
作者 | 黄锋审核 | 付海涛

今天给大家介绍腾讯AI Lab赵沛霖博士团队以及德克萨斯大学阿灵顿分校黄俊洲教授团队、深圳大学欧阳乐教授团队近期(20220922)上传到ArXiv上的论文“MARS: A Motif-based Autoregressive Model for Retrosynthesis Prediction”。这篇论文将逆合成预测问题建模为图生成问题,并提出新的端到端训练的自回归模型。标准数据上的实验证明,对比于SOTA方法,所提出的模型有了重大提升。
方法
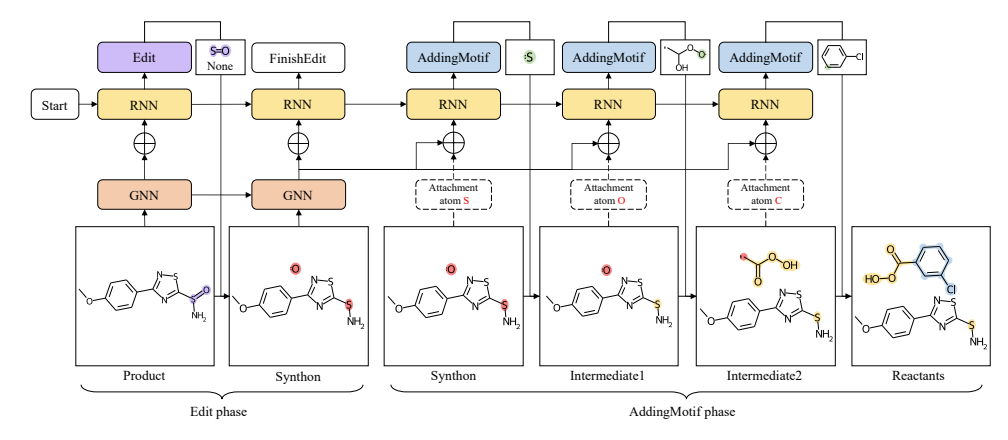
上图展示了这篇论文提出的方法的反应物生成过程。Edit 和 AddingMotif 指图形转换操作,其中 Edit 阶段描述从产物到合成子的键和原子变化,并起到反应中心识别的作用,而 AddingMotif 阶段通过向合成子添加适当motif来进行合成子补全。输入分子图由图形神经网络(GNN)编码,而递归神经网络(RNN)则按顺序预测图形转换操作。在 Edit 阶段,RNN 预测一系列 Edit 操作,直到 FinishEdit 指示 Edit 阶段的结束以及 AddingMotif 阶段的开始。在 AddingMotif 阶段,RNN 依次添加motif,直到没有附着原子(用粉红色突出显示)留下。在上图示例中,第一个 Edit 操作应用于 S=O 键,新键类型为 None,表示删除键。对于 AddingMotif 操作,motif 中的接口原子(绿色)和 合成子/中间产物中的附着原子表示相同的原子,并在将 motif 附加到合成子/中间产物时合并为单个原子。
转换路径构建
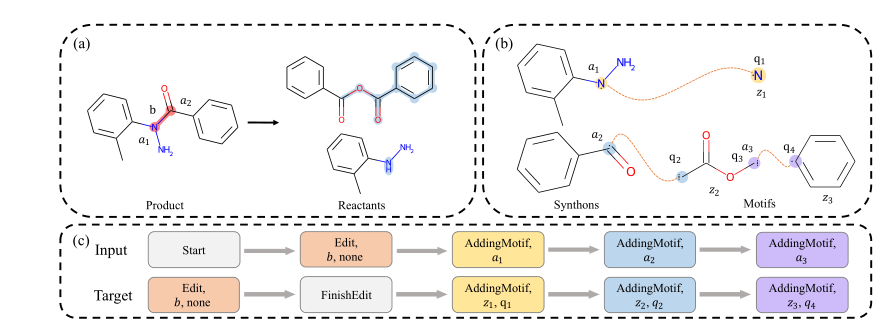
序列地模拟逆合成过程需要将其转化成序列。首先将逆合成看作两个阶段,即上述Edit阶段和AddingMotif阶段。前者用三元组的形式定义token,(编辑行为,编辑对象,编辑状态),例如上图中的(edit,b,none)表示在图(a)所示的逆合成过程中反应中心是化学键b而none表示编辑后该键的状态是none即删除了化学键b;后者对于输入序列token包含AddingMotif和添加motif的对象附着原子的索引,而对目标序列token包含AddingMotif和motif索引以及motif中与附着原子对应的接口原子。