GAN | GAN介绍(2)
目录
什么是GAN?
GAN能够做什么?
GAN的框架和训练
GAN与其他生成模型的异同
GAN模型的存在问题
(接上期)
3 GAN的框架和训练
之前讲到GAN主要由两部分组成:生成模型和判别模型,两者在对抗过程中,生成模型对真实数据分布的拟合能力能够逐步提高。现在我们深入到GAN的具体形式化和训练过程。令G为生成模型,D为判别模型,z为输入到生成模型的噪声,p(z)为输入噪声的分布,V(G,D)为GAN模型的损失函数。训练结束后,取生成模型的输出作为GAN输出。
扩展:GAN模型的损失函数为: V(D,G)是一个经典二元分类问题的损失函数,这种函数形式定义了二元分类的交叉熵,训练目标是使得交叉熵最小。与一般分类问题不同,GAN模型的所有正例都来自于真实样本,所有负例都来自于模型样本。GAN模型也可以视作判别模型和生成模型的零和博弈问题,其达到均衡点时生成模型能够准确还原真实数据。 |
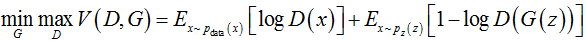
训练GAN模型的基本步骤为:
1)取得z~p(z)并将其作为输入置于生成模型G中;
2)令生成模型的输出x=G(z)为对应的模型样本,再从真实数据中采样获得真实样本x~pdata;
3)混合模型样本和真实样本,训练判别模型D,使判别模型能够最大可能的区分这两类样本,即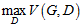
4)生成模型根据判别模型所得训练误差,在给定判别模型D的情况下最小化模型的误差,即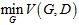
5)重复以上步骤,直至判别模型无法识别真实样本和模型样本,即D*(x)=1/2。(注:D*表示理想情况下的判别模型)
图6展示了训练GAN模型的基本框架。
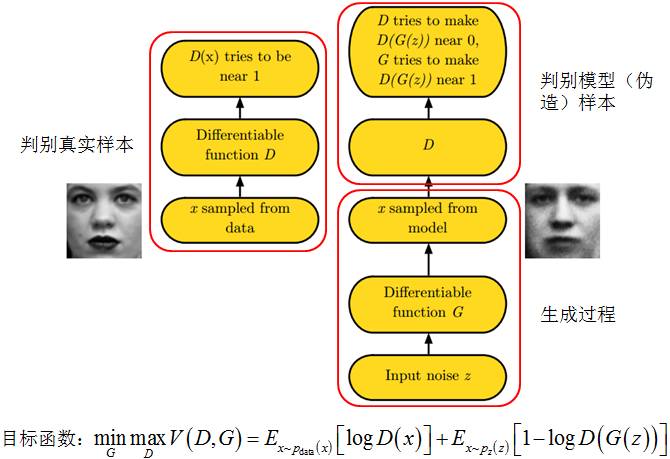
图6 GAN框架
Goodfellow et al.发表在NIPS 2014的论文《Generative Adversarial Nets》一文中,形象化的展示了GAN的训练过程。如图7所示,黑色点线表示真实样本的分布情况,蓝色虚线表示判别模型从给定样本中识别真实样本的准确情况,绿色实线表示生成模型所拟合的分布。底部有两条实线:z设定为来自均匀分布中的采样空间,x为z经过生成模型G变换后的映射空间。
GAN模型的初值情况如图7(a)所示;经过训练步骤(1)~(3)的操作,得到当前最优的判别模型D,用以区分当前的模型样本和真实样本(见图7(b)),理想情况下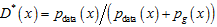
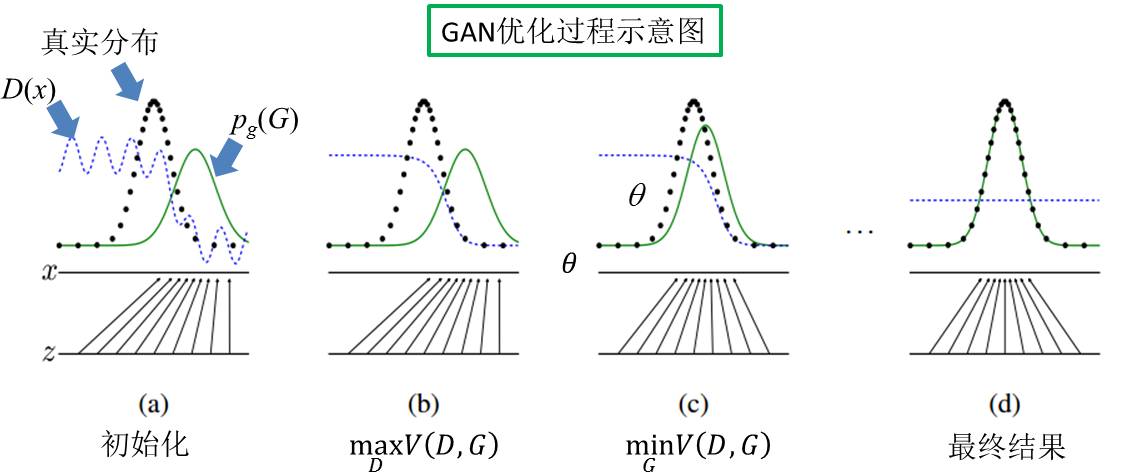
图7 GAN优化过程示意
4 GAN与其他生成模型的异同
接下来就GAN和生成模型这一族的模型进行逐一比较,明确GAN作为生成模型的优势。
