今天为大家带来的是发表在2022 IEEE International Symposium on High-Performance Computer Architecture (HPCA)上的一篇文章,LISA: Graph Neural Network Based Portable Mapping on Spatial Accelerators,它提出了一种使用图神经网络为空间加速器进行DFG映射的方法。
摘要
空间加速器(Spatial accelerators),如粗粒度可重构阵列(Coarse-Grained Reconfigurable Arrays,CGRA),提供了一种有效提升计算系统性能和能效的方法。这些依赖于高效编译器的加速器能够充分利用底层架构提供的并行化优势。目前,空间加速器的编译器是人工设计的,从时间到市场角度来看是一个巨大的挑战。这篇论文提出了一个可移植的编译框架,称之为LISA,它能够自动调整以为各种空间加速器生成高质量的映射。
1.引言
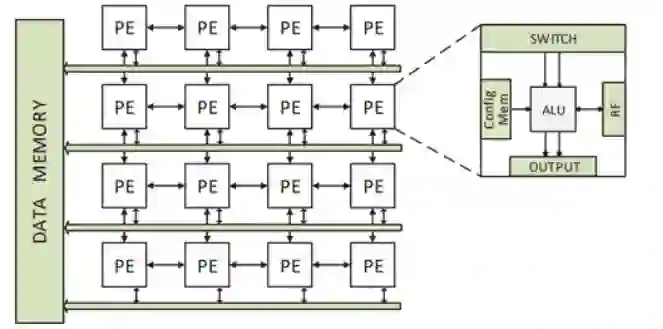
空间加速器是可编程的,包含诸如ALU(Arithmetic Logic Unit,算术逻辑单元)和MAC(Multiply Accumulate,乘法累加)的处理单元(Processing Elements,PE)、片上存储和片上网络。图1展示了一个4×4的CGRA,它是空间加速器的典型例子。
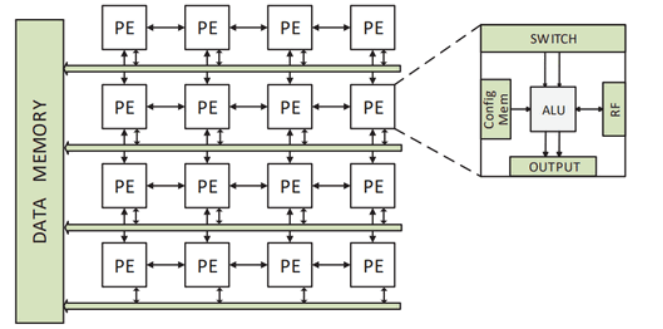
图1.空间加速器的例子:粗粒度可重构阵列本文提出了一个LISA框架,即空间加速器的学习诱导映射(Learning Induced mapping for Spatial Accelerators),它能够为不同加速器和应用组合提供可移植的编译器。主流观点认为GNN不能为给定DFG直接生成映射,但标签可以作为桥梁弥补它们之间的差距。GNN聚合DFG属性以导出标签,这些标签告知编译器正确的放置位置和路由决策,以此生成高质量映射。对于一个新的加速器,可移植编译器重新训练GNN模型,以根据加速器特征调整标签。

