导语:本报告描述了2021财年美国陆军作战能力发展司令部(DEVCOM)陆军研究实验室(ARL)未来风险项目 "决策动力学、欺骗和博弈论"的研究工作。专知做了中文编译,欢迎关注,完整中英文版请上专知网站(www.zhuanzhi.ai)查看!
欢迎关注 专知【AI+军事】主题:
https://www.zhuanzhi.ai/topic/2001883600396423
![]()
以下为正文:
本报告描述了2021财年美国陆军作战能力发展司令部(DEVCOM)陆军研究实验室(ARL)未来风险项目 "决策动力学、欺骗和博弈论"的研究工作。为了提高指挥和控制多域作战的决策辅助工具的有效性,有必要开发能够协助复杂决策的人工智能(AI)工具。该项目开发了一个人工智能测试平台--ARL战斗空间(ARL Battlespace),用于创建和研究复杂推理的人工智能决策辅助工具。ARL Battlespace是一个由友好和敌对的人类和人工智能Agent组成的多人网络兵棋推演工具。分层贝叶斯模型的初步结果说明,在具有不确定性、欺骗和博弈论的情况下,具有复杂推理功能的人工智能多学科发展框架具有潜力。该项目还开始开发一个基于与战场可视化和交互平台以及高性能计算持久服务框架的潜在集成的人机协作决策框架。这些成果为改善人-人工智能团队的复杂决策和协作能力开启了研究的大门。
1. 简介
作为美国防部人工智能(AI)战略的一部分,美国陆军作战能力发展司令部(DEVCOM)陆军研究实验室(ARL)正在开发基于人类系统适应战略的研究项目和技术,包括开发基于人-AI团队决策和相互适应的超人能力的目标。这些新能力对于解决陆军的多域作战(MDO)战略是必要的,特别是其渗透和分解阶段,在此期间,人工智能辅助决策可以增强指挥官处理高速和大量信息以及地面、海上、空中、太空和网络领域的复杂动态的能力。一个关键的挑战是,现有的人工智能算法,对于复杂的决策来说是远远不够的,而且对MDO相关场景的概括能力有限。另一个挑战是,现有的陆军理论和决策支持程序没有将人工智能纳入军事决策过程(MDMP),而陆军的自动规划框架(APF)刚刚开始解决这一差距。此外,现有的人-人工智能编队决策理论和技术仅限于简单的决策,为复杂的深度决策在提供人工智能透明度方面非常有限,在这种情况下,多种依赖性、不确定性以及信息领域和行为者与复杂的人类、物资和环境动态相交。它们与人类专家的隐性推理协同工作的能力也很有限。发展这些能力需要一个综合的、多学科的研究方法,包括为新的人工智能研究和人类与人工智能的编队协作开发人工智能试验基地。
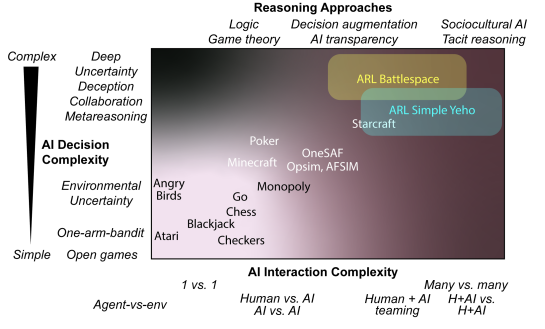
对于兵棋推演,有必要开发能够模拟包括战术和战略层面在内的多个梯队的决策测试平台。现有的兵棋推演决策工具,如Opsim、AFSIM和OneSAF,可以在多个规模上对许多因素进行建模和模拟,以预测基于战略、物资能力和资源的结果,但它们受到老化系统的限制,有经验的士兵可能难以学习,也不太适合开发人工智能和人类+人工智能编队协作的能力。最近,人工智能能力的快速上升为开发和纳入新型人工智能作为兵棋推演的决策辅助工具打开了研究的大门。最近人工智能推理的改进(例如,基于深度强化学习)是基于环境状态完全已知的“开放”游戏(例如,跳棋、国际象棋和围棋),它们是基于有限的合作性或欺骗性。