

人类通过多种感官,如视觉、嗅觉、听觉和触觉来感知世界。同样,多模态大型语言模型(MLLMs)通过整合和处理包括文本、视觉、音频、视频和3D环境在内的多种模态数据,增强了传统大型语言模型的能力。数据在这些模型的发展和优化中起到了关键作用。在这篇综述中,我们从数据中心视角全面回顾了MLLMs的相关文献。具体而言,我们探讨了在MLLMs预训练和适应阶段准备多模态数据的方法。此外,我们还分析了数据集的评估方法,并回顾了评估MLLMs的基准测试。我们的综述还概述了未来潜在的研究方向。本研究旨在为研究人员提供关于MLLMs数据驱动方面的详细理解,促进该领域的进一步探索和创新。
近年来,我们见证了大型语言模型(LLMs)和多模态大型语言模型(MLLMs)的快速发展[280, 324]。诸如GPT-4 [208]、Flamingo [4]、BLIP2 [151]和X-InstructBLIP [212]等MLLMs整合了多模态信息,展示了令人印象深刻的理解和生成能力。这些模型在传统的多模态任务中取得了竞争性表现,如视觉识别[320]、视频理解[258, 289]、语音识别[200]和3D理解[89, 100]。此外,它们卓越的语言理解能力使其在文本丰富的任务中表现出色,如问答[104]、多轮对话和逻辑推理[156, 296]。
大多数现有的MLLMs主要关注修改模型架构以探索多模态信息的使用[121, 178, 246, 286, 287, 304]。尽管模型的有效性至关重要,数据也显著影响了MLLMs的成功。例如,Hoffmann等人[99]展示了为了扩展模型,有必要增加训练数据的规模。除了数据数量外,数据质量同样重要。先前的研究[251]表明,精心策划的数据集可以使较小的模型达到与较大模型相当的性能。然而,关于MLLMs数据策划和利用的综合研究仍然缺乏。因此,本研究旨在从数据中心视角提供对MLLMs的全面理解。
与优先考虑架构增强而依赖固定数据集的模型中心方法相比,数据中心视角强调对数据集的迭代改进以提高性能。在数据中心MLLMs的范围内,我们关注利用数据模态的异质性、增强数据结构、增加数据数量和提高数据质量以改进MLLMs [316]。我们的讨论从不同阶段的MLLMs数据中心视角回答了三个关键问题:
-
Q1:如何收集、选择和管理MLLMs的数据?大量的数据需求和多模态数据的异质性在收集、选择和有效管理模型训练数据方面带来了挑战。MLLMs的不同训练阶段也导致了不同的数据类型需求。
-