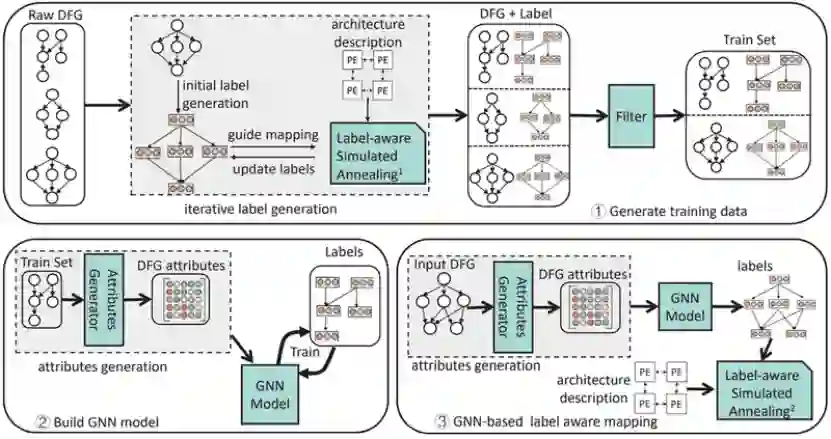
图2.LISA的总体结构图2展示了LISA框架的总体结构,它包含三个部分:为GNN模型生成训练数据,构建GNN模型,基于GNN的标签感知映射。
2.DFG标签设计和映射
现在介绍标签的类别以及如何在映射中使用这些标签。标签描述了结点和边应该如何映射到加速器上。本文设计了一个标签感知的编译器来确定位置和路由,并生成空间加速器上的高质量映射。
2.1标签
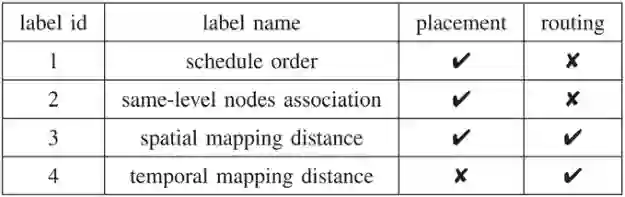
表1总结了指导编译器的四种标签以做出正确的放置和路由决策。 表1.标签的类别及其作用
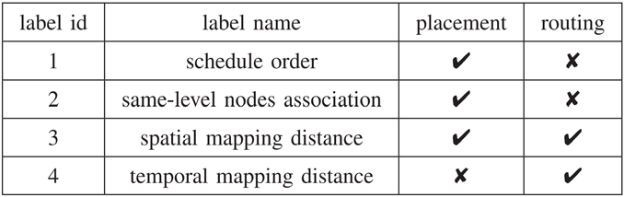
Schedule order(调度顺序)表示DFG结点的执行顺序。它比拓扑或类似的顺序包含更多信息。例如,有更多孩子的结点应该提前调度到多个目的地,而拓扑顺序仅由结点依赖决定。本文的调度顺序包含了全局DFG结构信息,能使这些结点更早被调度。Same-level nodes association(同层结点关联)定义了没有数据依赖关系的同层结点之间的空间距离。如果具有相同ASAP值的结点拥有相同的祖先或子孙结点,它们就被定义为同层结点。因为这些结点的调度时间通常更近,这些标签要表示这些同层结点能够被放置的位置的距离。Spatial mapping distance(空间映射距离)指示了DFG边在映射中的空间距离。本文需要一个标签来描述DFG边的空间映射距离,从而弄清楚DFG结构特征是如何影响父结点和孩子结点的放置位置的。Temporal mapping distance(时间映射距离)指示了DFG边在映射中的时间距离。孩子结点不一定总是在一个父结点之后立即执行,因为这个孩子结点可能还有其他父结点。本文使用时间距离估计边所需的路由资源。最后三个标签描述了结点间的时间和空间距离。计算空间距离的方法依赖于加速器。对于图1所示的2D网格加速器,本文可以使用曼哈顿距离(Manhattan distance)。时间距离按映射中时间维度(周期数)的距离计算所得。
