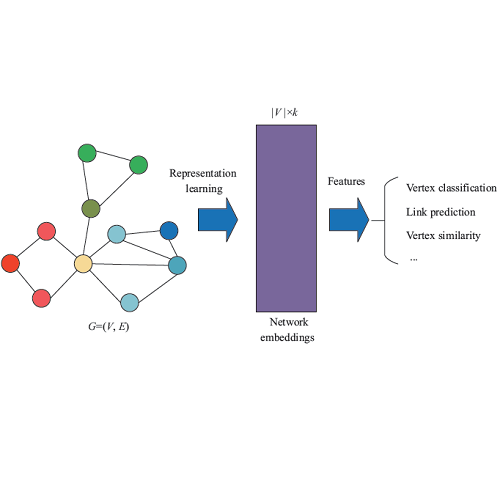
论文浅尝 | 采用成对编码的图卷积网络用于知识图谱补全

笔记整理:姚祯,浙江大学在读硕士,研究方向为知识图谱表示学习,图神经网络。
论文引用:Liu S, Grau B, Horrocks I, et al. INDIGO: GNN-based inductive knowledge graph completion using pair-wise encoding[J]. Advances in Neural Information Processing Systems, 2021, 34.
Motivation
基于嵌入的方法通常是在向量空间中表示KG,然后对于结果向量应用预先定义的评分函数来进行知识图谱补全。但是这种方法的弊端就是对于训练过程中存在的实体,可以有很好的训练效果,但是对于在训练过程中没有出现的实体,这种方法的效果就会变得很差。
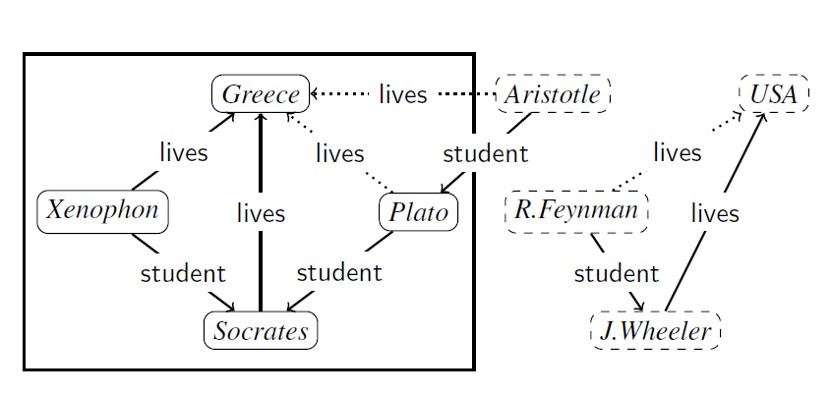
而在实际应用中,KG通常是在变化的,因此很容易出现在训练过程中并未见过的实体,会使得效果很差。例如在图中,实线部分是训练集,虚线部分是测试集。对于(Plato, lives, Greece)这一三元组,因为Plato,lives,Greece这三个向量都在训练过程中进行了反向传播得到了合理的向量表示,因此在链路预测的过程中很容易预测成功。但是对于(Aristotle, student, Plato), (R.Feynman, student, J.Wheeler),(J.Wheeler, lives, USA)这三个三元组,因为在训练过程中并未出现,因此它们的向量仅仅是随机初始化的向量表示,此时采用基于嵌入的方法,几乎不可能找到正确的预测结果。因此文中将这种基于嵌入的方法称为transductive mothed。例如TransE,RotatE。
基于图神经网络的方法可以捕获模型的结构特征,GCN本身基于图像的对称性,即有相同邻居的节点会有相同的值。在相同的结构下是不变的,可以捕获结构的一般形式。因此文中将这种基于图神经网络的方法成为inductive mothed。例如RGCN。但是这种基于卷积的方法仍然没有拜托对向量定义打分函数的方式来进行评估,作者提出了一种新的方法,通过将KG以透明的方式(transparent)编码到GCN中,并在GCN的最后一层直接解码得到向量表示而不需要额外的评分函数。
Mothed
•Encoding
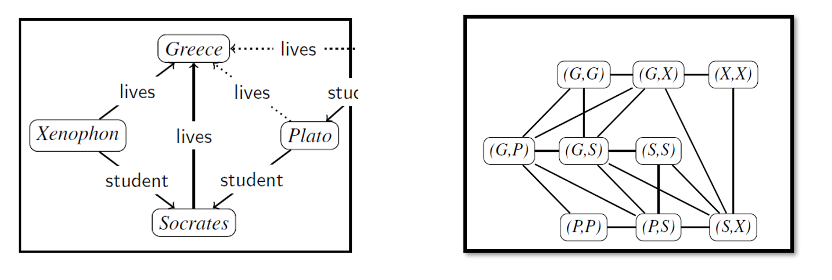