生成模型主要建模观测数据的分布情况,利用最大似然求解真实的样本分布。一般地,我们可以将这类利用最大似然求解的方法分为两类:有具体概率密度函数形式的和无具体概率密度函数形式的。先看有具体概率密度函数形式的那一支,对于具体的概率密度函数,我们可以写出其具体形式,根据其形式和计算的复杂程度,又可分为可直接求解的和需近似计算两类。可直接求解的方法,常见的例如高斯分布等,由于其计算形式简单,可直接对观测进行拟合求解具体分布中的参数。而近似计算则相对复杂的多,常用手段之一是采用平均场思想,使用变分近似估计。蒙特卡罗近似相比变分近似的方法虽然在收敛性上难以保证,在收敛效率上也有所欠缺,但这类方法比较容易实现,因此也常用于近似估计概率密度函数。但给定概率密度函数形式的方法,一定存在模型上或是先/后验的约束,容易因为不恰当的约束信息而产生估计误差。在这一点上,没有具体概率密度函数形式的建模方法则是优势。这些方法主要通过采样的方式来逼近真实分布,主要有两类:一种是通过采样间接估计真实的样本分布,例如,Bengio et al. 于2014所提的Generative Stochastic Networks就属于这一类方法;另一类是通过采样直接估计真实样本的分布,目前这类方法只有GAN。相比于其他几类生成模型,GAN的优势有:1)GAN是对真实样本分布的直接估计,省去了例如利用马尔科夫链建模生成过程的累积误差;2)GAN没有具体分布形式的限制;3)GAN通过引入判别模型进行对抗的方式,可以逐步逼近真实的样本分布;4)GAN可以并行地生成样本;5)在实践中证明,GAN可以生成在主观上觉得更为优异的模型样本。
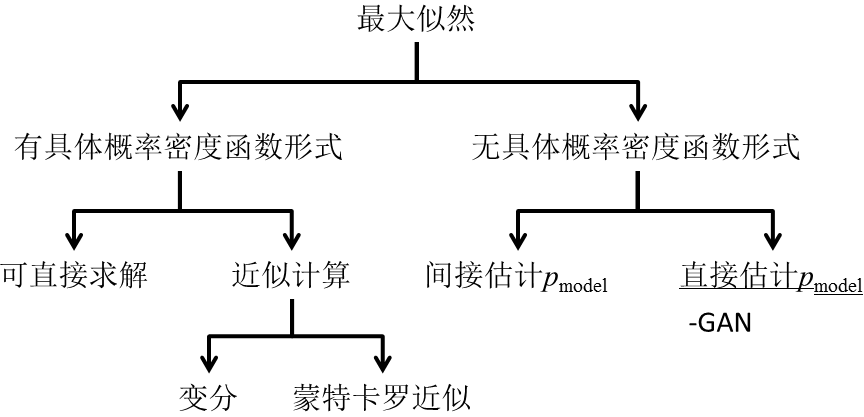
图8 生成模型的分类树
5 GAN模型的存在问题
GAN模型本身也存在相当多的问题,其中的一些的问题至今无法给出合理的解决方案,制约了其在相关领域的发展。这一部分我们不会做过多的展开,相关部分可以留到后续在特定的论文介绍工作中逐一叙述,在文章的最后我会将相关资料一一列出,有感兴趣的小伙伴也可先自行查阅。在这里,我们主要讲讲GAN在图像领域应用过程中主要遇到的几个问题:
1) 训练难。由于GAN模型中的判别和生成模型需要进行相互对抗,如果在训练之初就获得了一个相当准确的判别模型,能够区分大量生成的模型样本,那么生成模型所的损失值将会变得极大,从而使得模型参数无法正常更新。要解决这一问题,需要修改模型的损失函数,更好的平衡GAN中的判别和生成模型,使得其能够在这种情况下正常更新参数。目前两种常用的方法:(i)采用近似的生成模型损失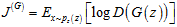
2) 解空间大导致收敛结果不够理想。由于GAN本身没有任何约束,由于其解空间极大因此对真实样本分布的拟合不容易收敛到一个较好的结果。目前两类常用的解决方法:1)在输入z上加入一定的约束条件,例如,加入条件约束的CGAN;2)减小生成模型的映射空间,例如,只学习残差的LAGAN;
3) Model collapse。GAN模型经常容易遇到多个输入z对应同一模型样本的情况。图 9展示了一个典型model collapse的例子:对于目标为二维环状点阵的图像,GAN容易一次收敛到一个模式上去,从而导致无法还原二维环状点阵图像。在其他图像生成的应用中,model collapse问题还容易使得产生的图像多样性不足。一种可能的解决方法是调换目标函数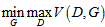

图9 典型的model collapse问题
