

大型语言模型(LLMs)在各个领域展示了卓越的能力,吸引了学术界和工业界的广泛关注。尽管它们表现出色,但LLMs的巨大规模和计算需求对实际部署带来了相当大的挑战,特别是在资源有限的环境中。压缩语言模型同时保持其精度的努力已成为研究的重点。在各种方法中,知识蒸馏已成为一种有效的技术,可以在不大幅降低性能的情况下提高推理速度。本文从方法、评估和应用三个方面进行了详细的调查,探讨了专门为LLMs量身定制的知识蒸馏技术。具体来说,我们将方法分为白盒KD和黑盒KD,以更好地说明它们的差异。此外,我们还探讨了不同蒸馏方法之间的评估任务和蒸馏效果,并提出了未来研究的方向。通过深入理解最新进展和实际应用,这项调查为研究人员提供了宝贵的资源,为该领域的持续进步铺平了道路。
** 简介**
大型语言模型(LLMs)[2, 17, 130, 146, 166] 的出现显著提高了各种生成任务中的文本生成质量,成为人工智能领域一个关键且广受讨论的话题。与之前的模型相比,这些模型对未见数据的泛化能力更强。此外,它们还展示了小型模型所不具备的能力,如多步推理[47, 69, 83] 和指令执行[103, 144, 154]。LLMs的成功通常归因于训练数据的增加和模型参数数量的增加(例如,具有1750亿参数的GPT-3[12])。然而,参数规模的扩展带来了显著的缺点,尤其是在高推理成本和大量内存需求方面,使得实际部署变得具有挑战性。例如,GPT-3需要大约350GB的模型存储(float16),并且推理至少需要5个每个80GB内存的A100 GPU,这对碳排放的影响显著。为了解决这些挑战,模型压缩[30, 40] 已成为一种可行的解决方案。模型压缩旨在将大型、资源密集型模型转化为适合在受限移动设备上存储的更紧凑版本。这一过程可能涉及优化以减少延迟以实现更快的执行,或在最小延迟和模型性能之间取得平衡。因此,在现实场景中应用这些高容量模型的一个关键目标是压缩它们,减少参数数量,同时保持最大性能。
随着减少计算资源需求的必要性日益重要,知识蒸馏(Knowledge Distillation, KD)[43] 作为一种有前景的技术出现。KD是一种机器学习方法,专注于通过从大型复杂模型向更小、更高效的模型传递知识来压缩和加速模型。这种技术经常被用来将存储在大型深度神经网络模型中的知识浓缩到更小的模型中,从而减少计算资源需求并提高推理速度而不会大幅牺牲性能。从根本上讲,知识蒸馏利用大型模型在大量数据集上获得的广泛知识来指导较小模型的训练。这些知识通常包括输出概率分布、中间层表示和大型模型的损失函数。在训练过程中,较小的模型不仅要匹配原始数据标签,还要模仿较大模型的行为。对于像GPT-4[2]这样只能通过API访问的高级模型,生成的指令和解释可以帮助训练学生模型[54]。随着知识蒸馏的最新进展,许多研究综合了各种蒸馏技术的最新进展。具体来说,Gou等[37] 对知识蒸馏进行了广泛的综述,涉及六个关键方面:知识类别、训练方案、师生架构、蒸馏算法、性能比较和应用。同样,Wang等[141] 详细总结了与视觉任务相关的知识蒸馏技术的研究进展和技术细节。Alkhulaifi等[4] 介绍了一种创新的度量标准,称为蒸馏度量标准,他们用它来评估不同的知识压缩方法。此外,Hu等[48] 探讨了跨多个蒸馏目标的各种师生架构,提出了不同的知识表示及其相应的优化目标,并系统地概述了师生架构,结合了代表性的学习算法和有效的蒸馏方案。
现有关于知识蒸馏的综述为模型压缩奠定了重要基础并提供了宝贵的见解[13, 51, 64]。然而,LLMs的出现给KD带来了若干新挑战:1)大型语言模型设计并非仅用于单一任务如文本生成,而是广泛应用于各种任务和未见数据,包括新兴能力。因此,评估压缩LLMs的泛化能力需要仔细和全面的评估。2)现有综述仅是对现有工作的总结,未提供将KD技术应用于压缩和部署LLMs的具体示例。这种案例研究可以帮助读者为不同规模的LLMs选择最佳的KD方案。
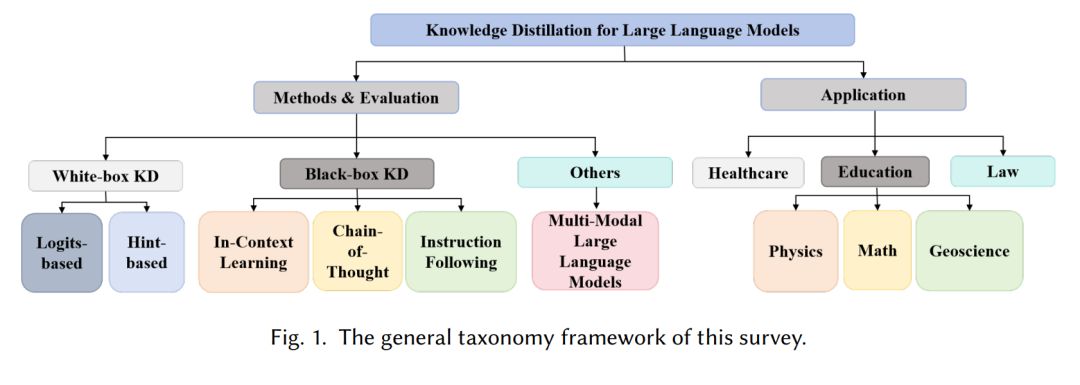
为应对这些挑战,已经开发出各种专为LLMs设计的知识蒸馏算法。本文旨在提供这些方法的全面而有见地的指南。我们的调查的总体分类框架如图1所示,从方法、评估和应用三个方面审视LLMs的蒸馏算法。为了清楚解释这些方法,我们将其分为白盒KD和黑盒KD。白盒KD包括两种不同类型:基于Logits的方法[43],在Logits层面传递知识,以及基于Hint的方法[109],通过中间特征传递知识。黑盒KD涉及一种基于API的方法,其中仅能访问教师模型的输出。此类别通常包括三种方法:上下文学习[52]、链式思维[69] 和指令执行[144]。此外,我们同时评估了上述两种蒸馏算法在鲁棒性基准上的有效性[94, 128, 138]。最后,我们讨论了不同蒸馏方法之间的关系和应用场景,并提出了未来研究方向。
本文其余部分安排如下:第2节简要回顾了知识蒸馏方法的定义。接下来,第3节深入探讨了LLMs领域的蒸馏和评估方法。第4节展示了应用场景,第5节总结了知识蒸馏的挑战并探讨了未来研究方向。最后,第6节对本文进行了总结。