Q2:数据如何影响MLLMs的性能?理解数据特性与MLLMs性能之间的关系对于优化数据集和增强模型能力至关重要。
-
Q3:如何评估MLLMs的数据?有必要开发全面的评估基准,以评估MLLMs在各种任务中的性能和鲁棒性。 本综述与现有综述的区别。在模型中心视角下,已有若干综述聚焦于LLMs [93, 203, 324]和MLLMs [280, 318],但缺乏对数据中心方面的深入分析。最近,一些综述开始关注LLMs的数据准备,如数据管理方法[274]、数据选择方法[5]和LLM数据集的综合综述[174]。然而,这些综述主要集中于仅文本LLMs的数据管理和选择方法,没有对MLLMs的数据处理管道进行彻底分析。尽管Zhang等人[318]总结了MLLMs的数据集,但未能提供对这些数据集的全面分析。与我们最相关的工作是数据中心人工智能(DCAI)[109, 111, 220, 279, 316],它也关注AI研究的数据中心视角,但未具体分析LLMs和MLLMs。
随着MLLMs的快速增长以及数据在这个大型模型时代越来越重要的角色,我们认为提供一个全面的MLLMs数据中心方法综述是至关重要的。本综述旨在从数据中心视角全面回顾MLLMs的进展文献,并讨论该领域的开放问题或未来方向。
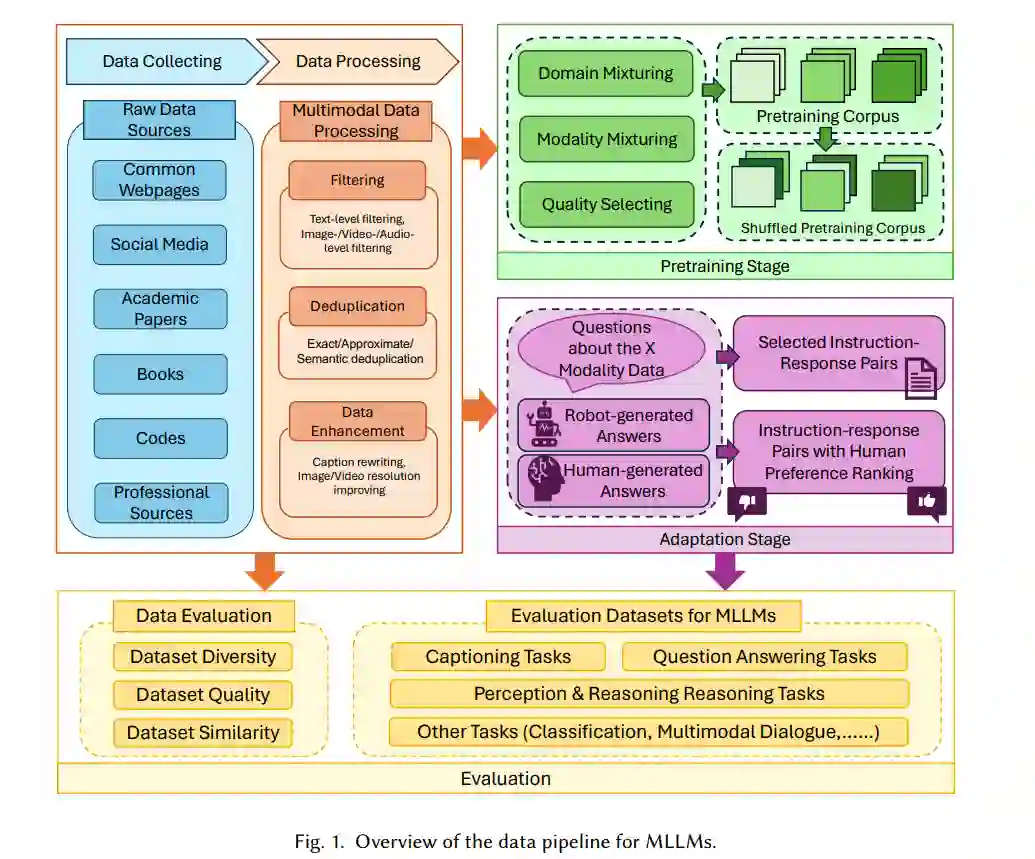
贡献。在这篇综述中,我们从数据中心视角回顾了MLLMs的进展文献。我们为研究人员和开发者提供了对MLLMs数据方面最新发展的总体和全面的理解。本综述的主要贡献总结如下:
- 新的数据中心视角。我们从数据中心视角提供了对MLLMs的全面综述,考虑了文本、图像、视频和音频等模态。
- 数据准备和管理管道。我们总结了在预训练和适应阶段MLLMs的数据准备和管理管道。
- 数据评估基准。我们概述了常用的从数据中心视角出发的评估基准。
- 开放问题和未来方向。我们讨论了当前数据中心LLMs研究中的开放问题,并提出了若干未来研究方向。
本文的其余部分安排如下:第2节介绍LLMs和MLLMs的预备知识,并讨论从数据中心视角分析它们的动机。第3至第5节总结了MLLMs训练数据的收集、处理和选择的主要阶段。第6节总结了MLLMs的评估方法和现有的评估数据集。第7节讨论了开放问题并强调了该领域的若干未来研究方向。最后,我们在第8节对本综述进行了总结。我们的Github仓库可以在https://github.com/beccabai/Data-centric_multimodal_LLM找到。