
1. 引言
随着人工智能(AI)技术的快速发展,大型语言模型(LLMs)在自然语言处理(NLP)、代码生成和决策支持等领域取得了显著进展。然而,传统的LLMs在多步逻辑推理、抽象概念化和潜在关系推断等方面仍存在局限性。DeepSeek AI通过计算高效的架构,如DeepSeek Mixture-of-Experts(MoE)框架,解决了这些挑战,减少了推理成本,同时保持了性能。DeepSeek v3是一种通用LLM,优化了指令跟随和推理能力,DeepSeek Coder专注于代码生成和软件工程,DeepSeek Math处理符号和定量推理,DeepSeek R1-Zero和DeepSeek R1则设计用于跨领域问题解决,且只需最少的微调。通过开源硬件无关的实现,DeepSeek拓宽了高性能AI的访问范围。本文综述了DeepSeek的架构进展,比较了其与最先进LLMs的特点和局限性,并探讨了其对AI研究的影响,详细讨论了未来工作的潜在方向。

2. 相关工作
近年来,AI领域的进展催生了专门优化的模型,用于推理、数学问题解决和代码生成,补充了在文本任务中表现出色但在数学精度和结构化问题解决方面表现不佳的通用LLMs。为了弥补这些差距,AI研究越来越关注增强下一代模型的推理能力和计算效率。
2.1 OpenAI GPT
OpenAI的GPT-4于2023年3月发布,是一种多模态模型,能够处理文本和图像。基于Transformer架构,GPT-4在数学推理和语言理解等任务上超越了GPT-3。GPT-4估计拥有1.8万亿参数,显著大于GPT-3的1750亿参数。GPT-4最初支持8,192个令牌(GPT-4-8K)和32,768个令牌(GPT-4-32K)的上下文窗口。2023年晚些时候,GPT-4 Turbo的推出将上下文窗口扩展到了128K个令牌。尽管GPT-4在图像字幕生成和问题解决等任务中表现出色,但在医学、法律或技术领域等专业领域中,模型可能会生成听起来合理但实际上不正确或捏造的信息(幻觉)。
2.2 Claude 3.5
Claude 3.5于2024年发布,是Anthropic语言模型家族的最新进展。基于先前版本,Claude 3.5强调安全性、对齐性和性能,在推理、语言理解和处理复杂任务(如文本和代码生成)方面有所改进。Claude 3.5拥有约2500亿参数,在准确性和伦理对齐方面优于早期模型。它支持高达200K个令牌的扩展上下文,能够更好地处理较大的输入。通过人类反馈强化学习(RLHF)和宪法AI的增强,Claude 3.5减少了不良响应、偏见,并更好地与人类意图对齐。Claude 3.5在编码和科学推理等专业领域表现出色,具有更高的透明度和伦理保障。然而,当输入复杂或模糊且接近上下文限制时,性能可能会下降。
2.3 LLaMA 3.1
