
今天要为大家介绍的是清华大学唐杰教授课题组发表在 bioRxiv 上的文章 Improve the Protein Complex Prediction with Protein Language Models。本文提出了 ColAttn 方法,该方法利用蛋白质语言模型识别复合物的间相互作用,并进一步结合多序列比对方法来提升结构预测准确性。
1 介绍 现在有许多深度学习模型在计算生物结构。AlphaFold-Multimer 就提升了蛋白质复合物结构的预测水平,但其准确性依然取决于多序列比对(MSA)结果。相对于 AlphaFold2,AlphaFold-Multimer 需要构建间相互作用 MSA,但如何构建依旧是一个问题。同时,蛋白质语言模型也在不同的工作中被广泛应用,它可以捕捉到序列中的约束和共进化信息。
本文中,作者首次提出了 MSA 配对算法 ColAttn,该算法把蛋白语言模型的输出组合成联合 MSAs 形式,利用 MSA Transformer 中的注意力得分从单链中识别配对同源物。该方法在异二聚体上展现了最好的结构预测准确率。作者同时把 ColAttn 与其他的 MSA 配对算法进行结合,准确率得到了进一步提升。
2 方法 本文提出的 ColAttn 模型如图 1 所示。模型输入一对查询序列后,利用 JackHMMER 查询 UniProt 数据库生成 MSA,同类序列归为同一个簇,MSA Transformer 评估每个 MSA 同源序列与查询序列的注意力得分,再用相似的注意力得分匹配同类型的同源序列,直接拼接匹配的序列得到间相互作用,间相互作用 MSA 作为 AlphaFold-Multimer 的输入来预测复合物结构。
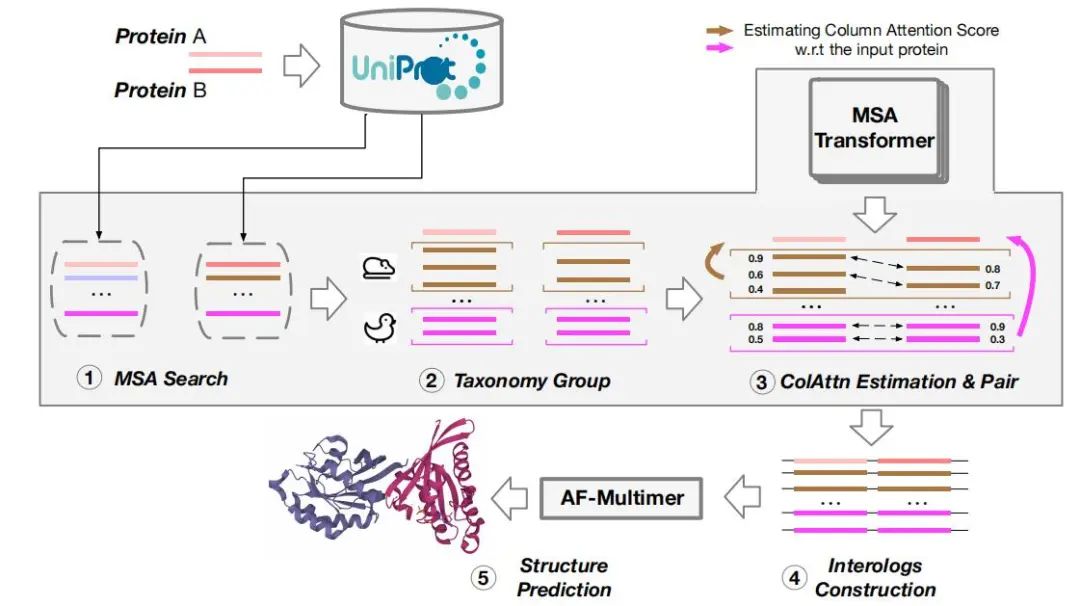
图 1:ColAttn 模型
列注意力(ColAttn)。列注意力权重矩阵由 MSA 的每一列通过 MSA Transformer 计算得来,其值可以视为每列中对齐氨基酸的相似性指标。把列注意力矩阵经过聚合得到对称矩阵,第一行 S1 可看作查询序列与 MSA 中其他序列的相似性。
