

人工智能(AI)正在成为国防工业的一个重要组成部分,最近美国DARPA的AlphaDogfight试验(ADT)证明了这一点。ADT试图审查能够在模拟空对空战斗中驾驶F-16的人工智能算法可行性。作为ADT的参与者,洛克希德-马丁公司(LM)的方法将分层结构与最大熵强化学习(RL)相结合,通过奖励塑造整合专家知识,并支持策略模块化。该方法在ADT的最后比赛中取得了第二名的好成绩(共有8名竞争者),并在比赛中击败了美国空军(USAF)F-16武器教官课程的一名毕业生。
1 引言
由DARPA组建的空战进化(ACE)计划,旨在推进空对空作战自主性并建立信任。在部署方面,空战自主性目前仅限于基于规则的系统,如自动驾驶和地形规避。在战斗机飞行员群体中,视觉范围内的战斗(dogfighting)学习包含了许多成为可信赖的机翼伙伴所必需的基本飞行动作(BFM)。为了使自主系统在更复杂的交战中有效,如压制敌方防空系统、护航和保护点,首先需要掌握BFMs。出于这个原因,ACE选择了dogfight作为建立对先进自主系统信任的起点。ACE计划的顶峰是在全尺寸飞机上进行的实战飞行演习。
AlphaDogfight Trials(ADT)是作为ACE计划的前奏而创建的,以减轻风险。在ADT中,有八个团队被选中,其方法从基于规则的系统到完全端到端的机器学习架构。通过试验,各小组在高保真F-16飞行动力学模型中进行了1对1的模拟搏斗。这些比赛的对手是各种敌对的agent。DARPA提供了不同行为的agent(如快速平飞,模仿导弹拦截任务),其他竞争团队的agent,以及一个有经验的人类战斗机飞行员。
在本文中,我们将介绍环境、agent设计、讨论比赛的结果,并概述我们计划的未来工作,以进一步发展该技术。我们的方法使用分层强化学习(RL),并利用一系列专门的策略,这些策略是根据当前参与的背景动态选择的。我们的agent在最后的比赛中取得了第二名的成绩,并在比赛中击败了美国空军F-16武器教官课程的毕业生(5W - 0L)。
2 相关工作
自20世纪50年代以来,人们一直在研究如何建立能够自主地进行空战的算法[1]。一些人用基于规则的方法来处理这个问题,使用专家知识来制定在不同位置背景下使用的反机动动作[2]。其他的探索以各种方式将空对空场景编成一个优化问题,通过计算来解决[2] [3] [4] [5] [6]。
一些研究依赖于博弈论方法,在一套离散的行动上建立效用函数[5] [6],而其他方法则采用各种形式的动态规划(DP)[3] [4] [7]。在许多这些论文中,为了在合理的时间内达到近似最优的解决方案,在环境和算法的复杂性方面进行了权衡[5] [6] [3] [4] [7] 。一项值得注意的工作是使用遗传模糊树来开发一个能够在AFSIM环境中击败美国空军武器学校毕业生的agent[8]。
最近,深度强化学习(RL)已被应用于这个问题空间[9] [10] [11] [12] [13] [14]。例如,[12]在一个定制的3-D环境中训练了一个agent,该agent从15个离散的机动动作集合中选择,并能够击败人类。[9]在AFSIM环境中评估了各种学习算法和场景。一般来说,许多被调查的深度RL方法要么利用低保真/维度模拟环境,要么将行动空间抽象为高水平的行为或战术[9] [10] [11] [12] [13] [14]。
与其他许多作品相比,ADT仿真环境具有独特的高保真度。该环境提供了一个具有六个自由度的F-16飞机的飞行动力学模型,并接受对飞行控制系统的直接输入。该模型在JSBSim中运行,该开源软件被普遍认为对空气动力学建模非常精确[15] [16]。在这项工作中,我们概述了一个RL agent的设计,它在这个环境中展示了高度竞争的战术。