即使在有额外复杂性的情况下,如环境的不确定性(愤怒的小鸟、雅达利),决策的复杂性、灵活性和对多人兵棋推演的可转移性也是有限的(如扑克、Minecraft、星际争霸[图1])。尽管这些模型可以深入探索决策,但它们只限于选择结果的潜在价值可以很容易测量和量化的条件。兵棋推演环境给人工智能学习带来了困难和未解决的挑战,因为有许多信息不确定性的来源,不仅来自环境,也来自人类和人工智能Agent。人工智能需要适应不断变化的规则和战略,迅速减轻出乎意料的敌方能力,并利用新的机会和友好的能力。人工智能还需要与他们的人类队友相互适应,他们需要有默契的推理能力来与人类专家协同工作,并补偿个人的偏见和启发式方法以及变化的认知状态。与博弈论等经典方法不同的是,未来状态的预期效用可以根据合作或不合作的选择对有限的行动集进行明确的量化,兵棋推演提出了跨环境和社会动态(包括合作性和欺骗性)以及跨多个时空尺度和领域的相互作用的可能性,这使人工智能学习决策如何与未来状态价值相联系的能力受到影响。
图1 ARL在更广泛的人工智能研究战略中的Battlespace平台
解决这一差距需要持续的基础研究工作,实验的重点是为决策中的具体问题发现原则和开发新的算法,并有能力将这些原则和算法与MDO的兵棋推演联系起来。例如,在具有不完善的知识和不确定性的复杂情况下,提供接近最佳解决方案的人工智能可能比提供单一的"最佳"解决方案更有帮助。这种解决问题的方式与人工智能的透明度也需要探讨。对近乎最优和不确定性等条件进行实验,并采用新的作战人员机器界面(WMIs),可以产生新的算法、通用工具和原则,更好地协同人类和人工智能对复杂决策的探索。
1.1 军队的相关性和问题领域
陆军战略科技(S&T)计划的一部分是为 "超人类"的决策和行动开发能力。对于科技计划中的"人-系统适应"部分,预期的结果是将人类特有的能力和机器的新兴能力结合起来,最大限度地提高速度和选择,以有效应对2035年及以后的社会技术环境的复杂性、智能化和动态性。预计这些研究工作将为人类引导的机器适应、训练精通技术的士兵、混合人机思维、以及下一代人类系统集成和系统级分析创造新的能力。由于战争正在快速变化,包括不断的技术变化,实现这样的能力需要制定一个研究计划,以推进人工智能、人类与人工智能的合作,专门用于复杂的决策。
作为DEVCOM陆军研究实验室未来风险投资(DFV)计划的一部分,这个项目的目标是开发一个跨学科的计划,以解决人工智能决策的复杂性和人类-人工智能团队决策中的差距。这包括开发一个人工智能研究测试平台--ARL战斗空间,将复杂的兵棋推演决策抽象为关键要素,以便人工智能和人类-人工智能团队的发展可以专门关注复杂的决策过程本身,同时避免物理现实主义和当今材料和理论的计算和概念限制。这也包括为如何发展人类-人工智能协作决策创造新的概念,了解如何塑造信息流以实现人类-人工智能决策的相互透明,以及在人类和人工智能都难以筛选出不确定性和欺骗的条件下实现相互适应性学习。显性和隐性的决策框架都需要通过这个抽象的兵棋推演测试平台来实现,以便人工智能可以在多个推理层次上学习和接受挑战。还需要一个适当的抽象水平,以使多种类型的研究,包括神经科学、人工智能和决策理论交叉的学术研究,以提高人工智能决策的能力和复杂性,并改善其在军事方面的转化。
1.2 长期目标