作者首先定义了节点表示图,节点表示图是由KG编码而来,KG中的节点表示实体,边表示关系。而在节点表示图中,每个节点表示一个实体对,在原图中,如果存在一个节点或者两个节点之间存在一条边,那么在节点表示图中会有一个节点,如(Plato,lives,Greece)会有三个节点,并且每个节点会生成一个向量表示,向量的维度为关系数量的2倍。用来表示两个节点之间存在何种关系,同样以(Plato,lives,Greece)为例,编码在图中的节点为(G,S),(G,G),(S,S)。作者规定节点对的编码是以两个单词的字典序作为前后顺序,也就是说一个节点对仅存在唯一的节点表示。对于(G,S)节点来说,其向量表示为(0,1,0,0)。因为图中有两个关系lives和student,因此表示向量的维度为4。第一个零表示不存在(Greece,lives,Plato)这样的关系,因此编码为0;同理存在(Plato,lives,Greece)这样的关系,因此编码为1。后面两个依次表示不存在(Greece,student,Plato),(Plato,student,Greece)这样的关系。
定义完节点,作者对图中的边进行了定义,对于每一个节点中出现的实体,如果在另一个节点中出现,那么这两个节点之间就会存在一条边。同样以(G,S)为例,因为出现了G节点,因此首先和存在G实体的所有节点相连,之后再和存在S实体所有节点相连。这样就完成了作者提出的节点表示图。在这种方式下编码的特征向量和KG之间的三元组建立了一对一的对应关系。并且使得GCN可以更加容易地学习到图中的结构模式。例如,这样的结构模式更容易捕获到具有师生关系的三个人大概率生活在同一个国家这样的逻辑。实质上作者是用一种比较巧妙的方式,更好地聚合了一个知识图谱中实体的多条邻居信息。对于节点表示图的复杂性,作者进行了理论分析,INDIGO编码图的边的数量是随着KG中实体数量呈幂级增长,不过考虑到现实中的知识图谱大都是稀疏图,因此可以将节点的最大出度视为一个常数,此时INDIGO编码图的边的数量是随着实体数量线性增长的。
•GCN
模型的GCN模块采用了最为简单的图卷积神经网络的形式,用于聚合相邻节点的embedding更新自身的节点表示。损失函数也采用了最常见的交叉熵损失函数,进行反向传播。
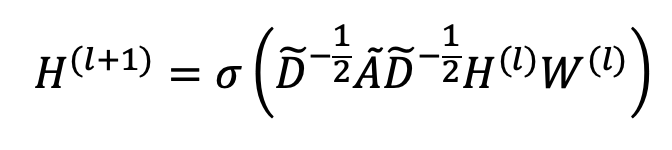
其中
•Decoding 解码过程可以看作编码过程的镜像,作者提到在GNN的最后一层中会输出每个节点的向量表示,由于最后是经过了Sigmod函数输出的,因此向量的范围在(0,1)之间被定义为预测的可信度。所以在解码过程中,作者规定了一个判别值,即当值大于0.5时为1,值小于0.5时为0。
Experiment
数据集、基线、评估指标
•数据集
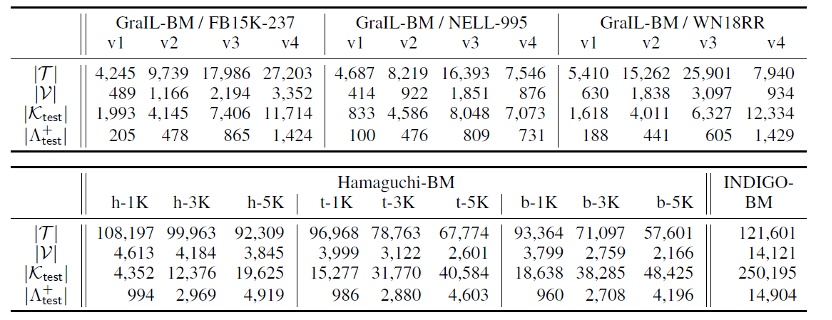
