
【导读】如今在越来越多的情况下,设备数据无法通过云端处理。尤其在工业机器人和自动驾驶汽车领域,它们需要高速处理,但当数据流增大而产生处理时延时会非常危险。针对日益多样化的边缘硬件,至今没有一个高效的功能模型设计的AI解决方案。最近来自麻省理工学院韩松等《移动设备深度学习:方法系统应用》

深度神经网络(DNNs)在人工智能(AI)领域取得了前所未有的成功,包括计算机视觉、自然语言处理和语音识别。然而,其卓越的性能是以计算复杂度为代价的,这极大地阻碍了其在许多资源受限设备(如移动电话和物联网设备)中的应用。因此,为了实现大量的边缘人工智能应用,需要在保持DNNs的高精度的同时,提升效率瓶颈的方法和技术。本文综述了有效的深度学习方法、系统和应用。首先介绍了常用的模型压缩方法,包括剪枝法、因式分解法、量化法以及紧凑模型设计。为了减少这些手工解决方案的巨大设计成本,我们讨论了每个解决方案的AutoML框架,例如神经体系结构搜索(NAS)和自动修剪和量化。然后,我们将介绍有效的设备上训练,以支持基于移动设备上的本地数据的用户定制。除了一般的加速技术,我们还展示了几个特定于任务的加速,用于点云、视频和自然语言处理,利用它们的空间稀疏性和时间/令牌冗余。最后,为了支持所有这些算法的进步,我们从软件和硬件两个角度介绍了高效的深度学习系统设计。
https://www.zhuanzhi.ai/paper/cfebf5f04cbacdfaf6936db4f5d10021
引言
深度神经网络(DNNs)已经彻底改变了人工智能(AI)领域,并在计算机视觉[118,155,263]、自然语言处理[22,71,271,291]和语音识别[69,122,328]等领域取得了令人瞩目的成绩。它们可以应用于各种现实场景,如手机[131,217,329],自动驾驶汽车[5,20,59,194]和智能医院[116,183,338]。然而,它们的卓越性能是以高计算复杂度为代价的。例如,最先进的机器翻译模型[291]需要超过10G的乘法累加(multiply-and-accumulate, mac)来处理一个只有30个单词的句子;目前流行的LiDAR感知模型[56]需要每秒超过2000G mac(即10帧)。
