AAAI22 | 面向图数据的对抗鲁棒性研究
题目:面向图数据的对抗鲁棒性研究(Unsupervised Adversarially Robust Representation Learning on Graphs)
作者:许嘉蓉(复旦大学),杨洋(浙江大学),陈俊儒(浙江大学), 江鑫(UCLA),王春平(信也科技),卢建刚(浙江大学),孙怡舟(UCLA)
会议:AAAI Conference on Artificial Intelligence, 2022
论文简介
无监督/自监督的图预训练模型近几年受到了众多关注,并且可以推广到各种不同的下游应用中。然而,图预训练模型的对抗鲁棒性仍未被探索。并且,大多现有研究只考虑了有监督学习下端到端图模型的鲁棒性,它们对标签信息的依赖在很大程度上限制了应用范围和可用性。例如,在没有标签的下游任务(如社交网络中的社区识别任务)中,这些模型往往表现不佳。此外,针对不同的下游任务训练多个图模型不但成本较高而且很不安全。相对而言,如图1所示,在无监督的图预训练框架中,我们只需要一个鲁棒的图编码器就能够有效防止对抗风险传播到下游任务中,并且图编码器学习得到的鲁棒图表征可以适用于不同的下游应用中,比如节点分类、链接预测和社区识别等。
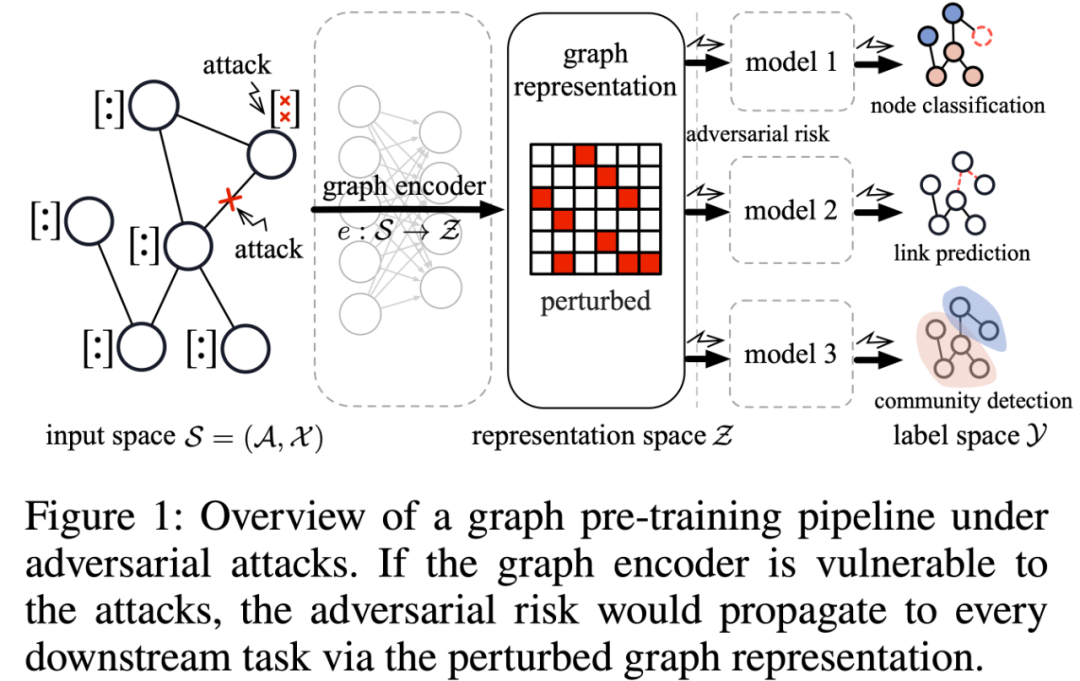
图1:对抗攻击下的图预训练框架
研究无监督图预训练模型的鲁棒性时,存在许多有趣但具有挑战性的问题。在以往的研究中,模型的鲁棒性通常定义在标签空间上,即现有网络鲁棒性度量需要依据样本的预测结果或标签进行计算,并不适用于本文的无监督设置。而在无监督图表征模型中,如何在表征空间上定义鲁棒性度量要第一个挑战。
