
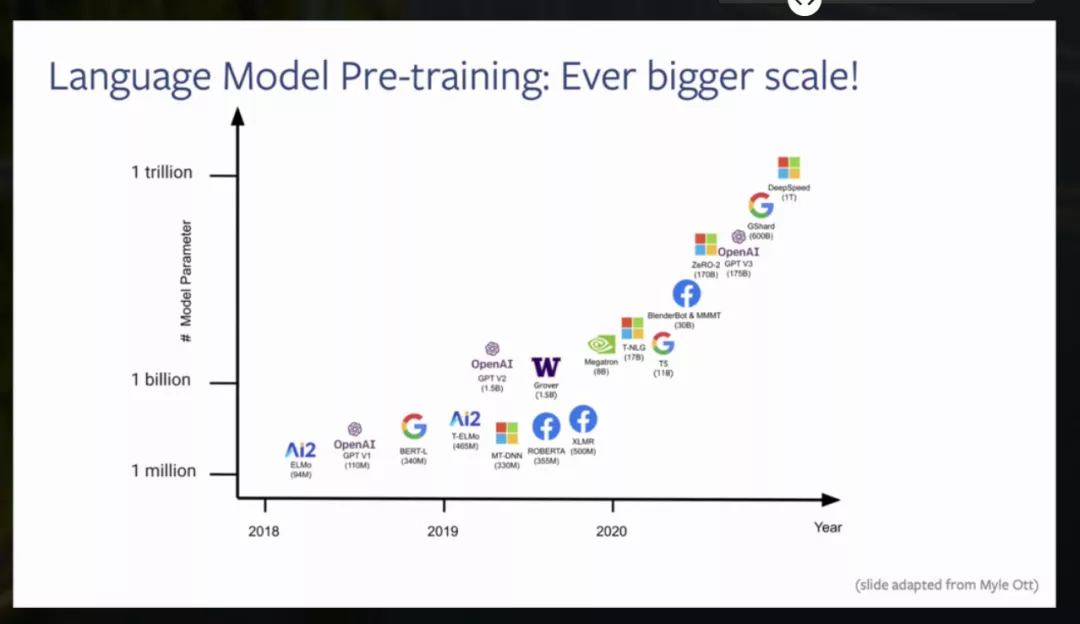
近年来,在大量原始文本上预先训练的大型语言模型彻底改变了自然语言处理。现有的方法,基于因果或隐藏的语言模型的变化,现在为每一个NLP任务提供了事实上的方法。在这个演讲中,我将讨论最近在语言模型预训练方面的工作,从ELMo、GPT和BERT到更近期的模型。我的目标是对总体趋势进行广泛的报道,但提供更多关于我们最近在Facebook AI和华盛顿大学开发的模型的细节。其中特别包括序列到序列模型的预训练方法,如BART、mBART和MARGE,它们提供了一些迄今为止最普遍适用的方法。
成为VIP会员查看完整内容
相关内容

Arxiv
11+阅读 · 2019年10月30日

相关VIP内容
相关资讯
相关论文
Arxiv
11+阅读 · 2019年10月30日