LLaMA 3.1于2024年发布,是Meta的LLaMA(大型语言模型Meta AI)家族的最新版本,继LLaMA 1(2022年)和LLaMA 2(2023年)之后。LLaMA 1拥有高达650亿参数,而LLaMA 2则扩展到700亿参数,并提供了较小的变体(7B、13B),增强了泛化和多语言能力。LLaMA 3.1进一步推进,拥有4050亿参数和128K个令牌的上下文窗口,通过分组查询注意力提高了效率。LLaMA 3.1在编码、逻辑问题解决和低资源语言任务中表现出色。与GPT-4等封闭模型不同,LLaMA 3.1保持开放权重,可供研究和商业使用,但仅限于文本输入。通过自动红队测试(模拟攻击或从对手角度测试系统的实践)和过滤训练数据等安全措施,LLaMA 3.1有助于减少不良输出。
2.4 Qwen 2.5
Qwen2于2024年6月发布,是Qwen系列的最新版本,继Qwen1.5(2024年2月)和原始Qwen(2023年8月)之后。Qwen1.5拥有高达720亿参数的模型,强调效率和开源可访问性,而Qwen2则扩展到1100亿参数,在推理、多语言支持和编码能力方面有所改进。Qwen2利用128K个令牌的上下文窗口,通过YaRN(上下文扩展微调)等创新实现稳定的长上下文处理。Qwen2在数学推理、代码生成和低资源语言理解等任务中优于其前身。对齐技术包括RLHF、直接偏好优化(DPO)和精选的安全数据集,以减少不良响应。
2.5 Gemini 2.0
Gemini 2.0是谷歌最新的多模态LLM,基于1.0和1.5版本,提供了更强大的生成式AI能力,涵盖文本、图像、音频和视频。Gemini 2.0 Flash最初作为实验性变体引入,提供了比其前身Gemini 1.5 Flash显著的速度和效率提升,而不会牺牲质量。它支持代理AI和原生工具使用,允许模型调用外部函数(如Google搜索和地图)并集成流数据以扩展实时应用。通过在数学、代码生成和多语言音频输出等任务中的更好表现以及增强的能源效率,Gemini 2.0旨在为开发者和终端用户提供全面、经济高效的AI解决方案。
3. DeepSeek及其变体
DeepSeek模型基于Transformer架构,通过分组查询注意力(GQA)和FlashAttention 2进行优化。GQA通过分组查询共享键值头来平衡效率和质量,FlashAttention 2是一种计算感知算法,通过平铺和重计算优化GPU内存使用。这些增强功能减少了内存开销并提高了推理速度。核心注意力机制遵循以下公式:
Attention(Q,K,V)=softmax(QKTdk)V
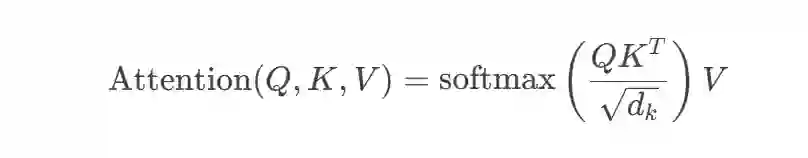
3.1 DeepSeek 7BDeepSeek 7B是一个70亿参数的模型,设计用于通用任务,如推理、编码和文本生成。它采用预归一化、仅解码器的Transformer设置,具有RMSNorm归一化和SwiGLU激活的馈送层。该模型结合了RoPE和GQA,由30个Transformer层、32个注意力头和4096的隐藏维度组成,上下文窗口范围从4K到32K个令牌,可通过RoPE调整。DeepSeek Chat是一个更大的变体,拥有670亿参数,包括95个Transformer层、64个注意力头和8192的隐藏维度。
3.2 DeepSeek MoE-16B