为了应对上述挑战,文章首先提出了一个基于信息论的图编码器鲁棒性衡量指标:图表征脆弱性(graph representation vulnerability, GRV)。其次,文章将鲁棒性学习问题形式化为一个优化问题,保证了图编码器的强表征能力和高鲁棒性。但是,如何有效地计算或逼近该优化问题的目标函数是要第二个挑战。该挑战的难点在于:一方面,优化问题的目标函数非常难解;另一方面,如何在联合输入空间(由网络结构和节点特征组成)中描述攻击能力并确定扰动边界也同样棘手。
为了解决以上问题,文章采用概率分布之间的 Wasserstein 距离来量化攻击能力,并提供了一个搜索攻击策略的高效近似方案。其次,文章采用投影梯度下降法(projected gradient descent, PGD)的变种来解决所提出的优化问题。 最终,本文在对抗环境中能够学得一个高质量的鲁棒图编码器。此外,文章进一步探索了GRV和下游任务分类器的鲁棒性之间的理论联系。为了验证所提出模型的有效性和实用性,本文将学习到的鲁棒图表征应用于三个不同的下游任务中,与最优基准方法相比,本文提出的鲁棒图表征模型在节点分类、链接预测和社区识别任务中分别提升了+1.8%、+1.8% 和 +45.8% 的性能。
图表征脆弱性
本文认为如果攻击前后的网络和其表征之间的互信息足够接近,那么图编码器就足够鲁棒。文章首先提出图表征脆弱性(graph representation vulnerability, GRV)来量化无监督图编码器的鲁棒性,GRV定义如下:
其中,
优化问题
本文通过以下优化问题对模型鲁棒性和表征能力进行权衡:
但是实际情况下,“最鲁棒”的图编码器(即GRV=0)通常不是最理想的。举例来说,“最鲁棒”图编码器的一个实例为常量映射(constant map),即无论图编码器的输入是什么,它总是输出相同的表征,但是这显然是文章想要得到的鲁棒图编码器。因此,一个“足够鲁棒”的编码器已经绰绰有余了,甚至是一个更好的选择。由此,文章添加了一个软间隔(soft-margin),得到以下优化问题:
图表征脆弱性和标签空间的理论联系
本节为图表征脆弱性和下游任务鲁棒性(以AG为例)建立了如下理论联系:



实验结果
不同下游任务中模型的对抗鲁棒性:如表2所示,文章提出的模型在节点分类、链接预测和社区识别任务上分别比最优基准方法平均高出了+1.8%、+1.8% 和+45.8%。
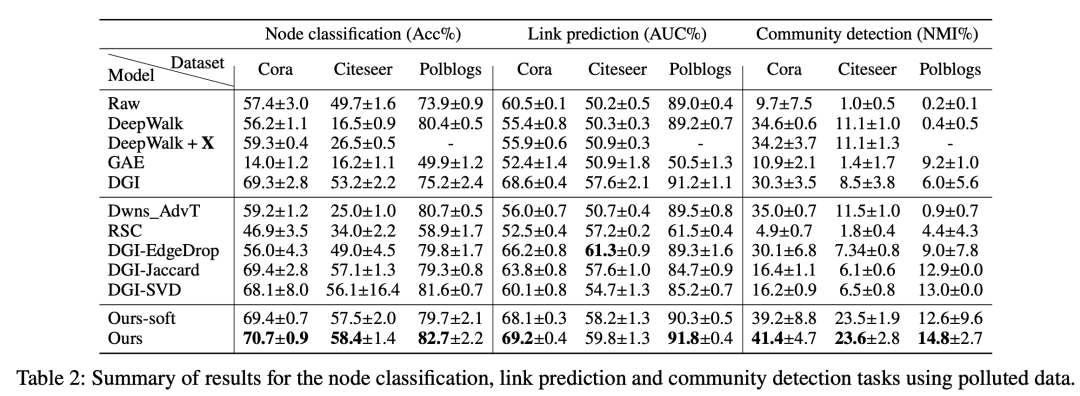
表2:节点分类、链接预测和社区识别任务中的对抗鲁棒性
不同攻击强度下的模型鲁棒性:如图2所示,文章提出的模型在不同的攻击强度下始终优于基准方法。
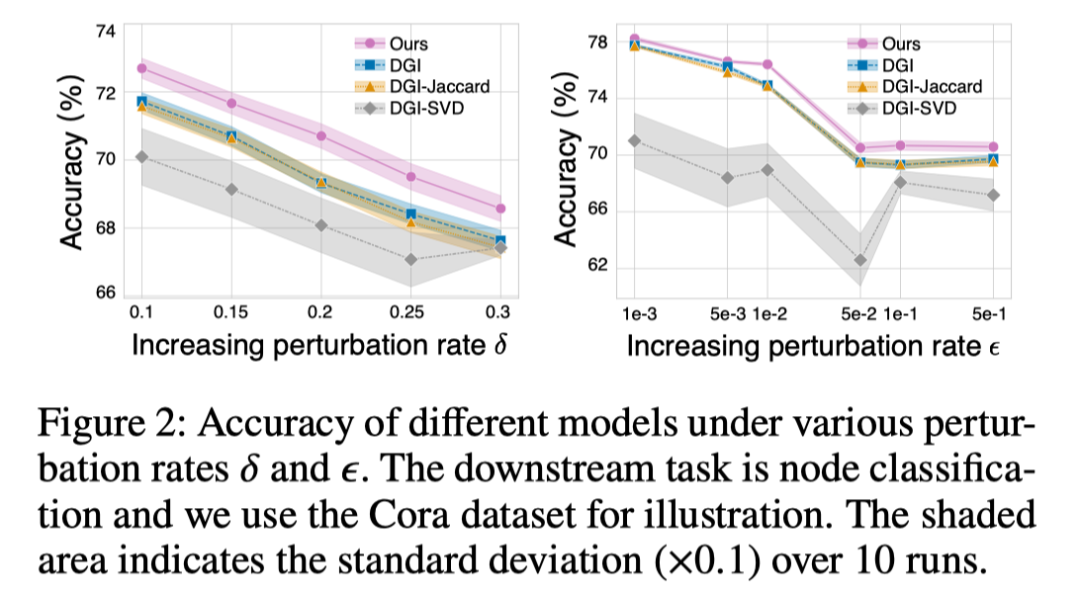
图2:不同攻击强度下的节点分类性能
不同攻击策略下的模型鲁棒性:在实际场景中,防御端往往对攻击者的攻击策略一无所知,因此探讨模型在不同攻击策略下的鲁棒性十分重要。表3的结果佐证了文章提出的模型能够进一步抵御不同的攻击策略。
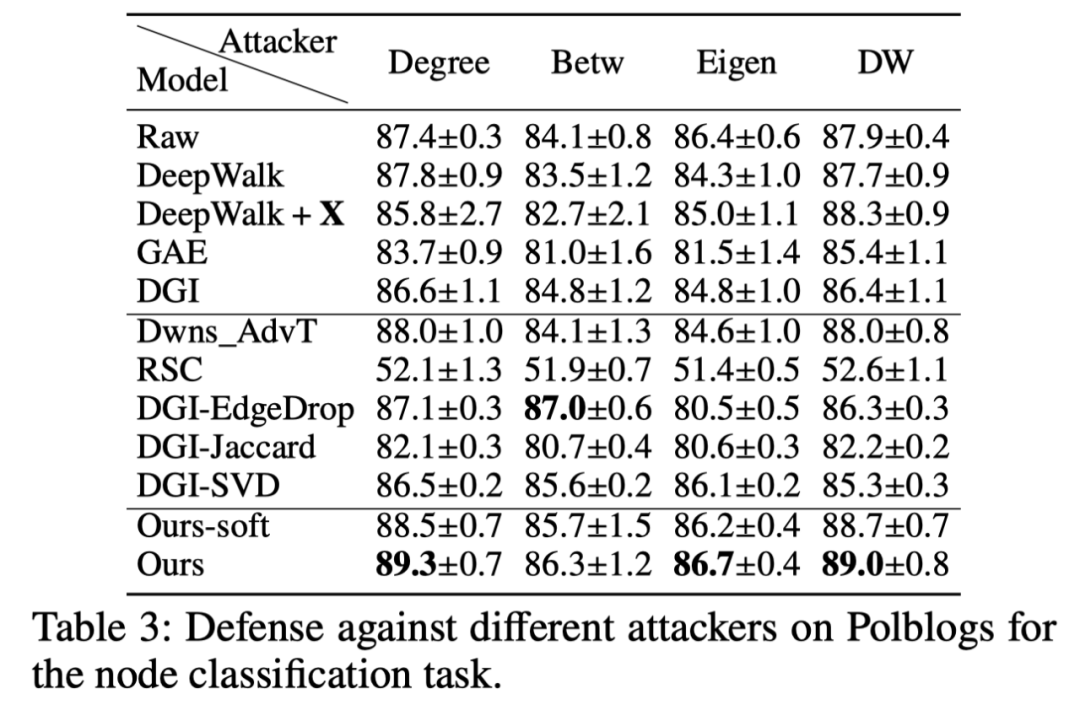
表3:不同攻击策略下的节点分类性能
