
摘要--基于模拟的训练有可能大幅提高空战领域的训练价值。然而,合成对手必须由高质量的行为模型控制,以表现出类似人类的行为。手工建立这种模型被认为是一项非常具有挑战性的任务。在这项工作中,我们研究了如何利用多智能体深度强化学习来构建空战模拟中合成飞行员的行为模型。我们在两个空战场景中对一些方法进行了实证评估,并证明课程学习是处理空战领域高维状态空间的一种有前途的方法,多目标学习可以产生具有不同特征的合成智能体,这可以刺激人类飞行员的训练。

索引词:基于智能体的建模,智能体,机器学习,多智能体系统
I. 引言
只使用真实的飞机进行空战训练是很困难的,因为飞行的成本很高,空域的规定,以及代表对方部队使用的平台的有限可用性。取而代之的是,可以用合成的、计算机控制的实体来代替一些人类角色。这可以降低训练成本,减少对人类训练提供者的依赖(见图1),并提高训练价值[1]。理想情况下,受训飞行员的对手应该都是合成实体,这样就不需要角色扮演者和真实飞机来支持训练。然而,为了达到较高的训练价值,合成对手必须由高质量的行为模型控制,并表现出类似人类的行为。手工建立这样的模型被认为是一项非常具有挑战性的任务[2], [3]。
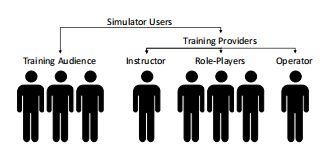
图1. 空战训练系统的用户。通过构建更智能的合成智能体,可以减少对人类训练提供者的需求。
近年来,强化学习算法的性能得到了迅速提高。通过将强化学习与深度学习相结合,在复杂的控制任务[4]-[6]、经典的棋盘游戏[7]-[9]以及具有挑战性的实时、多人计算机游戏[10],[11]中取得令人印象深刻的结果成为可能。这使我们相信,强化学习也可以成为构建空战模拟中合成智能体行为模型的一个可行的选择。有了这种方法,训练系统的用户就不需要明确地对智能体的行为进行编程,而是可以简单地指定他们所需的目标和特征。然而,目前还没有很多研究来评估空战领域中最新的多智能体学习方法的性能。
在这项工作中,我们研究了如何在空战模拟中使用多智能体深度强化学习来学习协调。在空战领域,多个智能体的协调是很重要的,因为飞行员从来不会单独飞行。我们的贡献可以总结为以下几点:
-
首先,我们讨论了用于训练飞行员的空战模拟领域的强化学习算法的用例、设计原则和挑战
-
其次,我们使用高保真模拟引擎,对有助于实现所确定的用例的方法进行了广泛的实证评估。
具体来说,我们研究了空战模拟场景中学习算法的两个挑战。1)用稀疏的奖励学习,以及2)创建具有可调整行为的智能体。我们的实验表明,在空战的高维状态空间中,课程学习可以促进稀疏奖励的学习,而多目标学习可以产生具有不同行为特征的智能体,这可以刺激飞行员的训练。