添加辅助token Start和FinishEdit,以此将所有产物的逆合成过程描述为转换路径,包含一条输入序列和一条输出序列。而后,该模型在序列上用自回归形式进行学习。构建序列更详细的内容请参看原文。
图编码器
这篇论文使用简单的消息传递神经网络MPNN来编码分子图:
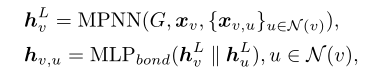
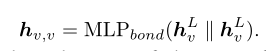
自回归模型
自回归模型的生成过程可以表示成一个联合条件分布: 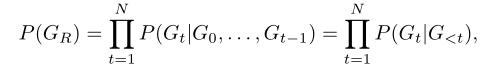
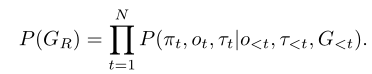
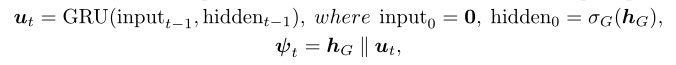
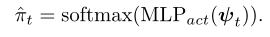
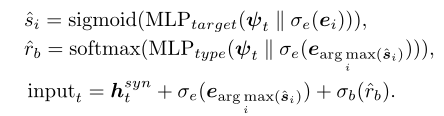
这里的和是对编辑对象的预测以及对编辑对象的新键类型进行预测。如果预测的行为是FinishEdit,此时代表合成子分解完成,开始进行添加motif操作,GRU中的input进行如下更新:
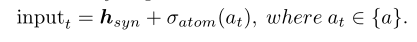
其中附着原子根据其在分子图中的索引进行存储。 如果预测的行为是AddingMotif,则模型需要预测添加的motif以及对应的接口原子:
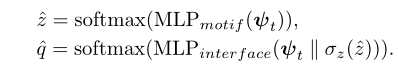
接着更新input到下一个token:
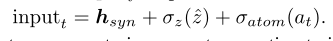
训练
训练目标是将上述预测跟真实值之间的损失总和:
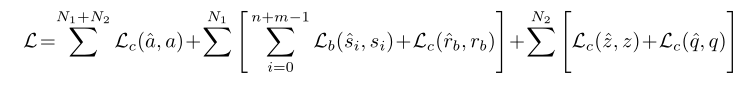
推断时采用束搜索策略。更详细的过程请参看原文。
实验结果
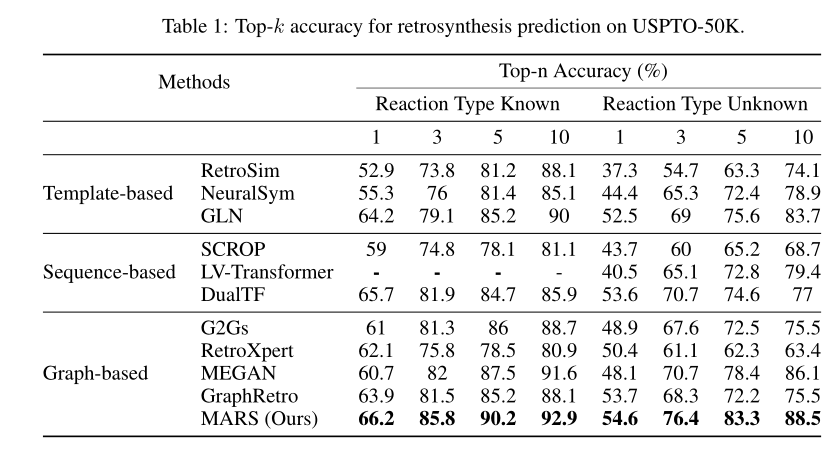
其余实验结果请参看原文。