2.2标签感知映射****
编译器可以使用标签的组合来决定放置位置和路由选择。 算法1.标签感知的模拟退火算法

算法1展示了本文提出的标签感知的模拟退火算法。本文首先放置去映射的结点然后再路由数据。该算法在第一次迭代中生成初始映射,因为所有结点在初始时并未映射。如果所有结点都已映射,该算法随机选择一些结点去映射(第2行)。调度顺序决定放置顺序(第3-4行)。其他三个标签决定路由优先级和放置选择。当选择候选PE来放置结点时,本文使用的是组合了三个标签的代价模型(第6行)。每一个候选PE的代价是它实际映射距离和标签期望映射距离的差值之和。由于放置位置的细微差别能够导致完全不同的映射,所以代价最小的候选PE不一定是最合适的。因此本文使用了正态分布来选择基于代价的候选PE(第7-8行),以保证低代价的候选被选中的机会更高。正态分布的偏差参数决定了分布的方差。为决定结点的路由顺序,本文使用了时间映射距离标签的和,它能够表示一个DFG结点所需的路由资源(第9行)。注意,需要更多路由资源的结点会首先路由。与原始SA方法相比,这个标签感知方法只改变了放置位置选择和路由优先级。
3.用于DFG标签生成的GNN模型
用GNN导出标签的关键挑战是:(a)为GNN模型提供有效的图属性,(b)使用这些属性去导出用于描述如何映射DFG的标签。然而,要捕捉DFG结构和映射影响之间的关联并不容易;因而标签值是难以计算的。因此使用GNN导出标签不同于传统的GNN分析。为了从DFG中导出标签,本文首先需要给GNN提供图属性。导出一个标签需要多个图属性。在图上(如社会网络)的传统GNN分析通常有自然属性用来分析。然而,DFG没有这样的属性,因为结点通常只有操作类型属性。本文的方法是设计一个DFG的属性生成器以生成相关的属性。