【KDD2022-教程】深度搜索相关性排名的实践,74页ppt

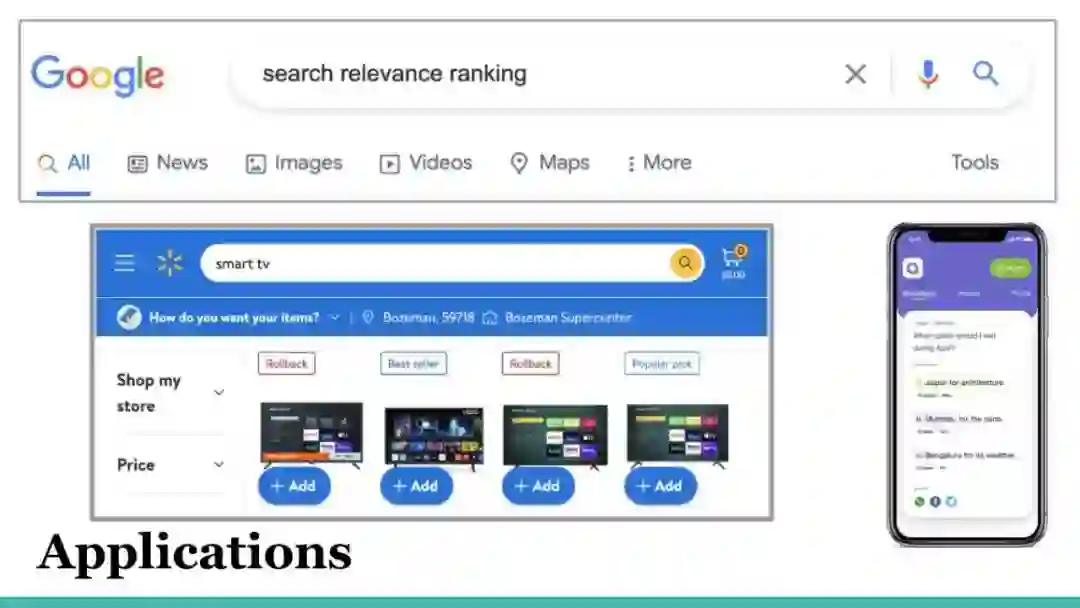
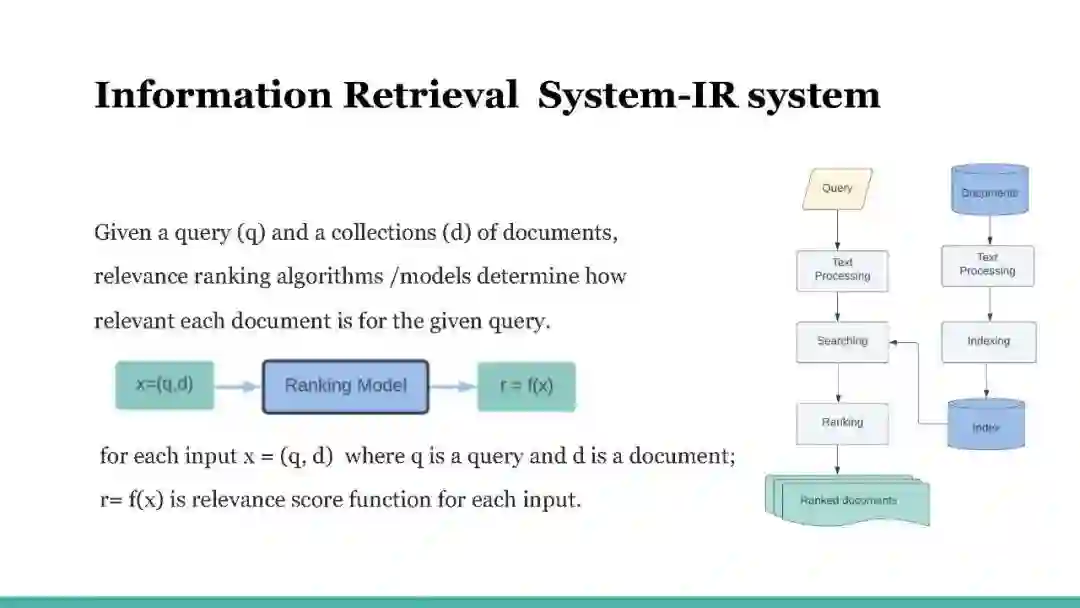
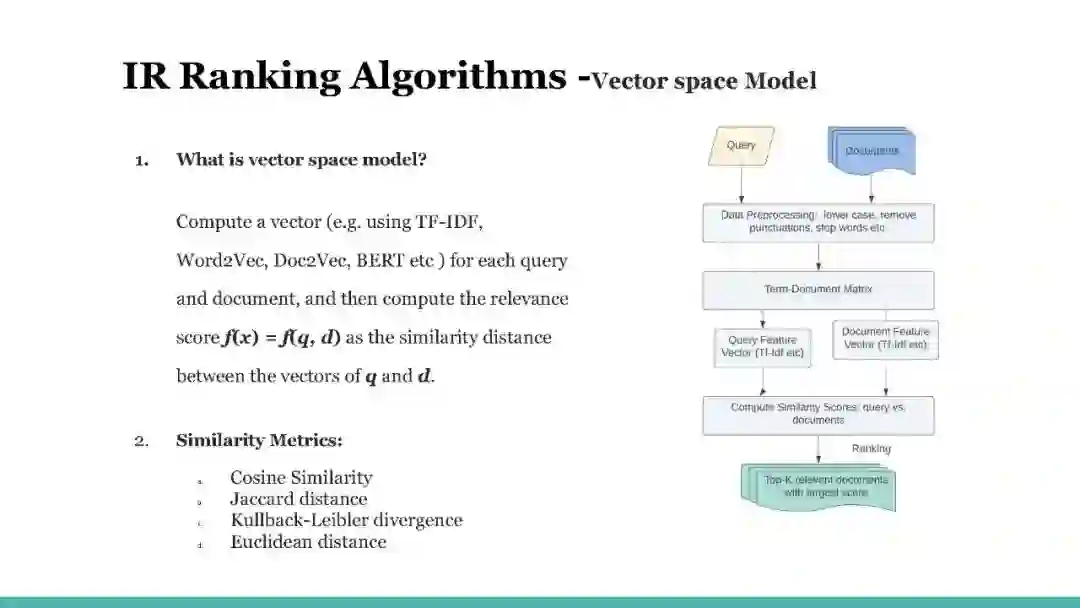
在本教程中,我们将概述搜索排名的实践,并演示各种经典和流行的排名算法,以帮助读者理解搜索相关性算法及其在现实世界中的应用。本教程大纲如下:搜索相关性排名介绍:在这一环节中,我们将概述信息检索[9]中的排名问题。回顾了排序函数的一些早期工作,并简要介绍了各种排序函数模型的历史。我们选择了一些关键的算法来使用真实数据解释和演示它们的排名表现。我们介绍了几个关键的性能指标来评估排名和在线指标。我们的实践课程涵盖了经典排名函数的实现。基于注意力的搜索相关性模型:在这一环节中,我们将概述序列模型的发展,然后讨论注意力机制。我们还将介绍Transformer架构,以及如何在搜索排名系统的上下文中利用其中一些架构。具体内容如下: (1) 我们介绍了序列模型(如RNN和LSTM)是什么,训练它们时所做的假设是什么,它们更适合于搜索排名系统的哪种数据集。(2)注意力/自注意力: 我们解释一般注意力机制。(3) Transformer:与上述两点类似,我们以真实的搜索排序和自然语言处理任务为背景来解释和激发Transformer架构。(4) 操作会话封面训练:注意力/Transformer模型。知识蒸馏的搜索相关性: 在这一环节,我们提供了一个介绍的深度结构化语义模型(DSSM)[3],已广泛采用在工业中,其质量和高效的架构。我们还介绍了最近的NLP突破,BERT[2]在对查询文档对进行评分方面明显优于DSSM及其变体。然而,我们表明,它的Transformer交叉层同时是昂贵的,因此它不允许离线预计算文档。为了连接两者,我们将我们提出的知识蒸馏[5]从教师BERT模型分享到学生模型。新的学习方法明显胜过传统的DSMM模型,从点击中学习。在实践环节中,听众接受了关于在开源数据集上搜索相关性的知识提炼的培训。提供的代码示例用于训练双塔学生模型,测试数据集用于听众体验教师和学生模型之间的度量差异。



专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复“DR74” 就可以获取《【KDD2022-教程】深度搜索相关性排名的实践,74页ppt》专知下载链接