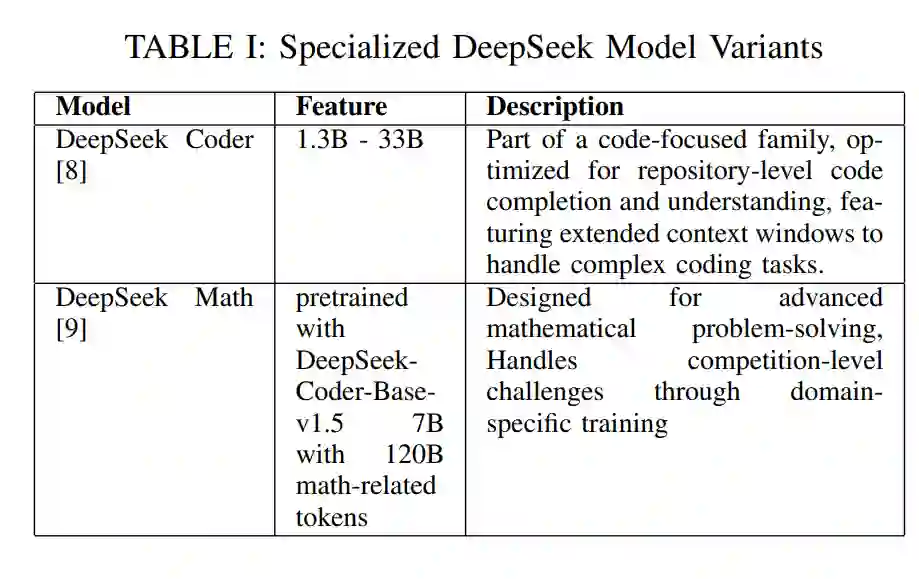
DeepSeek MoE-16B是一个160亿参数的MoE模型,每个令牌仅激活26亿参数,通过动态路由输入通过16个专家网络中的2个。这种稀疏激活将推理成本降低了70%,同时保持了与类似大小的密集模型相当的性能。它在涵盖代码、数学和通用文本的多样化数据集上进行了预训练,专注于高质量数据和专家专业化,以处理代码生成和数学推理等任务。表I展示了其他基于DeepSeek的专用变体。
3.3 DeepSeek V2
DeepSeek V2系列包括DeepSeek V2,拥有2360亿总参数和210亿活跃参数,跨越60层和128K上下文长度,以及DeepSeek V2 Lite和两个聊天机器人。在架构上,它集成了MLA(多头潜在注意力)、低秩近似和MoE框架,以减少内存使用,同时保持深度上下文理解。该系列在8.1T个令牌上进行了预训练,使用YARN从4K扩展到128K,并通过1.2M个实例进行了SFT,以提高帮助性和安全性,最终形成了未发布的DeepSeek V2 Chat(SFT)。它通过两阶段RL过程进一步优化:第一阶段专注于数学和编码,使用基于编译器反馈和地面真实标签的奖励模型;第二阶段旨在提高帮助性、安全性和规则遵从性,利用基于人类偏好和手动编程的三个奖励模型。
3.4 DeepSeek V3
DeepSeek V3代表了LLM的重大升级,使用14.8T个令牌从多语言语料库中进行预训练,并采用稀疏MoE架构,拥有6710亿参数,每个任务仅激活370亿参数。这种设计通过动态分配资源以满足特定任务需求,提高了计算效率,从而降低了运营成本。该模型包括一个路由系统,具有1个共享专家和256个路由专家,具有动态偏差调整功能,以确保专家利用的平衡,提高了可扩展性和可靠性。此外,多令牌预测(MTP)增强了模型在复杂语言和推理任务中的能力。尽管其架构先进,DeepSeek V3仍面临一些局限性:
- 计算和硬件需求:由于其6710亿参数,需要高端硬件,限制了资源受限用户的访问。
- 路由和负载平衡的复杂性:模型的动态路由可能会错误路由或过度优先考虑专家,可能会降低输出质量。调整动态偏差以适应多样化任务仍然具有挑战性。
- 潜在注意力压缩风险:MLA在注意力模式中丢失细节,可能会影响长上下文序列中细微依赖关系的跟踪能力。 接下来,DeepSeek R1-Zero和DeepSeek R1是DeepSeek V3架构的高级变体,旨在解决其局限性。
3.5 DeepSeek R1-Zero

3.6 DeepSeek R1
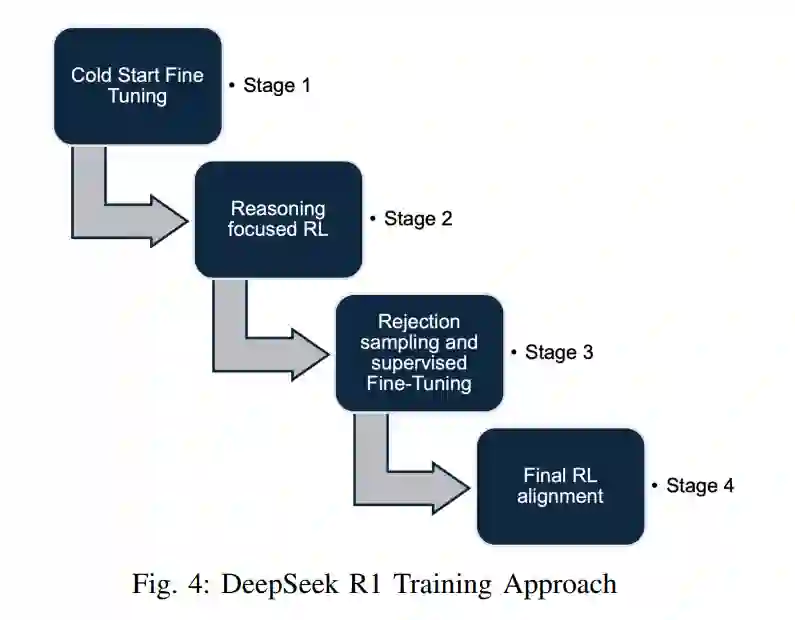
DeepSeek R1顺序生成令牌,并通过生成思考令牌来阐明其推理过程,从而为问题解决分配额外时间,如图3所示。其训练管道包括以下步骤,如图4所示:
- 冷启动微调:使用精选数据集和思维链(CoT)增强清晰度并加速RL。
- 推理聚焦的RL:通过基于规则的奖励改进编码、数学和逻辑。
- 拒绝采样和监督微调:优化响应并扩展写作、事实问答和角色扮演能力。