对于一个查询序列,首先得到每个MSA 的 S1,再根据 S1 中的相似性来对序列进行排序,最后把不同种的 MSA 拼接起来得到间相互作用。
余弦相似性(Cosine Similarity)。语言模型为每个序列生成了残基水平的嵌入,序列的嵌入又由氨基酸嵌入聚合而成,序列相似性即为嵌入的余弦相似性。
Intra-ranking(IntraCos)。获得每个序列的嵌入后,计算查询序列与 MSA 序列的相似性,即得到了 S1,再像 ColAttn 一样构建间相互作用。
Inter-ranking。给定两个 MSA,计算这两个 MSA 中序列两两之间的相似性,并提出了 InterGlobalCos 和 InterLocalCos 两个构建间相互作用算法。
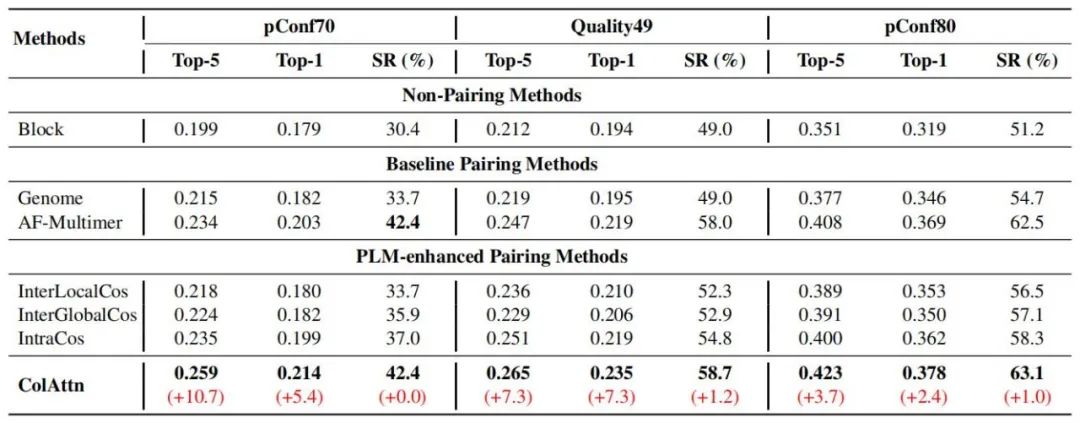
3 结果 作者从 PDB 中挑选了 801 个相似性最高只有 40%的异质二聚体靶标,利用 AlphaFold-Multimer 来预测复合物结构。作者根据置信度得分或 DockQ 得分,把置信度小于 0.7 的 92 个靶标作为 pConf70 测试集,同理整理出 168 个靶标的 pConf80 测试集,以及 DockQ 小于 0.49 的 155 个靶标的 DockQ49 测试集。
对每个测试靶标,用 AlphaFold-Multimer 模型生成 5 个三维结构,取 top-k DockQ 得分的平均值和相应的成功率,结果图表 1 所示。本文的方法效果最好。Block 方法最差,这说明链间共进化信息有助于复合物结构预测。
表 1:DockQ 得分和成功率
作者还比较了 ColAttn、AF-Multimer 和 Genome 方法在不同生物上的 DockQ 分布,如图 2 所示,结果显示 ColAttn 在真核生物上可以构建有效的间相互作用。

图 2:不同方法在不同域上的 DockQ 比较
作者还可视化了 5D6H、6KIP、6FYH、4LJO 这 4 个 PDB 结构,如图 3 所示,结果显示用 ColAttn 方法能精准预测而使用 AlphaFold-Multimer 不能。