这个属性生成器使用传统的图算法,用图属性来表示DFG结构特征。这些图属性会影响位置放置和路由决策。例如,一个拥有多个孩子的DFG结点需要足够多的路由资源。因此,该结点需要一个更高的调度顺序。同时,为了给孩子结点留下足够的路由依赖的空间,结点不应该放置得离它父结点很近。本文为每个标签设计了一个GNN,模型参数能够从每个网络的公式中推导出。生成一个标签并不需要全部属性,本文直观地为每个GNN选择相关属性。Schedule orde****r(调度顺序):该标签与数据依赖的复杂度和相邻结点(父结点与子结点)的调度顺序有关。在处理完当前结点的属性后,需要将变化传播给它的邻居。Same-level nodes association(同层结点关联):这个标签描述了两个同层结点之间的空间距离。两个同层结点与其共同祖先或子孙的最短距离,会影响它们之间的空间映射距离。同时,同层结点与它们共同祖先或子孙结点之间的结点数目,也会影响距离,因为中间结点越多,就需要越多的PE来调度。Spatial mapping distance(空间映射距离):这个标签描述了一条边的空间映射距离。该距离会受到其他依赖结点的影响。例如,如果边的源结点有很多邻居,则它就需要更多的路由资源,因为这些邻居需要被放置在“较远”的PE上以留出足够的空间进行路由。Temporal mapping distance(时间映射距离):这个标签与边附近的DFG结构复杂度有关。本文使用属性生成器生成的所有边属性和多层感知器(MLP)按下式处理这些边属性。
4.实验评估
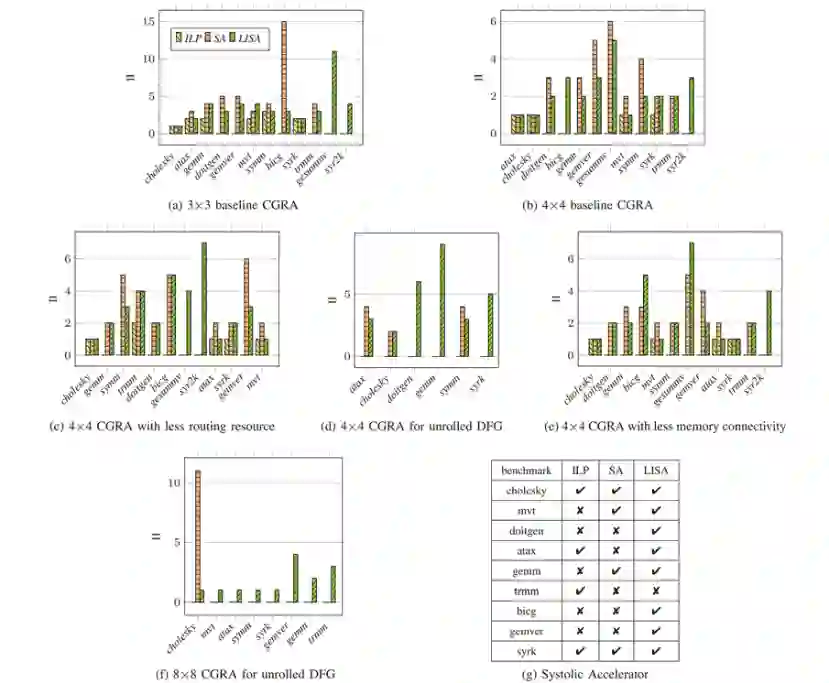
本文在多个维度对LISA进行了评估:映射质量、编译时间、可移植性、以及本文映射器和GNN模型不同组件的效率。 Performance(性能):图3在不同架构和基准程序上展示了使用II值的映射质量(II值越小,性能越好)。本文使用了PolyBench中CGRA-ME支持的12个DFG,排除了不能被任何方法映射的组合。