- 最终RL对齐:确保遵循人类偏好,提高帮助性和安全性。 以下是DeepSeek R1模型的主要增强功能:
**3.6.1 改进的搜索策略
蒙特卡罗树搜索(MCTS)受AlphaGo启发,曾尝试系统地探索解决方案空间,但由于以下原因,证明在计算上不可行:
- 扩展的搜索空间:令牌级生成显著增加了复杂性。
- 无效的价值模型:训练一个强大的引导模型困难,导致扩展性差。
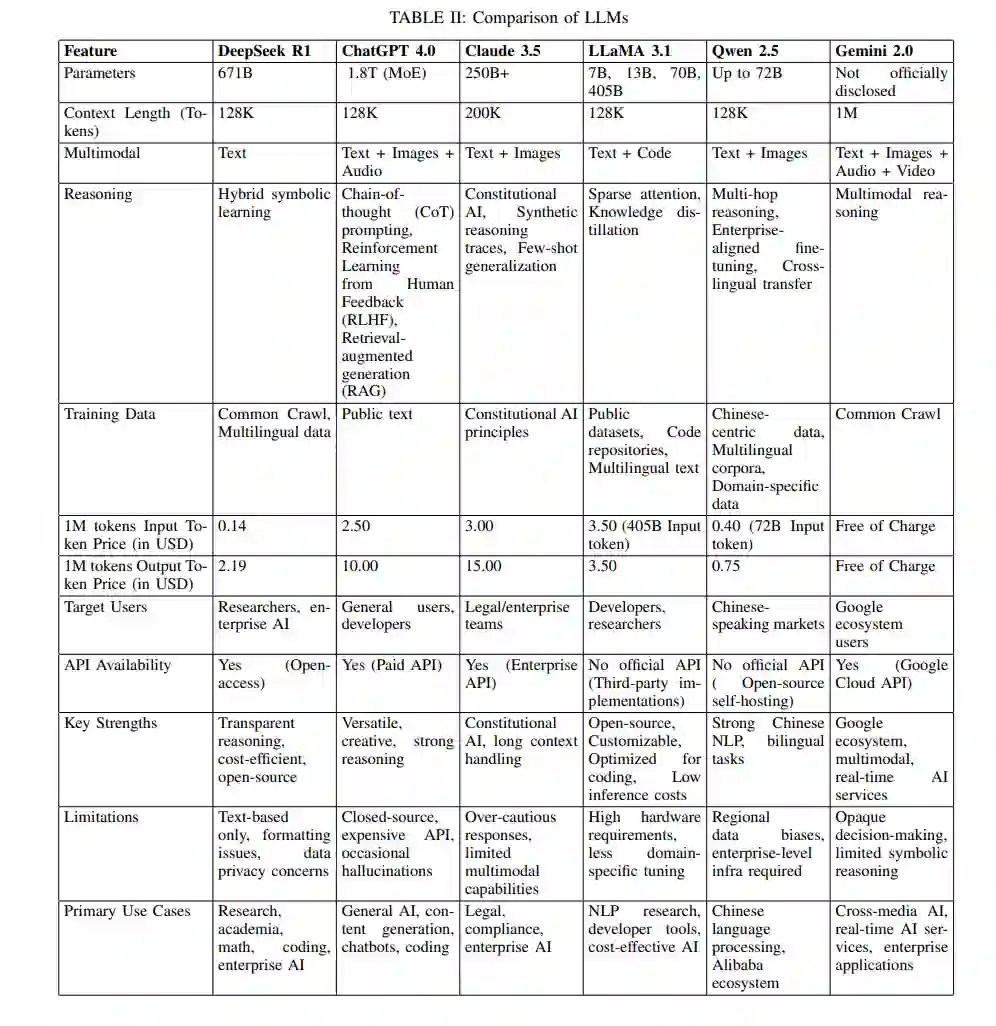
- 收敛到局部最优:该方法在复杂推理任务中往往无法泛化。 DeepSeek R1用更简单的拒绝采样方法取代了MCTS,从中间RL检查点选择高质量响应。通过结合多样化的奖励信号,模型不仅在推理方面有所改进,还在与人类偏好对齐方面有所提升。表II展示了DeepSeek R1、ChatGPT-4、Claude 3.5、LLaMA 3.1、Qwen 2.5和Gemini 2.0的全面比较。
4. 讨论
DeepSeek通过优先考虑领域特定优化、透明度和成本效率,与GPT-4.0、Claude 3.5、LLaMA 3.1、Qwen 2.5和Gemini 2.0等通用模型区分开来。虽然主流LLMs专注于广泛的适应性,DeepSeek则专注于精确推理和决策制定,使AI更加实用和可靠。DeepSeek R1是DeepSeek的最新变体,集成了文本、数据库和知识图谱,采用思维链(CoT)进行逐步推理和Pro Search进行上下文感知响应。这提高了数学、编码和决策制定等领域的准确性,同时保持了清晰度。在编码中,R1在提供答案之前概述其逻辑,使用户能够验证其推理。与专有模型不同,DeepSeek R1是开放访问的,降低了成本,同时保持了在不同领域的竞争性能。其高效设计,包括8位浮点精度(FP8),优化了内存使用,使其能够在资源有限的环境中部署。通过降低财务和技术门槛,DeepSeek使资源有限的地区、小型企业和研究人员能够访问先进的AI。早期版本的DeepSeek R1,DeepSeek R1-Zero存在格式不一致和多语言输出问题。为了解决这个问题,冷启动数据生成强制执行结构化格式和简洁摘要以提高清晰度。DeepSeek R1在以下方面表现出色:
- 优化计算:FP8将内存需求比32位模型减少了75%。
- 任务特定性能:基准测试显示,它在英语语言(DROP(3-shot F1))、中文语言(CLUEWSC)、编码(HumanEval-Mul)和数学推理(MATH-500(EM))方面与专有模型相当或优于它们。
- 可扩展性:其开放访问方法使医疗保健、金融和教育等领域受益,其中精度和成本效率至关重要。
5. 结论与未来工作
