Pytorch多模态框架MMF
【导读】跨模式推理对人工智能至关重要。越来越需要对模式之间的交互进行建模(例如,视觉,语言),以改进对现有任务的AI预测并启用新的应用程序。多模式AI问题包括视觉问答,和视觉对话到具体化的AI,虚拟助手以及在社交媒体上检测不良内容。更好的工具(对于研究人员提出新颖的想法以及对从业人员生产用例而言)都有可能加速多模式AI的发展。

MMF(“ MultiModal Framework”的缩写)是基于PyTorch构建的模块化框架。MMF随附了最新的视觉和语言预训练模型,大量现成的标准数据集,通用层和模型组件以及训练+推理实用程序。MMF还被多个Facebook产品团队用于多模式理解用例,因为它有助于快速将研究推向生产。
MMF的核心特征
可用性
基于PyTorch 1.5
拥有12个以上最先进(包括BERT式)模型的模型动物园
具有约20个可自动下载的数据集的数据集动物园
全面的文档和教程
干净,易于扩展的API
应对多模式挑战的入门代码
模块化和可配置性
模块化组件,例如编码器,解码器,嵌入,层和处理器,可从头开始构建模型和数据集
基于OmegaConf的新配置系统
常用指标和损失
可扩展性
分布式培训支持以及最佳实践,以实现最佳性能
扫描脚本以启动大规模SLURM作业
Checkpoint,提前停止和其他功能,使培训和评估更加轻松
MMF的使用方法
第一步:安装
首先,我们将安装MMF以下载并安装所有必需的依赖项。然后,我们检查下载是否成功。
先决条件:Python 3.7 +,Linux,MacOS或Windows
pip install —-pre mmfpython -c “import mmf; print(mmf.__version__)”
第二步:下载数据集
地址链接:
https://www.drivendata.org/competitions/64/hateful-memes/data/
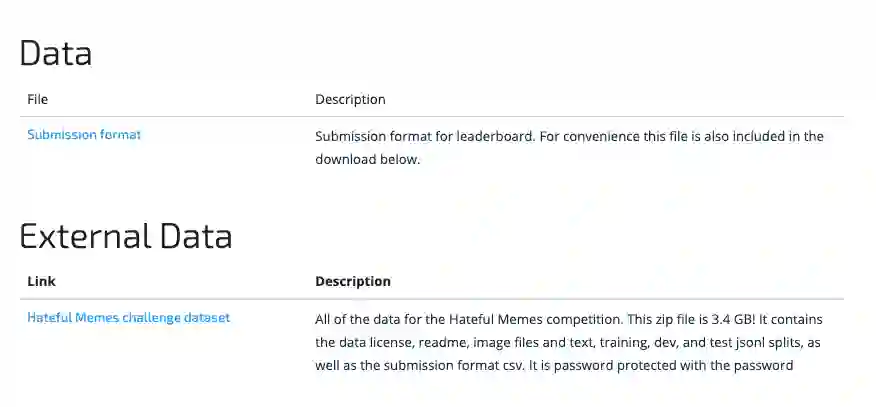
下载之后,将其转换为MMF格式
mmf_convert_hm --zip_file <zip_file_path> --password <password>第三步:可视化数据
from mmf.utils.build import build_datasetdataset = build_dataset("hateful_memes")dataset.visualize(num_samples=8)
第四步:评估预训练模型
预训练模型:
https://github.com/facebookresearch/mmf/tree/master/projects/mmbt/
from mmf.models import MMBTmodel = MMBT.from_pretrained("mmbt.hateful_memes.images")model.classify("path/to/img.png", "some text")
更多内容见:
https://medium.com/pytorch/bootstrapping-a-multimodal-project-using-mmf-a-pytorch-powered-multimodal-framework-464f75164af7