4) GAN在图像的生成结果上还存在无法准确计数、生成图像的视角存在偏差以及全局结构模糊的问题。如图 10所示,生成的动物图像存在多个脑袋,在一个平面上同时展示多个维度以及类似头、手、足错位的结构问题。这些问题目前还制约着GAN的发展,需留待未来的工作提出对应的解决方案。

图10 GAN生成的图像所存在的数量、角度和结构问题
参考资料
Bengio, Y., Thibodeau-Laufer, E., Alain, G., and Yosinski, J. Deep generative stochastic networks trainable by backprop. In ICML’2014.
Denton, E., Chintala, S., Szlam, A., and Fergus, R. Deep generative image models using a Laplacian pyramid of adversarial networks. In NIPS’15.
Goodfellow, I., Pouget-Abadie, J., Mirza, M., Xu, B., Warde-Farley, D., Ozair, S., Courville, A., and Bengio, Y. (2014b). Generative adversarial networks. In NIPS’14.
Goodfellow, I. NIPS 2016 Tutorial: Generative Adversarial Networks. arXiv’16.
MirzaM, Osindero S. Conditional generative adversarial nets. arXiv’14.
Salimans, T., Goodfellow, I., Zaremba, W., Cheung, V., Radford, A., and Chen, X. Improved techniques for training gans. In NIPS’16.
Radford, A., Metz, L., and Chintala, S. Unsupervised representation learning with deep convolutional generative adversarial networks. arXiv’15.
GAN project: https://github.com/openai/improved-gan
iGAN project: https://github.com/junyanz/iGAN
DCGAN project: https://github.com/Newmu/dcgan_code
总结
这段时间在和小伙伴的讨论中发现利用GAN确实可以提高模型的生成能力,特别是在序列数据的生成问题上。原本利用马尔科夫链建模最大似然的方法很难准确刻画整条序列的生成过程,而GAN则有这样的能力。判别模型给予的对抗机制能够给原本无监督的生成模型提供更为丰富的信息,指导其优化过程。但GAN目前仍存在诸多问题,在除图像以外的领域还未收到很好的效果。在应用上,在商用范畴上更倾向于端到端的学习,这也可能是GAN在其他领域发展的一种制约因素吧。