DeepSeek R1提高了推理、效率、透明度和决策制定能力。其效率和清晰的推理为资源节约和可理解的AI设定了新标准。通过提供强大的开源性能,它挑战了专有模型,使先进的AI工具更加可访问,并在关键领域建立了信任。未来的工作可以集中在将DeepSeek R1的基础能力应用于各个领域的现实世界挑战。在医疗保健领域,改进结构化症状分析并整合医学知识图谱可以提高诊断准确性。在教育领域,自适应辅导系统可以将复杂概念分解为清晰的逐步推理,使学习更加有效。科学研究可以受益于将实验数据与理论模型连接的AI驱动方法,加速材料科学等领域的发现。通过更好的硬件-软件集成,可以在物联网和边缘设备上更有效地运行AI,同时减少能源消耗,从而实现效率的进步。在自动驾驶系统和法律AI等高风险领域确保透明度,将需要可审计的推理路径和内置的偏见缓解策略。通过社区驱动开发和专有增强相结合的开放源代码生态系统扩展,可以帮助为公共和企业需求定制AI工具。除了这些领域,AI在金融中的应用,如通过市场图谱分析进行实时风险评估,以及通过地缘政治知识图谱集成进行供应链管理,可以改变决策过程。展望未来,建立伦理问责标准,赋予领域专家AI驱动的洞察力,以及完善平衡规模与精度的混合架构,将是关键。DeepSeek R1有潜力推动一个建立在效率、透明度和现实世界影响基础上的AI景观。
参考文献
[1] J. Achiam, S. Adler, S. Agarwal, L. Ahmad, I. Akkaya, F. L. Aleman, D. Almeida, J. Altenschmidt, S. Altman, S. Anadkat et al., "Gpt-4 technical report," arXiv preprint arXiv:2303.08774, 2023.[2] Anthropic, "Claude 3.5 sonnet," Blog post, 2024, accessed: 2024-07-15. [Online]. Available: https://www.anthropic.com/news/claude-3.5-sonnet[3] A. Dubey, A. Jauhri, A. Pandey, A. Kadian, A. Al-Daille, A. Lerman, A. Mathur, A. Schelten, A. Yang, R. Fan et al., "The llama 3 herd of models," arXiv preprint arXiv:2407.21783, 2024.[4] A. Yang, B. Yang, B. Zhang, B. Hui, B. Zheng, B. Yu, C. Li, D. Liu, F. Huang, H. Wei et al., "Qwen2. 5 technical report," arXiv preprint arXiv:2412.15115, 2024.[5] DeepMind, "Gemini 2.0," https://deepmind.google/technologies/gemini/, 2023, accessed: 2025-01-01.[6] X. Bi, D. Chen, G. Chen, S. Chen, D. Dai, C. Deng, H. Ding, K. Dong, Q. Du, Z. Fu et al., "Deepseek llm:

