

摘要
深度强化学习因其在解决复杂的视频游戏和工业应用方面的成功而引起了工业界和学术界的广泛关注。最近,硬件和计算方面的进步成倍地增加了计算能力的可用性,促进了深度神经网络的训练。这些网络可以从高维数据中学习RL行为策略,并且比精确的表格解决方案表现得更好,尽管需要相当多的计算机资源。
游戏是评估强化学习(RL)算法的行为特性和规划效率最常用的应用之一。它们可以提供训练深度学习模型所需的数据结构和数量。专门制作的游戏可以表达现实世界的工业应用,以减少设置成本,同时大幅提高可重复性。RL可以提高专家系统占主导地位的工业应用的效率,减少人工和潜在的危险劳动。应用工业强化学习的问题是,传统方法是通过试验和错误来学习。正因为如此,RL智能体在学习过程中存在遇到灾难性事件的风险,这可能会对人类或设备造成损害。因此,使用游戏来训练和研究安全的RL智能体很有吸引力。
即时战略(RTS)游戏由于其高维的状态和行动空间而特别吸引人。此外,RTS游戏与工业和现实世界的应用有许多共同的属性,如同时行动、不完美信息和系统随机性。最近的进展表明,无模型RL算法可以在《星际争霸II》这样的游戏中学习到超人的表现,同样使用了大量的计算能力。因此,缺点是这些算法昂贵且难以训练,使得将同样的方法用于工业应用具有挑战性。在开源环境中也有大量的状态空间复杂性的差距。这就限制了算法的评估,使其只适用于工业应用中充分操作所需的任务子集。
游戏环境:本论文通过提出六个新的游戏环境来解决环境差距问题,以评估几个任务中的RL算法。Deep Line Wars和Deep RTS是两个新的RTS环境,用于测试不完美信息下长期规划的算法。Deep Maze是一个灵活的迷宫环境,用于学习RL智能体从记忆中导航迷宫。Deep Warehouse是一个专门制作的环境,用于评估自动存储和检索系统(ASRS)中RL算法的安全性,这也是本论文的唯一重点。ASRS有自主车辆,在一个三维网格中寻求最大的物品吞吐量。拟议环境的设计目标是为RL算法的评估提供大量的额外问题。因此,所有的环境都提供了调整问题复杂性的参数和一个灵活的场景引擎,可以挑战各种问题的算法,如记忆和控制。我们的经验表明,我们的环境比类似复杂度的环境在计算上明显更有效率。提出的环境的多样性可以帮助填补文献中的复杂性空白。我们最后介绍了用于高性能RL研究的人工智能和强化学习中心(CaiRL)工具包,它在一个单一的运行时间内收集了所有提议的环境。
基于模型的RL:本论文还介绍了新的节能、高性能的RL算法,用于RTS游戏和使用所介绍的环境的工业近似模拟。无模型强化学习在模拟环境中显示出有希望的结果,但对于工业应用来说是不够的。他们需要收集数以百万计的样本并通过试验和错误来学习。相反,基于模型的强化学习(MBRL)利用已知的或学到的动力学模型,可以大幅提高样本效率。因此,与无模型的RL方法相比,基于模型的RL在工业应用中是一个更稳健的研究选择。目前基于模型的RL文献显示,基于深度学习的模型表现最好,但也有一些不足之处。深度学习模型通常对超参数很敏感,真实环境的轻微变化都会显著影响模型的准确性。此外,现有的模型在推导行为策略时并不考虑安全或风险,这使得此类方法在工业应用中存在问题。
