不断发展的强化学习算法


发布人:Google Research 研究实习生 John D. Co-Reyes 和高级软件工程师 Yingjie Miao
对于研究强化学习 (RL) 而言,长期的首要目标之一是设计一个可以解决各种问题的通用学习算法。然而,由于 RL 算法的分类过于庞大,并且设计新的 RL 算法需要大量的调优和验证,因此这个目标十分棘手。可行的解决方案之一是设计一种元学习 (Meta Learning) 方法,利用该方法设计出新的 RL 算法,然后让这些算法能够自动泛化到各种各样的任务中。
近年来,AutoML 在机器学习组件(如神经网络架构和模型更新规则)的自动化设计方面取得了巨大成功。其中一个例子是神经架构搜索 (NAS),目前已被应用于开发更好的图像分类神经网络架构,以及在手机和硬件加速器上运行的高效架构。除了 NAS,AutoML-Zero 还显示出它甚至有望通过基本的数学运算从头开始学习整个算法。这些方法有一个共同的主题,即用一个图来表示神经网络架构或整个算法,并使用另外一种算法优化该图以达到特定目标。
这些早期的方法是为监督式学习 (Supervised Learning) 而设计的,在监督学习中,整个算法更加简单。但在 RL 中,有更多的算法组件可能成为设计自动化的潜在目标(例如,用于代理网络的神经网络架构、重放缓冲区采样策略、损失函数的总体表达式),为了集成这些组件,我们并非总能对最佳模型更新程序做到心中有数。以往对自动化 RL 算法的研究重点集中在模型更新规则上。这些方法学习优化器或 RL 更新程序本身,通常用神经网络(如 RNN 或 CNN)表示更新规则,这些神经网络可以用基于梯度的方法进行有效优化。然而,这些习得的规则不具有可解释性和普适性,因为所习得的权重是不透明且特定于某个网域的。
代理网络
https://tensorflow.google.cn/agents/tutorials/8_networks_tutorial
在我们的论文《不断发展的强化学习算法》(Evolving Reinforcement Learning Algorithms) 中(收录于 ICLR 2021),我们证明了可以通过使用图示法和应用 AutoML 社区的优化方法学习可用分析方法加以解释和泛化的新 RL 算法。具体而言,我们将以计算图的形式表示用于根据代理的经验优化其参数的损失函数,并使用正则化进化算法在一组简单的训练环境中发展一系列计算图。如此将发展出越来越好的 RL 算法,并可以将发现的算法泛化到更复杂的环境中,甚至是雅达利 (Atari) 游戏这样具有视觉观察值的环境中。