如此高的计算成本远远超出了大多数移动设备的能力,从汽车到移动电话和物联网设备,因为它们的硬件资源受到外形因素、电池和散热的严格限制。然而,这些计算工作量不能委托给云服务器,因为它们对延迟(例如,自动驾驶)和/或隐私(例如,医疗保健)非常敏感[199,360]。因此,高效的深度学习是移动AI应用的一大需求。为了加快神经网络推理的速度,研究者们提出了多种模型压缩技术,包括剪枝[115,121,195]、低秩分解[149,332,352]和量化[62,114,133]。除了建立在现有的大型模型之上,研究人员还探索了直接从零开始设计高效的神经网络,包括MobileNets[125,250]、ShuffleNets[202,351]和SqueezeNets[202,351]。这些解决方案通常需要大量人力的努力,因为有一堆参数需要共同调整,以实现最佳性能:例如,修剪比和每一层的量化位宽。为此,有很多探索使用自动机器学习(AutoML)调节参数解决人类的设计过程的耗时,如神经结构搜索(NAS)[29、106、187、277、366),自动修剪(120、196、336)和自动量化(299、300、306)。然而,AutoML的好处并不是免费的,因为它会显著增加碳足迹: 进化Transformer [264]产生了5辆美国汽车的终生二氧化碳排放量(见图2)。为了实现绿色和可持续的人工智能,研究人员提出了高效搜索高效神经结构[25,296],该神经结构可以达到相同的精度水平,同时减少碳足迹的数量级。
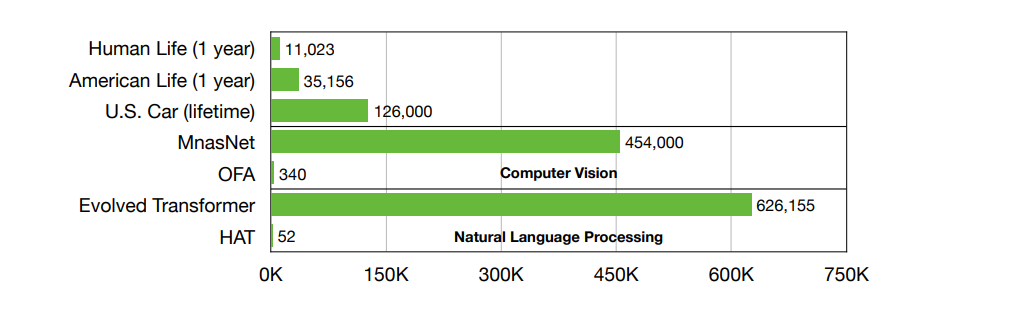
深度学习可以引入较大的碳足迹:例如,进化Transformer[264]产生5辆汽车的终身碳排放量。因此,高效的深度学习对于绿色和可持续的人工智能至关重要。
除了推理之外,神经网络训练也可能非常昂贵,这阻碍了设备上的训练,从而阻碍了移动设备上的用户定制。为了解决这一问题,研究人员提出了各种高效的记忆训练算法,如梯度检查点[44]、激活剪枝[65]和低比特量化[356]。在大多数用例中,移动模型只需要对本地用户数据进行少量的微调,以提供专门化。因此,另一种研究试图提高迁移学习的效率[26,214]。最近,研究人员也引入了联邦学习[151],在不损害隐私的情况下聚合用户的训练模型。除了原则上可以应用于任何任务的一般加速外,在特定领域的加速方面已经有了广泛的研究。在本文中,我们将重点研究点云处理、视频理解和自然语言处理,因为它们广泛应用于移动应用,如自动驾驶和移动视觉/NLP。一方面,由于内存占用较大,它们的计算成本比传统2D视觉要高得多。另一方面,它们还通过利用和删除空间和时间冗余提供了独特的加速机会:空间冗余(点云)、时间冗余(视频)和标记级冗余(自然语言)。