GraIL-BM共有12个数据集,分别由FB15K-237,NELL-995和WN18RR随机采样一些实体作为种子,然后取周围的k-hop邻域的并集得来。
Hamaguchi-BM共有9个数据集,由WN11数据集中随机采样1k,3k,5k个三元组的头实体、尾实体或头尾实体对作为不可见实体集划分而来。
INDIGO-BM作为该论文提出的数据集是由FB15K-237数据集而来,首先通过Freebase语义网对FB15K237进行扩充,随后采样得到1000个三元组将其所包含的所有实体设置为不可见实体集。将不存在不可见实体集的三元组集合按9:1的比例分成训练集和验证集。剩下的部分作为测试集,整体的步骤和Ham-BenchMark数据集生成方法类似。
•Baseline
作者选用R-GCN作为最基础的Baseline,Grail和Ham同样是针对inductive推理提出的模型,它们对于不可见实体在预测过程也具有推理能力,同样作为实验的baseline。
•评价指标
评估指标包含:precision,recall,ACC,AUC,e-Hits和r-Hits。定义如下:
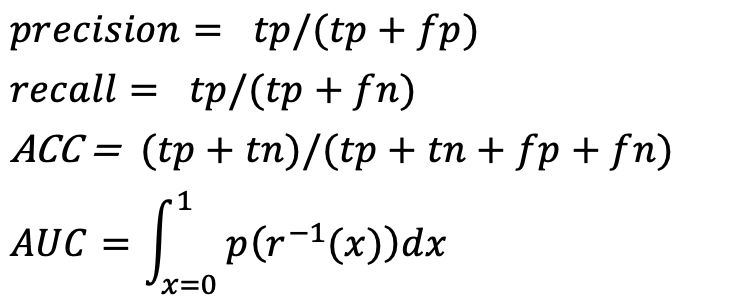
AUC表示精度找回曲线积分,定义精度召回图以精准率precision为y轴,以召回率recall为x轴,对于给定阈值θ,都会有坐标轴上的点(r(θ),p(θ)),其中r(θ)为召回率,p(θ)为准确率。
e-Hits@3表示实体预测中正样本置信度排名前三的比例。
r-Hits@3表示关系预测中正样本置信度排名前三的比例。
•实验结果
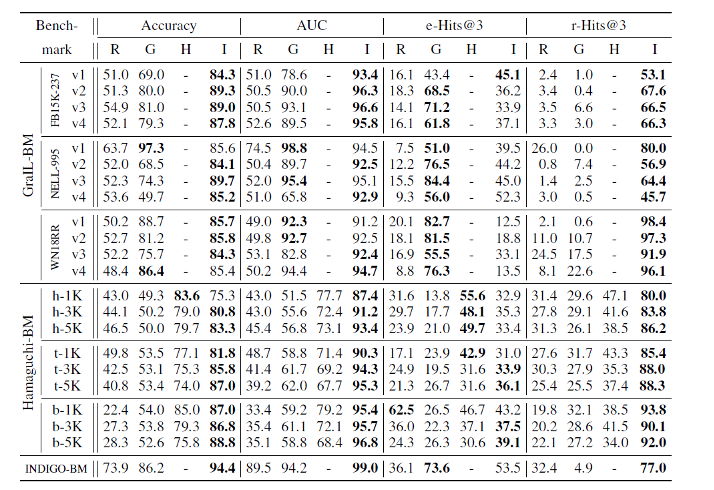
GraiL模型提出了12个benchmark,Ham模型提出了9个benchmark。再加上作者提出的一个benchmark,一共有22个数据集。可以看到在ACC上模型在19个数据集上达到了SOTA,在AUC上模型在18个数据集上达到了SOTA,对于实体命中率,模型效果比较差,仅5个数据集上达到了SOTA。关系命中率模型效果很好在所有的数据集上都达到了SOTA。作者认为传统的的GCN模型在负采样的过程中随机替换了实体,这会被认为是对于正确实体的“偏见”。INDIGO的抽样策略中不存在这种“偏见”,因此导致了训练性能的降低。
Summery
本文提出了一种新的图编码方式,可以将KG中的实体对和关系编码到图卷积网络中,可以用于链接预测任务,并且不依赖打分函数评估预测的准确性。大量实验证明这种方法是有价值的,通过inductive推理可以对于训练集中没有见过的实体保持一定的准确率。
OpenKG
OpenKG(中文开放知识图谱)旨在推动以中文为核心的知识图谱数据的开放、互联及众包,并促进知识图谱算法、工具及平台的开源开放。

点击阅读原文,进入 OpenKG 网站。