受 NAS 概念(搜索表示神经网络架构的图表空间)的启发,我们通过将 RL 算法的损失函数表示为计算图来元学习 RL 算法。在这种情况下,我们使用一个有向无环图表示损失函数,用节点表示输入、运算符、参数和输出。例如,在 DQN 的计算图中,输入节点包括重放缓冲区的数据,操作节点包括神经网络运算符和基本数学运算符,输出节点代表损失,可利用梯度下降算法达到最小值。
这种表示方法的好处很多。它足以定义现有的算法,还可以定义新的未发现的算法。同时它也具有可解释性。用户可以像分析人类设计的 RL 算法一样,对这种图示法进行分析,使其比在整个 RL 更新过程中使用黑盒函数逼近器的方法更具可解释性。如果研究人员能够理解为什么习得的算法更好,那么他们就可以调整算法的内部组件加以改进,并将有益的组件推及到其他问题上。最后,这种表示法还可支持用于解决各类问题的通用算法。
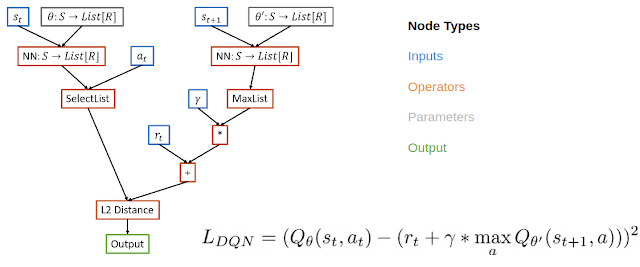
用于计算平方贝尔曼误差的 DQN 计算图示例
此表示法由 PyGlove 库实现,该库能够方便地将图表转换为可以通过正则化进化算法进行优化的搜索空间。
我们采用一种基于进化的方法来优化相关的 RL 算法。首先,用随机图初始化一系列训练代理。在一组训练环境中并行训练这些代理。首先在障碍环境,即简单的环境中加以训练,如 CartPole,旨在快速淘汰表现不良的程序。
如果一个代理不能解决障碍环境,训练就会提前终止,得分为零。否则,继续提升训练环境的难度(例如,Lunar Lander、简单的 MiniGrid 环境等)。评估算法性能,并用来更新所有代理,在此过程中进一步演变出更出色的算法。为减少搜索空间,我们使用一个功能等价性检查工具,它将跳过功能和已查算法相同的新提出的算法。这个循环不断继续,不断训练和评估从中演化出的新算法。训练结束后,选择最好的算法,并在一组未知的测试环境中评估其性能。
MiniGrid
https://github.com/maximecb/gym-minigrid
参加实验的代理大约有 300 个,我们发现其在两万到五万次演化后终于发展出理想的损失函数,而这需要大约 3 天的训练。我们之所以能够在 CPU 上进行训练,是因为训练环境很简单,便于我们控制训练的计算和能源消耗。为了进一步控制训练成本,我们用 DQN 等人工设计的 RL 算法来播下第一批代理的种子。
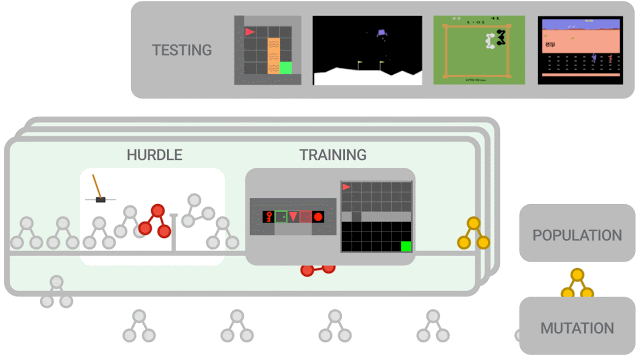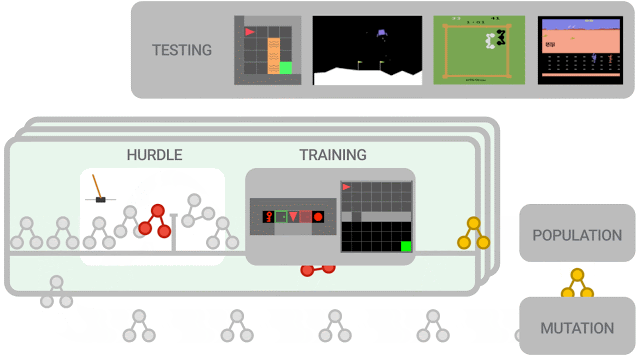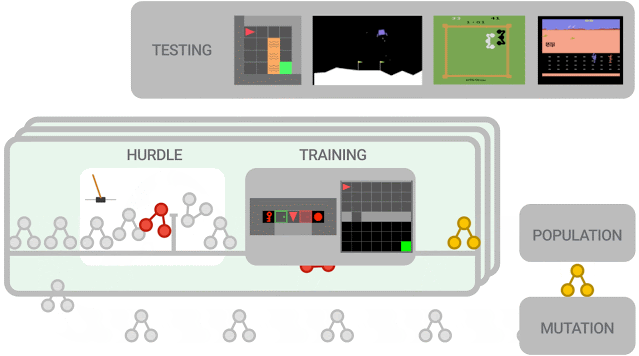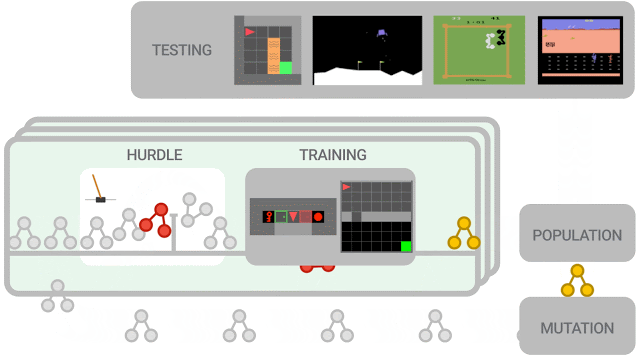
元学习方法概览。新提出的算法首先必须在障碍环境中表现良好,然后才能进入一组更困难的环境中进行训练。使用算法性能更新所有代理,在此过程中较好的算法进一步演变出新算法。训练结束后,在测试环境中对性能最好的算法进行评估
我们突出显示了两种表现出良好泛化性能的算法。第一个是 DQNReg,它建立在 DQN 的基础上,在标准的平方贝尔曼误差上增加了对 Q 值的加权惩罚。第二个习得损失函数是 DQNClipped,尽管它的支配项形式简单:Q 值的最大值和平方贝尔曼误差(常数模),但却更为复杂。这两种算法都可以看作是正则化 Q 值的方法。DQNReg 添加了软约束,而 DQNClipped 则可以解释为一种约束优化,若二者的内存占用过大,将使 Q 值最小化。我们分析表明,当高估 Q 值成为潜在问题时,这种习得约束在训练的早期阶段就开始了。一旦此约束条件得到满足,损失将最小化初始平方贝尔曼误差。
一项更深入的分析显示,虽然 DQN 等基线通常会高估 Q 值,但我们的习得算法都以不同的方式解决这一问题。DQNReg 会低估 Q 值,而 DQNClipped 的做法则类似于 double dqn,它会缓慢地接近基本事实,而不是高估它。
值得一提的是,在进化的过程中植入 DQN 时,这两种算法会不断出现。此方法从零开始学习,重新发现 TD 算法。为了实现完整性,我们发布了一个数据集,其中包含进化过程中发现的前 1000 个良好性能算法。好奇的读者可以进一步研究这些习得损失函数的性质。
发布了一个数据集
https://github.com/jcoreyes/evolvingrl
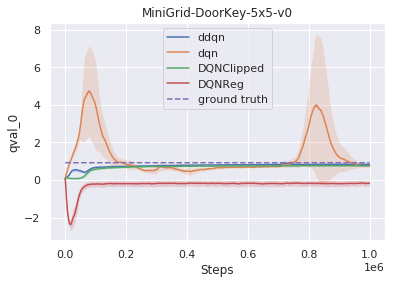
在基于价值的 RL 中,高估值通常是一个问题。我们的方法会通过学习能够正则化 Q 值的算法来减少高估
在 RL 中泛化通常指的是经过训练的策略在不同任务之间泛化。然而,在这项工作中,我们关注的是算法泛化性能,换言之,一个算法在一组环境中的表现情况。在一组经典控制环境下,习得算法在密集奖励任务 (CartPole、Acrobot、LunarLander) 中的性能与基线持平,在稀疏奖励任务 (MountainCar) 中,其性能优于 DQN。
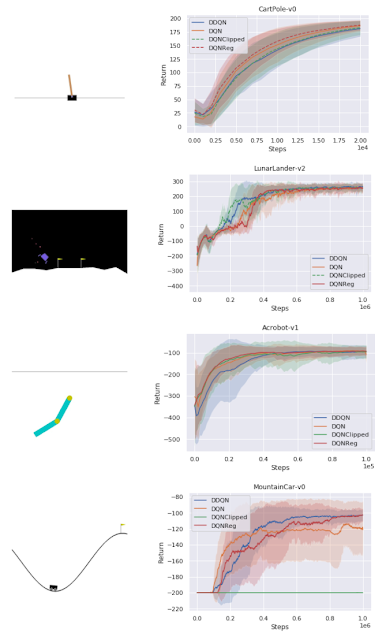
在经典控制环境中习得算法的性能与基线的比较
其中,在一组测试各种不同任务的稀疏奖励 MiniGrid 环境中,研究人员发现 DQNReg 在训练和测试环境中的采样效率和最终性能都大大超过基线水平。事实上,此结果在大小、配置以及是否存在新障碍(如 lava)等情况各异的测试环境中更为明显。
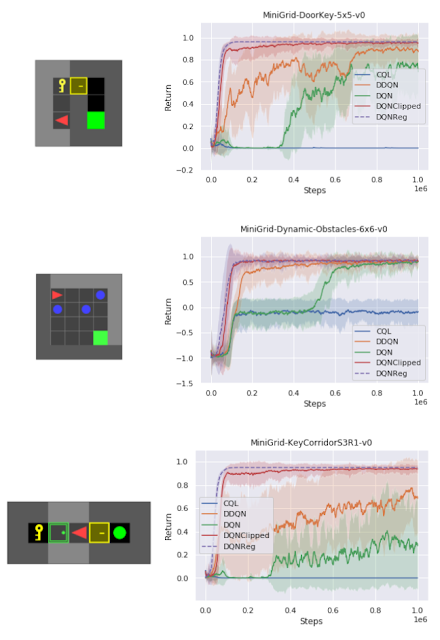
以协程返回超过 10 个训练种子的标准来衡量训练环境性能与训练步骤之间的关系。DQNReg 在采样效率和最终性能方面可以持平甚至超过基线水平
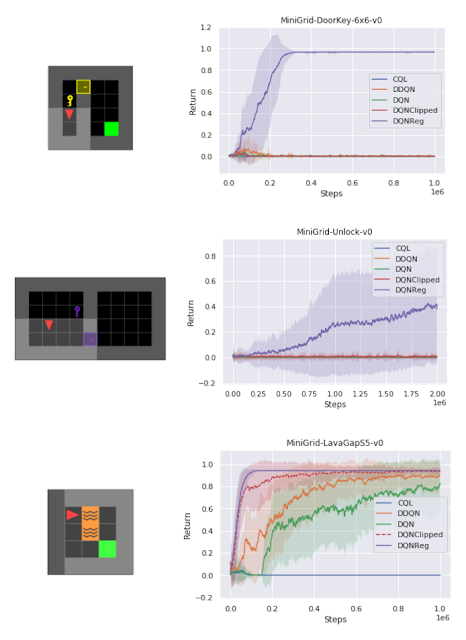
在未知测试环境中,DQNReg 的性能可以大大优于基线水平
我们在一些 MiniGrid 环境中将标准 DDQN 与习得算法 DQNReg 的性能进行可视化比较。这些环境的起始位置、墙壁配置和对象配置在每次重置时都是随机选取的,这要求代理进行泛化,而不是简单地记忆环境信息。通常,当 DDQN 还在艰难地学习有意义的行为时,DQNReg 已经能够有效地学习最优行为了。
即使本文中的训练是在基于非图像的环境中进行的,但在基于图像的雅达利游戏环境中,我们也观察到了 DQNReg 算法性能的提高。这表明,使用可泛化的算法表示法在一组廉价但多样化的训练环境中进行元训练,可以彻底实现算法泛化

