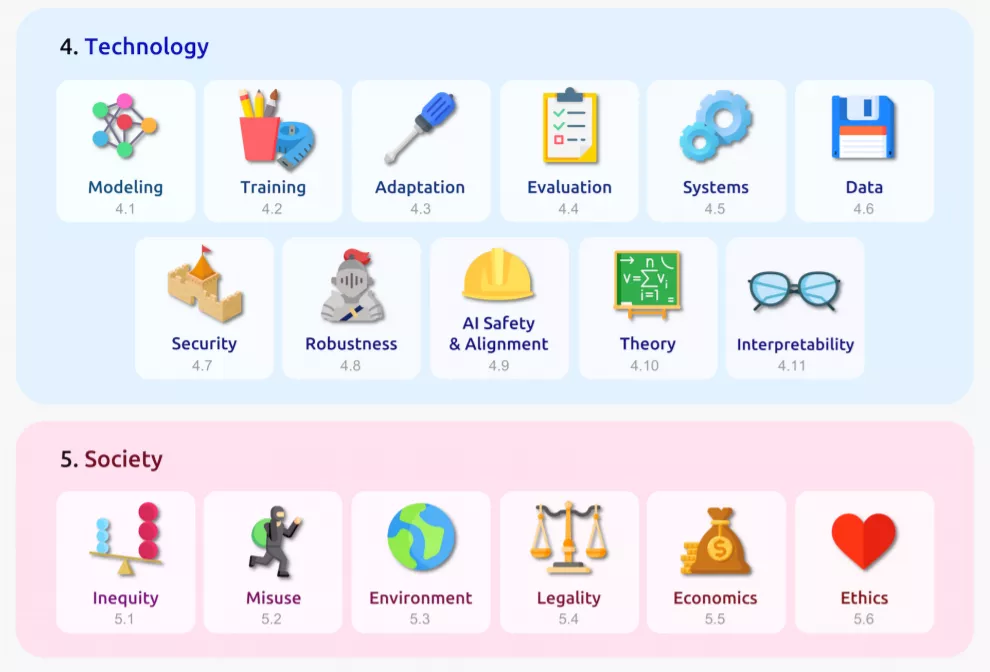
这篇论文的问世将为负责任地发展、部署基础模型提供一些借鉴。