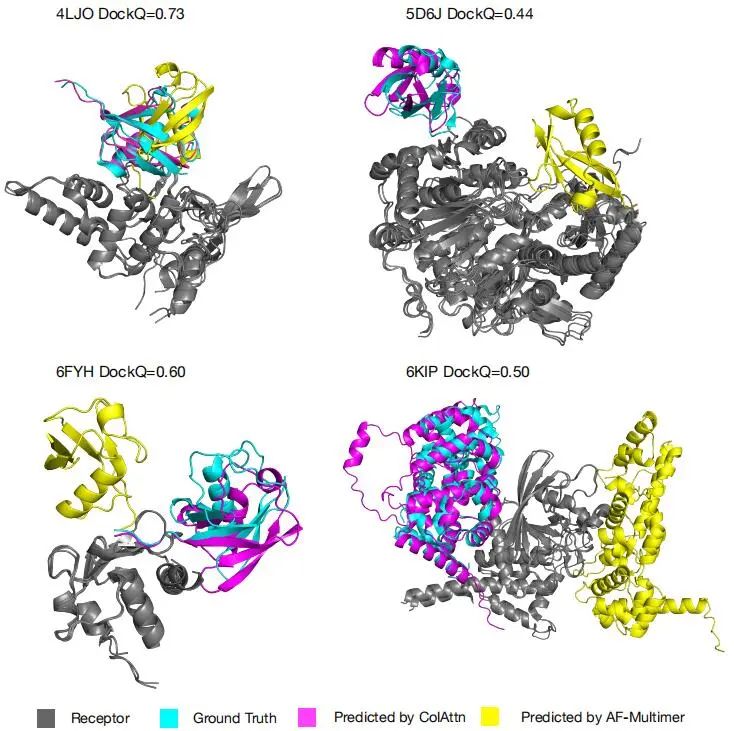
图 3:结构可视化
不同 MSA 方法具有不同的优势,作者任意结合两种方法组合成 10 个模型,取 Top-5 DockQ 平均得分,如图 4 所示,混合策略都显著好于相应的单个策略。
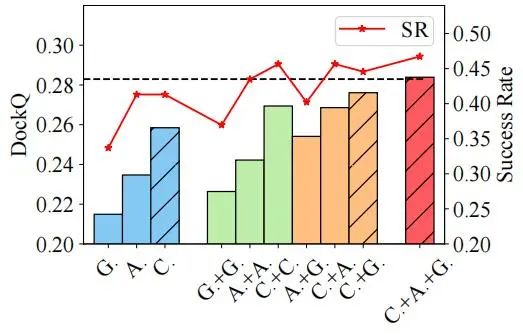
图 4:混合策略 Top-5 DockQ 得分平均结果
作者还研究了 ColAttn 与一些关键因素之间的联系,如列注意力得分(ColAttn_score)、有效序列的数量(#Meff)、物种数量(#Species)和 MSA 深度(MSA_Depth),结果如图 5 所示。
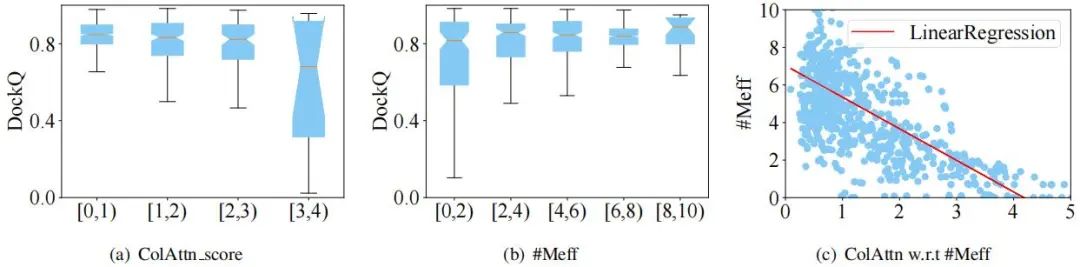
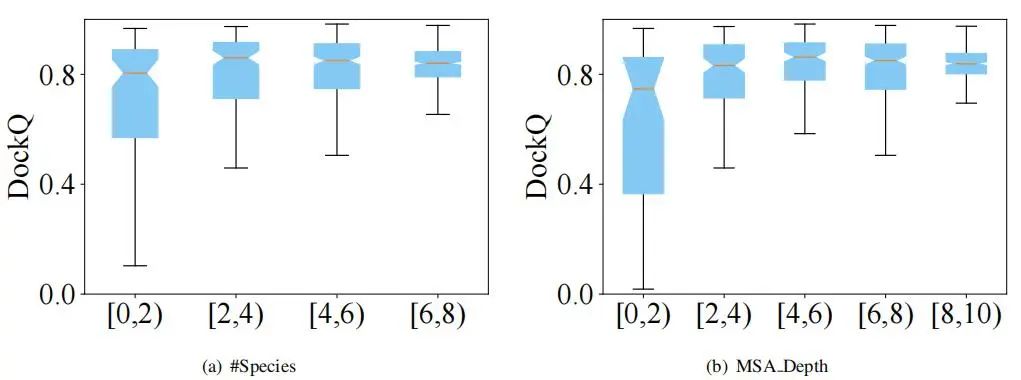
图 5:不同因素对结果的影响
作者使用预测结构的 DockQ 得分评估 ColAttn 构建的间相互作用质量,当层数为 6 或 7 时,效果是最好的。在第 6-12 层构造的 ColAttn 在识别同源序列上比前几层更加精确。
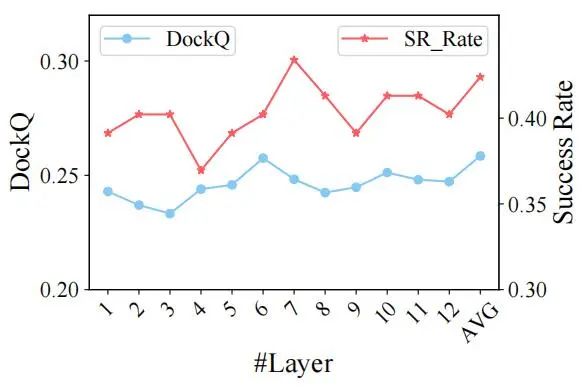
图 6:不同层上 DockQ 得分
4 总结 本文基于预训练蛋白语言模型,探索了一些 MSA 配对算法构建有效间相互作用的效果,这篇文章也是首次将蛋白语言模型用来构造联合 MSA,实验结果证明本文提出的 ColAttn 方法取得了最佳效果,特别是对于真核生物。本文也证明了混合的 MSA 配对策略也能提升结构预测准确性。 参考资料 Chen, B., Xie, Z., Xu, J., Qiu, J., Ye, Z. and Tang, J., 2022. Improve the Protein Complex Prediction with Protein Language Models. bioRxiv.