然而,并不是所有的算法改进都能转化为硬件上可测量的加速。例如,通用推理库(如cuDNN[52])和硬件(如CPU、GPU)不支持稀疏和低位计算(由细粒度剪枝和量化引入)。最近在设计专业软件系统[43,72,137,138]和硬件系统[4,48,113,219,256,298,353]方面的努力逐渐弥合了这一差距。专门的软件系统探索神经网络内部和内部操作的并行性,并通过启发式规则甚至基于学习的方法优化计算图和内存调度。专门的硬件系统从硬件架构层面直接支持修剪网络的稀疏性和混合精度量化。软件和硬件系统的专业化开辟了一个与算法空间正交的新的设计空间,可以进一步利用这个空间来释放专业化未实现的潜力。因此,研究人员探索了多种协同设计解决方案,如自动分配不同平台上的计算资源用于神经网络模型[140,144,211,212],自动调整硬件架构[335,366],甚至联合搜索神经网络和加速器设计,包括处理元素之间的连接和循环调度[181]。
已有许多研究涉及模型压缩[50,54,68]、自动化机器学习[78,119,317]、高效硬件架构设计[272]和特定任务优化[283]。本文旨在涵盖更广泛的有效深度学习方法和应用:从手动到自动,从新的原语/操作设计到设计空间探索,从训练到推理,从算法到硬件,从通用到特定应用的优化。我们相信,这篇综述论文将为这一领域提供一个更全面的视角。本文其余部分的结构如下(图1): * 第二节讨论了各种模型压缩方法,包括剪枝、低秩分解、量化、知识精馏和紧凑模型设计。 * 第三节研究用于模型压缩和神经结构搜索的AutoML框架。 * 第四节描述了有效的设备上训练(一般/迁移学习技术)。 * 第五节研究点云、视频和语言的特定应用程序加速。 * 第六节介绍了深度学习的高效软件/硬件设计。

左:有效深度学习解决方案的范围(从推理到训练,从算法到软件/硬件系统,从一般到特定领域)。右:论文组织概述。
模型压缩
深度神经网络通常是过度参数化的。剪枝去除神经网络中的冗余元素,以减少模型大小和计算成本(图3)。
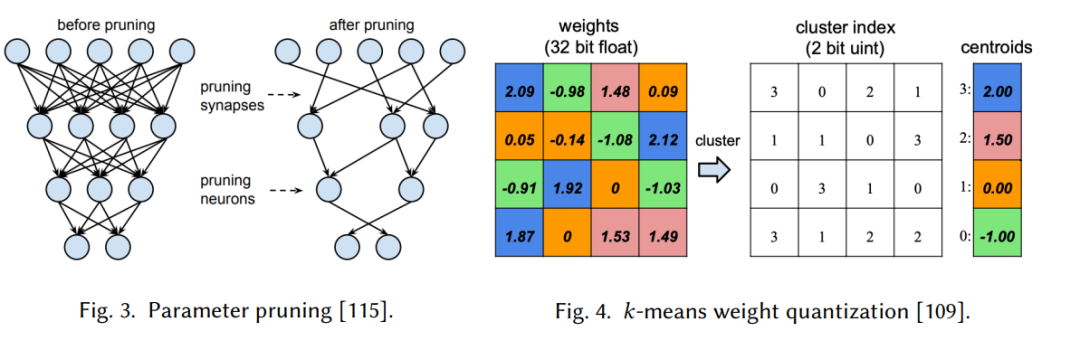
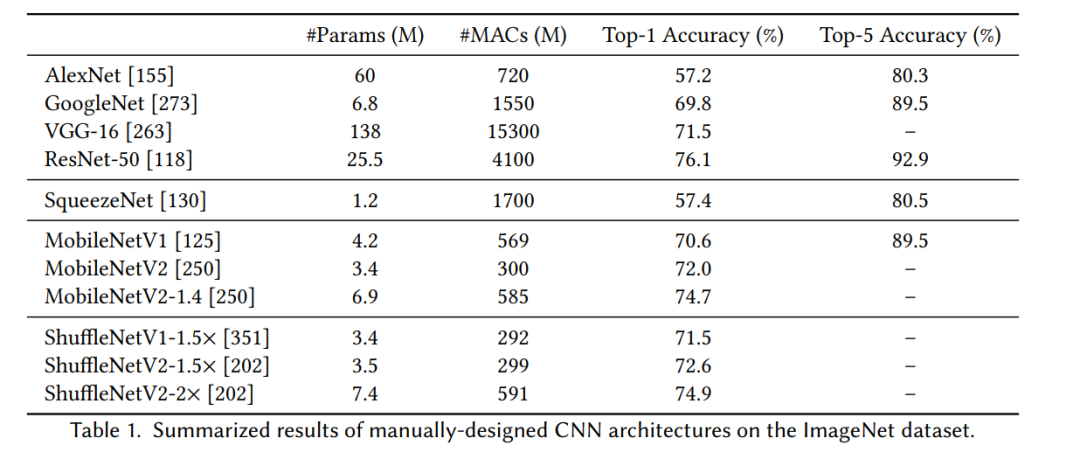
低秩分解利用矩阵/张量分解来降低深度神经网络中卷积层或全连通层的复杂性。利用低秩滤波器加速卷积的思想在信号处理领域已经研究了很长时间。 网络量化通过减少表示深度网络所需的每权重比特数来压缩网络(图4)。量化网络在硬件支持下可以有更快的推理速度。 知识蒸馏(KD)[23,123]可以将在大模型(教师)中学习到的“暗知识”转移到较小模型(学生)中,以提高较小模型的表现。小模型要么是一个压缩模型,要么是一个浅/窄模型。