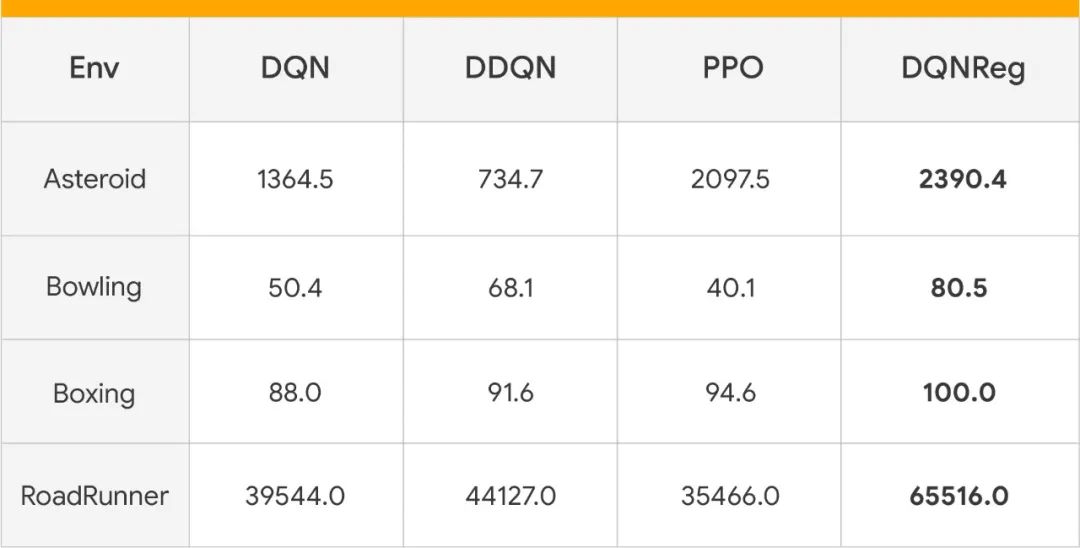
在若干雅达利游戏中,习得算法 DQNReg 的性能与基线的比较。每经过 100 万步,就有超过 200 个测试集接受性能评估
在这篇博文中,我们讨论了如何学习新的可解释 RL 算法,方法是将其损失函数表示为计算图,并在此表示法上发展出一系列代理。借助计算图表这样的表达方式,研究人员得以在人工设计算法的基础上进行构建,并使用与现有算法相同的数学工具集来研究习得算法。我们分析了一些习得算法,可以将它们解释为熵正则化的一种形式以避免对值做出高估。这些习得算法拥有优于基线水平的性能,并可泛化到未知环境。性能最优的算法可用于进一步的分析研究。
我们希望未来的工作可以涉及更多样化的 RL 设置,如行为评判算法或离线 RL。此外,我们希望这项工作也可以推动机器辅助算法的发展,在这过程中计算元学习可以帮助研究人员寻找新的方向,并将习得算法纳入其工作中。
本研究系与 Daiyi Peng、Esteban Real、Sergey Levine、Quoc V. Le、Honglak Lee 和 Aleksandra Faust 合作完成,在此表示感谢。同样感谢 Luke Metz 在早期对论文提出的宝贵意见和反馈,感谢 Hanjun Dai 在早期针对相关研究思路提出的宝贵意见,感谢 Xingyou Song、Krzysztof Choromanski 和 Kevin Wu 在基础设施方面的帮助,感谢 Jongwook Choi 在环境选择方面的帮助。最后,感谢 Tom Small 为这篇博文设计动画。

点击“阅读原文”访问 TensorFlow 官网

不要忘记“一键三连”哦~

分享

点赞

在看
