谷歌提出全新视觉-音频分离模型,解决鸡尾酒会效应

在鸡尾酒会嘈杂的人群中,尽管周围噪声很大,但人类依然能够屏蔽其他声音而将注意力集中在自己所关注的那个人的讲话内容上。这就是鸡尾酒会效应,这是人类与生俱来的“超能力”。
然而,在计算机科学中,将音频信号分离为各自独立的声源即自动语音分离,仍旧是一个具有挑战性的任务,并且是一个非常值得研究的问题。近日,谷歌研究团队发表了针对这一问题的论文,公布其最新研究成果,能够基于深度学习将一个单独的语音信号从混合的音频中分离出来。
在论文“Looking to Listen at the Cocktail Party”中,谷歌团队提出了一种基于深度学习的音频 - 视觉模型,该模型可以将一个单独的语音信号从混合的音频中分离出来,比入从其他语音信号和背景噪声中分离出来(译者注:这里的语音信号专指讲话或演讲这一类音频信息)。
在这项工作中,可以通过计算生成的新的视频,使原视频中的某个特定人物的语音得到增强,同时抑制其他所有的声音。该方法适用于所有包含单音轨的普通视频,用户只需要选择他们想要听的视频中人物的脸部。作者认为这个功能将会有广泛的应用,例如,视频的语音增强与识别,视频会议的通话降噪,改进助听器,尤其是在多人讲话的情况下这个功能显得更为重要。
该工作的亮点主要是将输入视频的音频和视觉信号相结合,使用混合信号进行语音分离。比较直观的解释是,讲话者嘴部的运动与说话时发出的声音应该是有所关联的,这个信息对识别音频信号应该与哪个讲话者相对应有很大帮助。
视觉信号不仅能显著提高复杂语音环境下的语音分离的效果(与单独使用音频信号进行语音分离相比,在论文中有详细的说明),这种方法还可以将分离的音轨与视频中的人物联系起来。
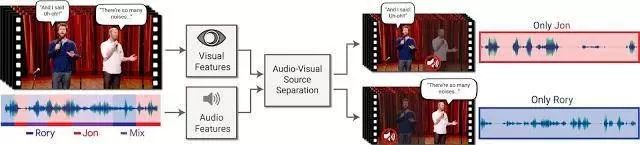
上图是该方法的工作示意图,输入是一个包含多人讲话的视频,由其他讲话者或者背景噪声决定哪个讲话者是感兴趣的讲话者。输出是分离后的音轨,每个音轨只含有一个特定的讲话者的声音。
为了生成训练样本,作者在 YouTube 上收集了包含 10 万个对话与演讲的高质量视频,组成了一个大型视频数据集。在这些视频中,作者提取了干净的语音片段(例如没有混合的音乐,观众的声音或者其他讲话者)和一些只包含单独讲话者的视频帧。这样就获得了额大约 2000 小时的视频片断,这些视频中每个讲话者都会出现在画面中并且没有背景噪声的干扰。然后作者使用这个干净的数据集合成“鸡尾酒会”——将这些独立的视频混合,包括混合讲话者的声音与从音频集中获取的非语音的背景噪声。
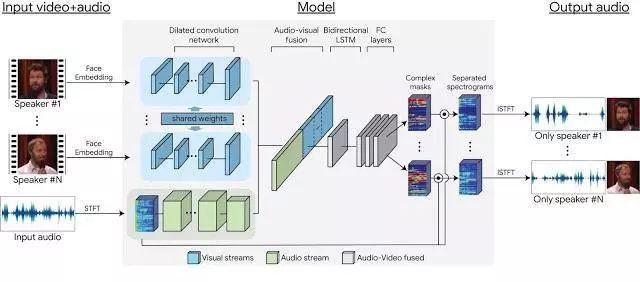
利用这些数据,作者成功的训练了一个基于多流神经网络的模型,该模型可以将合成的视频分离成单独的音频流,并且音频流与视频中的讲话者一一对应。网络的输入每帧中讲话者的人脸部分,以及其对应的音轨的声谱图。训练期间,网络独立地学习对视频以及音频信号编码,然后将它们融合成一种联合的音频 - 视觉表示。通过这种联合表示,网络学习输出一种时频掩模,时频掩模与输入的声谱图进行混合可以得到一种时域波形信号,每个波形信号只包含一个单独的讲话者的声音。下图是该模型的框架:
下面是一些语音分离与增强的结果,视频的第一部分是混合声源的片段,然后是分离后的结果。非目标讲话者的声音会被完全抑制或达到期望的抑制效果。
该方法可以用作语音识别和自动字幕生成的预处理。处理多声源视频对已知的自动字幕生成系统是一个巨大的挑战,同时将音频分离到不同的源有助于呈现更准确的易于阅读的字幕。
在上面的视频中可以看到使用了分离语音前后的字幕生成效果,自动字幕生成系统直接使用了 Youtube 的自动字幕功能。
在该团队的项目网站上可以看到更多的结果,同样还有和目前最好的一些方法的比较,其中包括仅使用音频的语音分离方法和最近的一些语音 - 视觉语音分离方法。
随着深度学习的发展,语音 - 视频分析在学术界受到了越来越多的关注。例如,UC 伯克利在同时期提出了一种自监督的语音分离方法;MIT 也提出了一种解决多目标声音分离(例如,分离视频中不同乐器的声音)问题的方法,进而在图像中定位出声源区域。
参考资料:
https://research.googleblog.com/2018/04/looking-to-listen-audio-visual-speech.html
论文原文:
https://arxiv.org/abs/1804.03619
项目演示网站:
https://looking-to-listen.github.io/
· END ·
推荐阅读:




