大型语言模型(LLMs)的指数式增长不断凸显出高效策略以应对日益扩大的计算与数据需求的重要性。本综述对两种互补范式——知识蒸馏(KD)与数据集蒸馏(DD)——进行了全面分析,这两种方法旨在在压缩 LLMs 的同时,保留其先进的推理能力和语言多样性。 我们首先回顾了知识蒸馏中的关键方法,包括任务特定对齐、基于推理过程的训练(rationale-based training)以及多教师框架;同时也探讨了数据集蒸馏技术,如基于优化的梯度匹配、潜空间正则化和生成式合成,以便构建紧凑且高效的数据集。在此基础上,我们进一步探讨了如何融合 KD 与 DD,以实现更高效、更具扩展性的压缩策略。这些方法共同应对了模型可扩展性、架构异质性以及 LLM 新兴能力保持等持续性挑战。
此外,我们强调了蒸馏技术在医疗、教育等领域的应用,这些技术使得高效部署成为可能,同时不牺牲性能。尽管已有大量进展,但仍存在一些开放性挑战,例如:如何在压缩过程中保持新兴推理能力和语言多样性,如何高效适应持续演变的教师模型与数据集,以及如何建立全面的评估协议。 通过综合方法创新、理论基础和实践洞见,本综述为通过更加紧密整合 KD 和 DD 原则,实现可持续、资源高效的大型语言模型,描绘了一条清晰的发展路径。 关键词:大型语言模型、知识蒸馏、数据集蒸馏、效率、模型压缩、综述
1 引言
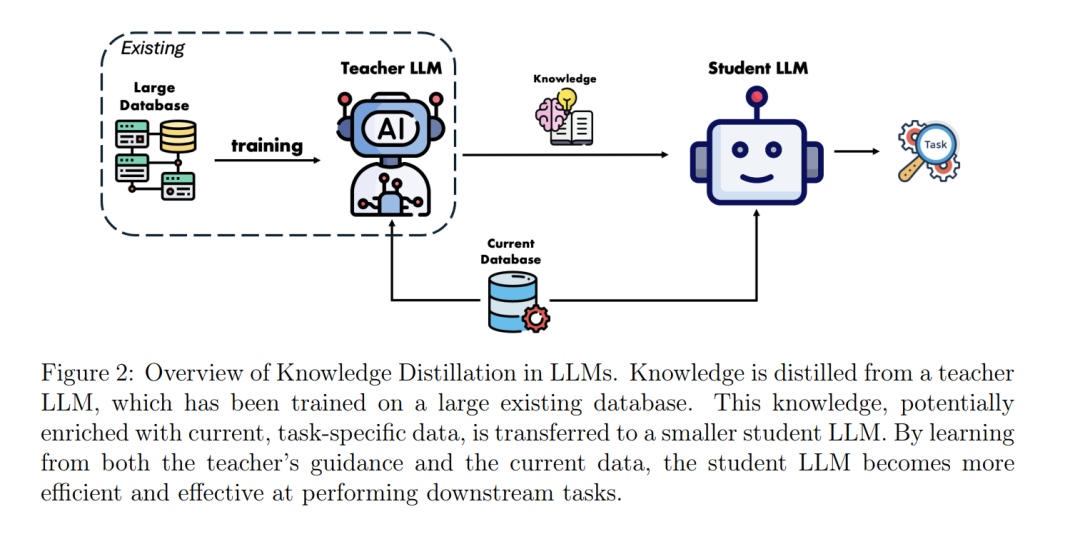
大型语言模型(LLMs)的出现,如 GPT-4(Brown 等,2020)、DeepSeek(Guo 等,2025)和 LLaMA(Touvron 等,2023),彻底改变了自然语言处理领域,使得翻译、推理和文本生成等任务的能力达到了前所未有的水平。尽管取得了这些里程碑式的成就,但与此同时,也带来了实际部署中显著的挑战。首先,LLMs 需要极其庞大的计算资源,通常需要数千 GPU 小时用于训练和推理,这导致了高能耗和显著的环境成本。其次,它们对大规模训练数据集的依赖引发了数据效率、质量和可持续性的担忧,随着公共语料库的过度使用,保持数据的多样性和高质量变得愈加困难(Hadi 等,2023)。此外,LLMs 展现出诸如链式推理(chain-of-thought reasoning,Wei 等,2022)等新兴能力,而在较小模型中复制这些能力则非常具有挑战性,需要复杂的知识迁移技术。 为了应对这些挑战,蒸馏(distillation)作为一项关键策略应运而生,结合了知识蒸馏(Knowledge Distillation,KD)(Hinton 等,2015)与数据集蒸馏(Dataset Distillation,DD)(Wang 等,2018),以同时解决模型压缩和数据效率问题。尤其重要的是,在 LLM 场景中,KD 的成功极大地依赖于 DD 技术,后者能够通过紧凑且信息丰富的合成数据集来提炼和传递教师模型(teacher LLMs)中的复杂知识。 知识蒸馏(KD)通过对齐输出或中间表示,从大型预训练教师模型向较小、高效的学生模型传递知识。尽管在中等规模教师模型中 KD 效果显著,但在面对 LLMs 的庞大规模时,传统 KD 方法遇到了挑战,因为知识分布在数十亿参数和复杂注意力模式中。此外,知识不仅限于输出分布或中间表示,还包括更高阶的能力,如推理能力和复杂问题求解能力(Wilkins 和 Rodriguez,2024;Zhao 等,2023;Latif 等,2024)。 数据集蒸馏(DD)旨在将大型训练数据集压缩成保留必要信息的紧凑型合成数据集。近期研究表明,DD 能显著降低 LLM 训练所需的计算成本,同时维持性能。例如,DD 能将数百万训练样本浓缩成数百个合成示例,并保留特定任务的知识(Cazenavette 等,2022;Maekawa 等,2024)。在 LLM 场景下,DD 成为 KD 的重要辅助,它能识别高度影响力的训练示例,反映教师模型的推理过程,从而引导学生模型高效学习,同时避免对冗余数据的过拟合(Sorscher 等,2022)。 LLMs 的规模引发了双重挑战:一是对不可持续大规模数据集的依赖(Hadi 等,2023),二是新兴能力(如链式推理(Wei 等,2022))的精准迁移需求。这些挑战促使研究者必须在 KD 和 DD 上双管齐下。虽然 KD 通过知识迁移实现模型压缩,但传统 KD 无法单独解决数据效率危机:训练新一代 LLMs 时使用冗余或低质量数据只会带来收益递减现象(Albalak 等,2024)。DD 则通过构建紧凑且高保真度的数据集(例如,稀有推理模式(Li 等,2024))来补充 KD 的不足,正如 LIMA 项目所展示的,1,000 个示例便能达到教师级别性能(Zhou 等,2023)。这种协同利用了 KD 在表征迁移上的优势与 DD 在生成任务特定数据上的能力,共同解决了隐私保护、计算负载和数据稀缺问题,使得小型模型在保持蒸馏效率的同时,也能保留大模型的重要能力。 本综述系统梳理了适用于 LLMs 的 KD 与 DD 技术,并进一步探讨了二者的融合。传统 KD 将教师模型的知识迁移至学生模型,但面对现代 LLMs 的前所未有规模,捕捉新兴能力及保留深层知识成为重大挑战。DD 通过合成小规模、高影响力的数据集,保留了语言、语义及推理多样性,有效辅助了 KD。本综述以独立的 KD 与 DD 技术进展为基础,同时深入探讨了它们结合后对模型压缩、训练效率及资源感知部署带来的潜力。 随后各章节将围绕以下关键方面展开: * 第 2 节:KD 与 DD 的基础知识,区分它们在压缩 LLMs 和优化训练效率方面的角色; * 第 3 节:LLMs 中 KD 的方法学,包括基于推理过程的蒸馏(rationale-based distillation)、不确定性感知方法、多教师框架、动态/自适应策略以及任务特定蒸馏,并回顾相关理论研究以深入理解 KD 的基本原理; * 第 4 节:LLMs 中 DD 的方法学,涵盖基于优化的数据集蒸馏、合成数据生成和辅助的数据选择策略; * 第 5 节:KD 与 DD 的整合,介绍结合 KD 与 DD 策略的统一框架以提升 LLMs; * 第 6 节:评估指标,关注蒸馏在 LLMs 中的性能保持、计算效率和鲁棒性; * 第 7 节:跨医疗健康、教育、生物信息学等领域的应用示例,展示蒸馏技术在真实场景中的实用价值; * 第 8 节:挑战与未来方向,识别需要改进的关键领域。
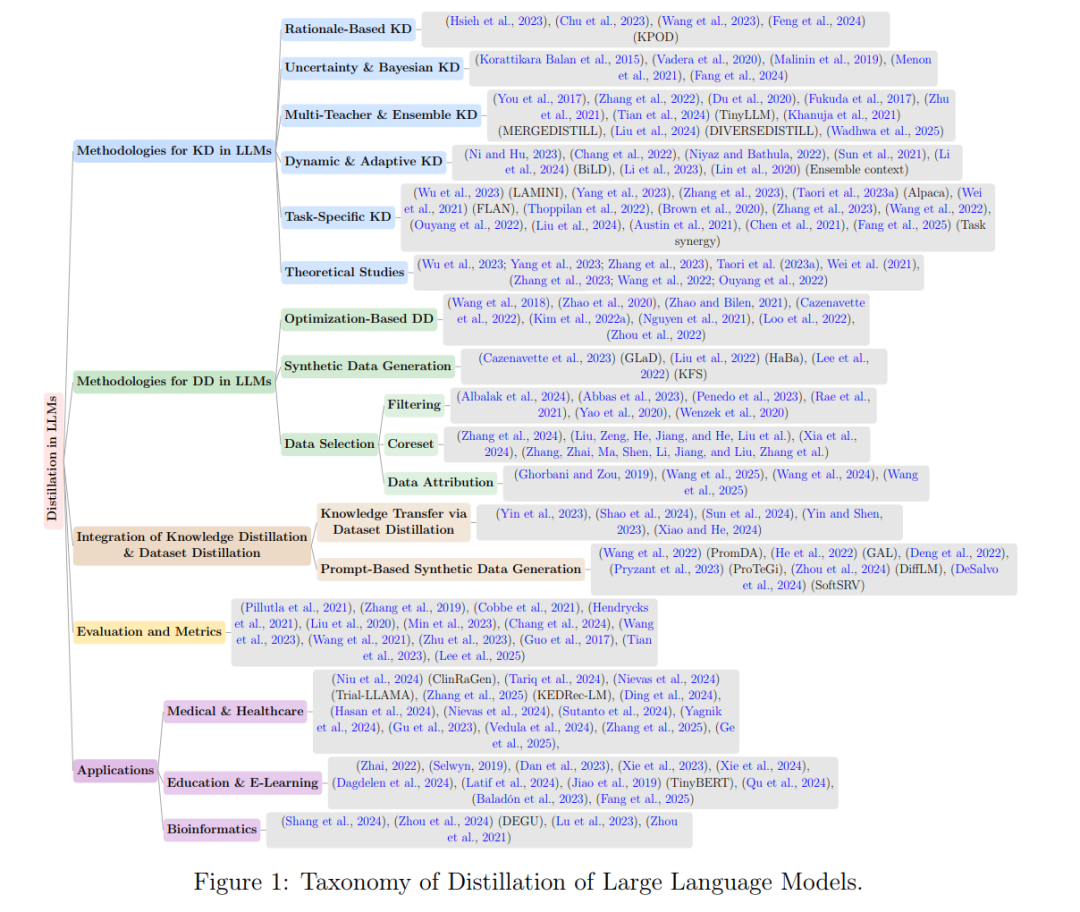
本综述的知识结构分类见图 1 所示。