这篇论文解决了其中的一些挑战,并提出了新的基于模型的强化学习方法,这些方法注重决策安全和样本效率。我们的算法,Dreaming变分自动编码器(DVAE),深度变分 Q 网络(DVQN)和观察奖励行动成本学习集成(ORACLE),结合了基于模型的RL和改进贝叶斯方法来训练现有和拟议环境中的动力学模型。DVAE算法使用递归神经网络和变异自动编码器来学习动力学模型,并在原始环境中显示出有效性。DVQN使用变异自动编码器和深度Q网络来实现可解释和可分离的潜在空间,并有助于分层强化学习中的自动选项发现。最后,ORACLE结合了状态空间、递归神经和随机神经网络。该算法显示了最先进的预测能力,同时使用辅助的安全目标进行更安全的学习。
然后,我们利用动力学模型的优势,离线训练无模型算法。此外,我们利用风险导向的探索和好奇心来建立对风险敏感的智能体,以提高游戏和工业应用的决策安全性。我们的经验表明,我们的方法在大多数情况下比最先进的无模型和基于模型的算法在传统的RL基准、RTS游戏和模拟的工业应用中表现更好。
总而言之,我们相信本论文中提出的游戏环境、RL方法和研究将推动所课题中最先进的研究,并为在工业应用中实现基于模型的RL做出积极的贡献。
论文大纲
本学位论文由两部分组成。第一部分概述了整个博士学习期间所进行的工作。第二部分包括代表本论文主要贡献的出版物和在审文章,见贡献清单。本论文的其余部分结构如下。
第二章:背景介绍了本论文中使用的技术的背景文献。这包括马尔科夫决策过程、强化学习、安全强化学习和各种深度学习建模技术。
第三章:文献综述介绍了强化学习的科学进展的全面文献综述,这些文献激励并启发了我们的贡献。我们研究的关键词是基于模型的、安全的、环境的、目标导向的RL、可解释的RL,以及,分层的RL。
第四章:软件贡献和评估描述了我们对新型强化学习环境的科学软件贡献。我们提出了新的环境,以填补目前最先进的状态复杂性的差距,并讨论了我们的动机,设计规范,并提供基线结果和评估。
第五章:算法贡献介绍了我们在RTS游戏中基于安全模型的强化学习的新技术的主要贡献,以实现一个功能性的工业级强化学习解决方案。具体来说,我们介绍了开展这项工作的动机,并描述了我们算法的细节。我们提供了在实验中导致最佳结果的超参数,并总结了算法的贡献。
第六章:贡献评估使用提议的软件贡献实证评估我们的算法贡献,包括强化学习文献中最先进的环境。每一节都提出了一个假设,我们的目标是在实验和评估中解决这个问题。
第七章:结论和未来的工作结束了本论文的第一部分,并讨论了进行了博士工作的最终成就。最后,我们概述了未来的研究方向,这些方向有可能改进本论文中提出的工作。
第二部分介绍了博士工作期间的全部出版物。这些论文按时间顺序排列,大致代表本论文的流程。研究进展的详细图示见图1.1。
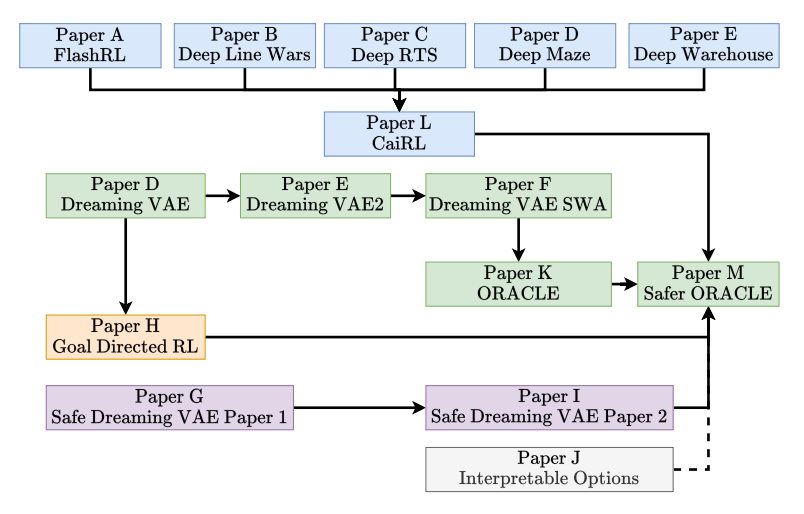
图1.1:颜色代码说明了以下主题。蓝色说明了新的研究环境的贡献,灰色是可解释性和层次性RL(选项)。紫色表示安全强化学习,黄色代表目标导向强化学习的工作。最后,绿色是我们在基于模型和安全RL方面的主要贡献。
相关内容
通常,标准的即时战略游戏会有资源采集、基地建造、科技发展等元素。在玩家指挥方面,即时战略游戏通常可以独立控制各个单位,而不限于群组式的控制,即时战略游戏在战略(Strategy)的谋定过程上必须是即时的。

