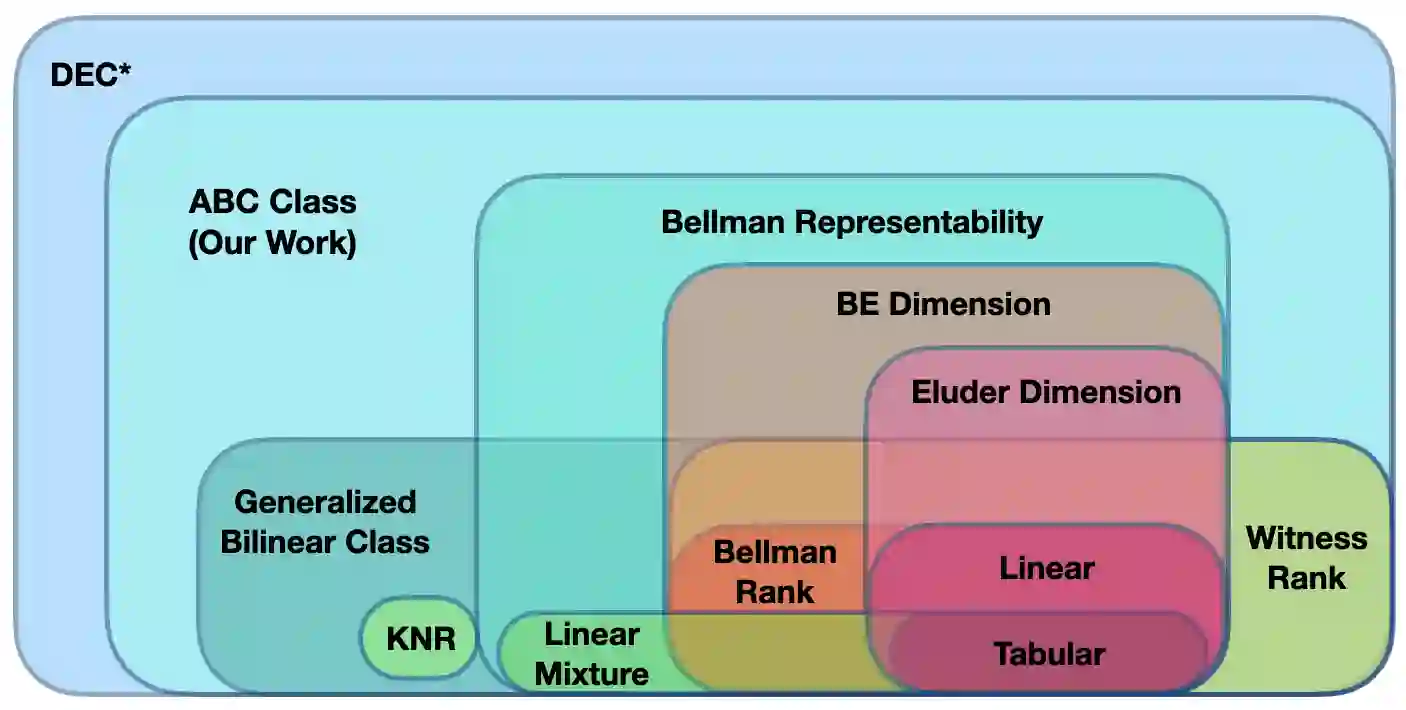
With the increasing need for handling large state and action spaces, general function approximation has become a key technique in reinforcement learning (RL). In this paper, we propose a general framework that unifies model-based and model-free RL, and an Admissible Bellman Characterization (ABC) class that subsumes nearly all Markov Decision Process (MDP) models in the literature for tractable RL. We propose a novel estimation function with decomposable structural properties for optimization-based exploration and the functional eluder dimension as a complexity measure of the ABC class. Under our framework, a new sample-efficient algorithm namely OPtimization-based ExploRation with Approximation (OPERA) is proposed, achieving regret bounds that match or improve over the best-known results for a variety of MDP models. In particular, for MDPs with low Witness rank, under a slightly stronger assumption, OPERA improves the state-of-the-art sample complexity results by a factor of $dH$. Our framework provides a generic interface to design and analyze new RL models and algorithms.
翻译:随着对处理大型州和行动空间的日益需要,一般功能近似已成为强化学习的关键技术(RL)。在本文件中,我们提议了一个统一基于模型和无模型的RL和可允许的贝尔曼特性(ABC)类总框架,将几乎所有的Markov 决策程序(MDP)模型都纳入可移植的RL文献中。我们提议了一个新的估算功能,其中含有基于优化的勘探的可分解结构特性和功能性极差层面,作为ABC类的复杂度衡量标准。在我们的框架内,我们提出了一个新的样本高效算法,即基于OPOPimiz-Exploration with Approcismation(OPERA), 实现与各种MDP模型最著名的结果相匹配或改进的遗憾界限。特别是,对于证人级别低的MDP,根据略微强的假设,OPERA将最新样本复杂度结果改进了以美元计。我们的框架为设计和分析新的RL模型和算法提供了通用界面。