Bucilua等[23]通过训练学生网络匹配输出logit来达到目标;Hinton等人[123]在softmax输出中引入了temperature 的概念,并训练学生模拟教师模型的softmax输出的软化分布。KD算法虽然实现简单,但在各种图像分类任务中都有很好的效果。 除了压缩现有的深度神经网络,另一个被广泛采用的提高效率的方法是设计新的神经网络结构。一个CNN模型通常由卷积层、池化层和全连接层组成,其中大部分的计算来自卷积层。例如,在ResNet-50[118]中,超过99%的乘法累加操作(multiple -accumulate operations, MACs)来自卷积层。因此,设计高效的卷积层是构建高效CNN架构的核心。目前广泛使用的有效卷积层有1×1/点态卷积、群卷积和深度卷积三种。
自动压缩和神经结构搜索
上述模型压缩策略和高效的神经网络架构的成功依赖于手工制作的启发式,这需要领域专家探索较大的设计空间,在模型大小、延迟、能量和准确性之间进行权衡。这是耗时且次优的。在本节中,我们将描述处理此挑战的自动化方法。
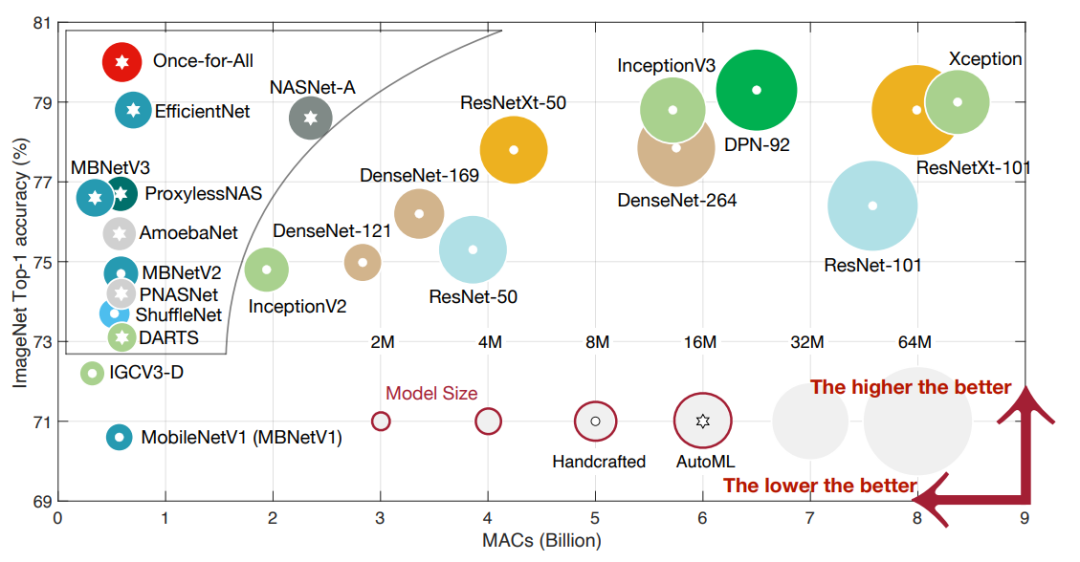
上图报告了ImageNet上自动设计和人工设计CNN模型的总结结果。NAS节省了工程师的人工成本,并提供了比人工设计的CNN更好的模型。除了ImageNet分类,自动设计的CNN模型在目标检测[46,91,278,367]和语义分割[40,184]方面也优于手动设计的CNN模型。
高效设备学习
在现实世界的边缘人工智能应用中,智能边缘设备每天通过传感器收集新数据,同时被期望在不牺牲隐私的情况下提供高质量的定制服务。这些都对高效的人工智能技术提出了新的挑战,这些技术不仅可以运行推断,而且还可以根据新收集的数据不断调整模型(即设备上学习)。虽然设备学习可以实现许多有吸引力的应用,但这是一个极具挑战性的问题。首先,边缘设备是内存受限的。例如,一个树莓派1模型a只有256MB的内存,这足以进行推理,但仍然不足以进行训练(图9),即使使用轻量级的神经网络(MobileNetV2[250])。此外,内存被各种设备上的应用程序(例如,其他深度学习模型)和操作系统共享。单个应用程序可能只分配了总内存的一小部分,这使得这个挑战更加关键。第二,边缘设备是能量受限的。访问DRAM比访问片内SRAM多消耗两个数量级的能量。激活的大内存占用不能适应有限的片内SRAM,因此它必须访问DRAM。例如,在批处理大小为16的情况下,MobileNetV2的训练内存接近1GB,这远远大于AMD EPYC CPU的SRAM大小(图9),更不用说低端平台了。如果训练存储器能与片上SRAM相匹配,将大大提高速度和能源效率。