总的来说,图3包含了71种基准程序和加速器的组合。除了脉动加速器上的trmm之外,LISA几乎可以映射所有的组合。但是ILP和SA只能映射71种组合中的23和49种。因此,LISA能够映射ILP所不能映射的48种组合,以及能映射SA所不能映射的23种组合。
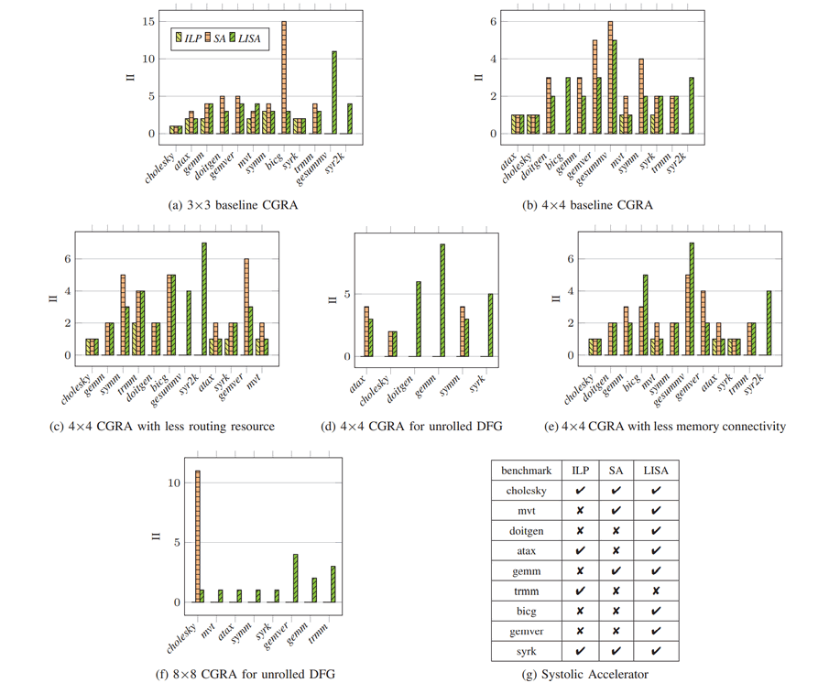
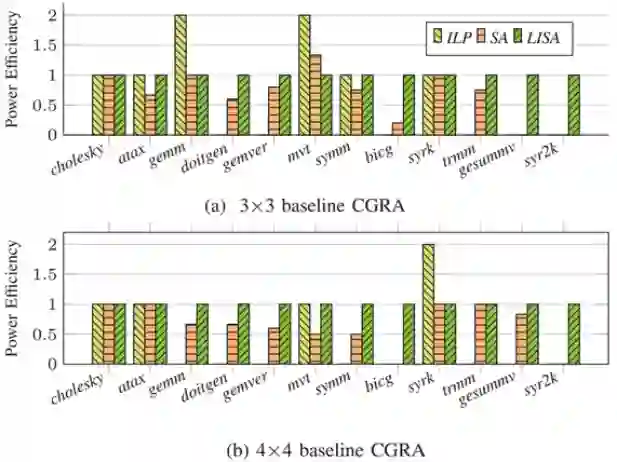
图3.LISA、ILP、SA性能对比****Power Efficiency(能效):图4展示了在3×3基准和4×4基准CGRA上能效的对比。
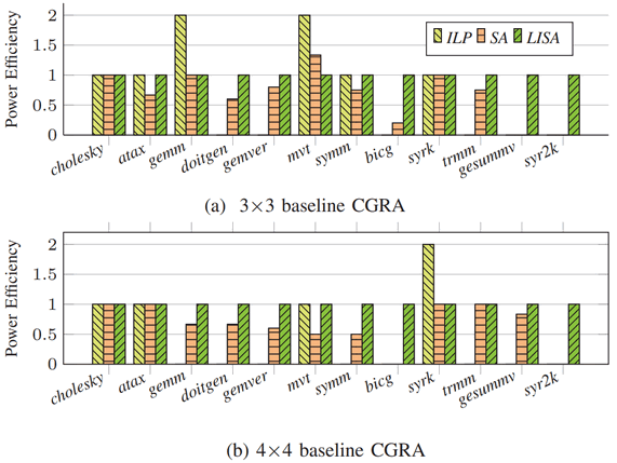
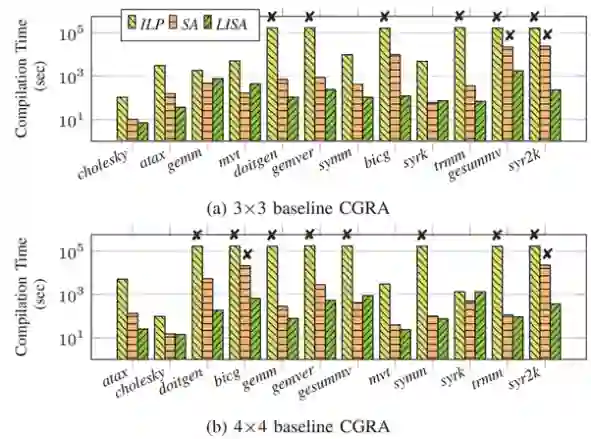
图4.基准CGRA上的能效对比****Compilation Time(编译时间):图5展示了三种方法在3×3基准和4×4基准CGRA上编译时间的对比。
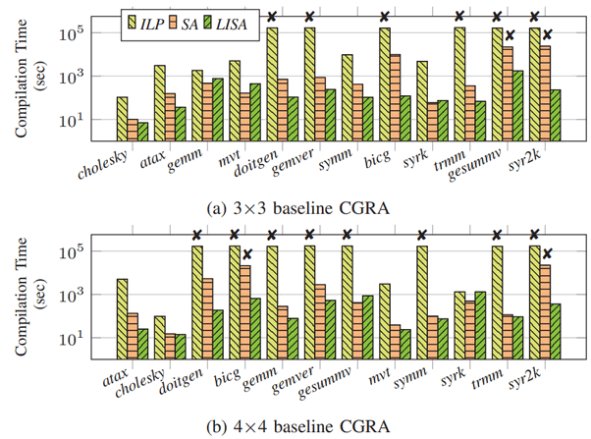
图5.基准CGRA上的编译时间对比总之,对于几乎所有应用和加速器组合,LISA在编译质量(性能、能效)和编译时间上都要明显优于ILP和SA方法。得益于全方位的全局视图,LISA能在空间加速器、复杂DFG和处理有限路由资源间取得平衡。由于GNN模型能够通过训练为各种加速器生成合适的标签,LISA能在各种架构上生成高质量映射,为空间加速器创建一个真正可移植的编译器框架。
5.结论
为空间加速器设计一个高质量的编译器需要大量的人工工作。这篇文章提出了一种可移植的编译器框架LISA,它能为各种加速器自动生成高质量映射。为此,它使用抽象标签来表示DFG结构对加速器映射的影响,为映射提供一个全局视图,并使用GNN模型为各种加速器自动导出标签。最终的实验表明,在众多加速器上,LISA的性能明显由于ILP和基于模拟退火方法的映射,证明了这篇文章所提出方法的有效性。