3 背景-分层强化学习
将一个复杂的任务划分为较小的任务是许多方法的核心,从经典的分而治之算法到行动规划中生成子目标[36]。在RL中,状态序列的时间抽象被用来将问题视为半马尔科夫决策过程(SMDP)[37]。基本上,这个想法是定义宏观行动(例程),由原始行动组成,允许在不同的抽象层次上对agent进行建模。这种方法被称为分层RL[38][39],它与人类和动物学习的分层结构相类似[40],并在RL中产生了重要的进展,如选项学习[41]、通用价值函数[42]、选项批评[43]、FeUdal网络[44]、被称为HIRO的数据高效分层RL[45]等。使用分层RL的主要优点是转移学习(在新的任务中使用以前学到的技能和子任务),可扩展性(将大问题分解成小问题,避免高维状态空间的维度诅咒)和通用性(较小的子任务的组合允许产生新的技能,避免超级专业化)[46]。
我们使用策略选择器的方法类似于选项学习算法[41],它与[47]提出的方法密切相关,在这些方法中,子策略被分层以执行新任务。在[47]中,子策略是在类似环境中预训练的基元,但任务不同。我们的策略选择器(类似于[47]中的主策略)学习如何在一组预先训练好的专门策略下优化全局奖励,我们称之为低级策略。然而,与关注元学习的先前工作[47]不同,我们的主要目标是通过在低级策略之间动态切换,学习以最佳方式对抗不同的对手。此外,考虑到环境和任务的复杂性,我们不在策略选择器和子策略的训练之间进行迭代,也就是说,在训练策略选择器时,子策略agent的参数不被更新。
4 ADT仿真环境
为dogfighting场景提供的环境是由约翰霍普金斯大学应用物理实验室(JHU-APL)开发的OpenAI体育场环境。F-16飞机的物理特性是用JSBSim模拟的,这是一个高保真的开源飞行动力学模型[48]。环境的渲染图见图1。
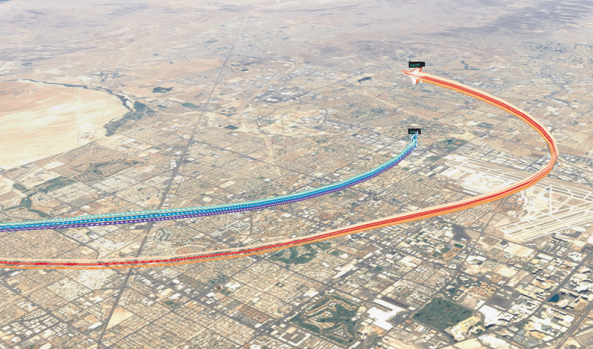
图1: 仿真环境的渲染图
每个agent的观察空间包括关于自己的飞机(燃料负荷、推力、控制面偏转、健康状况)、空气动力学(α和β角)、位置(本地平面坐标、速度和加速度)和姿态(欧拉角、速率和加速度)的信息。agent还获得其对手的位置(本地平面坐标和速度)和态度(欧拉角和速率)信息以及对手的健康状况。所有来自环境的状态信息都是在没有建模传感器噪声的情况下提供的。
每一模拟秒有50次行动输入。agent的行动是连续的,并映射到F-16的飞行控制系统(副翼、升降舵、方向舵和油门)的输入。环境给予的奖励是基于agent相对于对手的位置,其目标是将对手置于其武器交战区(WEZ)内。
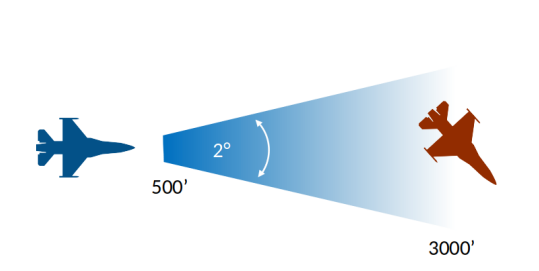
图2:武器交战区(WEZ)
WEZ被定义为位于2度孔径的球形锥体内的点的位置,该锥体从机头延伸出来,也在500-3000英尺之外(图2)。尽管agent并没有真正向其对手射击,但在本文中,我们将把这种几何形状称为 "枪响"。
5 agent结构
我们的agent,PHANG-MAN(MANeuvers的自适应新生成的策略层次),是由两层策略组成的。在低层,有一个策略阵列,这些策略已经被训练成在状态空间的一个特定区域内表现出色。在高层,一个单一的策略会根据当前的参与情况选择要激活的低层策略。我们的架构如图4所示。
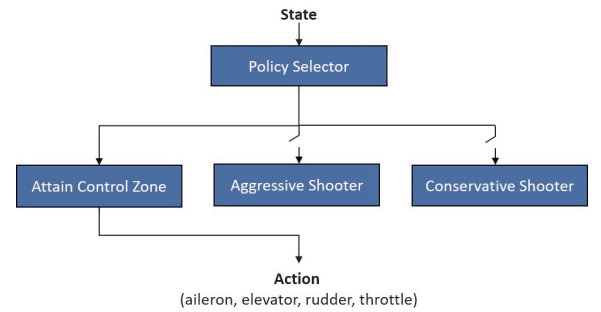
图4:PHANG-MAN agent的高层结构