根据设想,在2035年及以后的陆军中,指挥与控制(C2)决策将由决策辅助系统来激活,该系统利用分布在多个梯队的人工智能能力,并以复杂和快速的方式摄取所有领域的数据,这将使没有辅助的士兵感到不知所措。启用人工智能的决策辅助工具将能够对战斗空间进行前沿模拟和分布式训练;在MDO的渗透和解除整合阶段,能够对条件、友军和敌军战略以及能力变化的可能影响进行调整和前瞻预测;并能够对关键决策进行事后审查。人工智能将为其决策提供透明度,使真实和抽象的决策空间互动可视化,并根据陆军理论和未来理论的要求,对士兵的个体化和情境进行优化。相反,人工智能将与士兵共同适应,学习如何在信息不足、冲突或欺骗的情况下做出复杂的决定,并为有效的团队决策重新塑造、完善和展示信息。有了人工智能Agent作为数据有效转化和行动化以及利用显性和隐性知识的合作伙伴,预计分布式C2指挥官将能够在MDO的许多时空尺度和维度上共同制定和协调行动方案,并且战术和战略的跨领域互动将被向前模拟,对环境、人和战略的动态有更强的弹性。除了增加复杂决策的能力外,预计决策过程本身将通过消除繁琐的计算和其他延迟而加速,从而使计划和战略能够比实时更快适应不断变化的战场和外部(如外交、经济)因素。
为了实现这一未来,为复杂决策开发新型人工智能的计划的长期目标是利用多个学科的持续进步。用于推理的"核心人工智能"的发展,在为简单决策迅速取得进展的同时,需要持续的协同创新,以及来自神经科学和心理学等领域的研究,以便在奖励难以分配给具体事件或行动的条件下(例如,因为不清楚以何种程度的确定性将奖励的原因归于谁、什么、何时、何地或为何),为强化学习开发新型理论。需要机械层面的理论(例如,神经胶质网络如何支持将不同的事件与奖励联系起来)和更高层次的理论(例如,社会规则如何塑造学习)来弥补目前核心人工智能的有限能力和C2决策的需求之间的差距。还需要协同创新和研究,将人工智能的发展与士兵的隐性推理过程相结合,以实现元学习和元推理的决策互动。
1.3 DFV项目的目标
ARL DFV项目是一种机制,旨在促进跨学科基础和应用研究的新方向,解决研究差距,并为军队的任务创造新的能力。DEVCOM ARL研究员认为分析科学是一个需要能力的领域,具有高回报的潜力,需要对现有项目进行重新规划和扩展,并需要新的项目来建立新的核心能力和建立内部的专业知识。
为了创造这些能力,这个DFV项目的主要目标是建立一个新的研究项目,为C2决策辅助工具的复杂推理开发新型人工智能。这包括开发一个人工智能测试平台:ARL Battlespace,以便灵活地开发专门用于MDO C2决策的复杂推理的新型人工智能。现有的兵棋推演人工智能测试平台往往局限于较简单的决策,更注重于战术性的地面行动。例如,正在进行的人工智能测试平台开发工作,如ARL Simple Yeho人工智能测试平台,侧重于环境的真实性,有多个地图层,包括道路、树叶和海拔高度,向排长推荐决策,如路线规划和士兵重新分配任务。由于对当地地形环境的关注,在该环境中开发的人工智能推理将集中在精细的社会和生态动态上,对协作和敌对决策动态进行深入训练的机会比较稀少。这些稀少和复杂的问题("微小的、肮脏的、动态的和欺骗性的数据")迷惑了发展人工智能的经典方法,尤其是复杂推理。相反,这个DFV项目的ARL战斗空间人工智能测试平台抽象了当地地形的元素,将人工智能的学习和推理更具体地集中在复杂的MDO相关的C2深度推理上(多个决策步骤,包括更频繁的合作和欺骗的机会)。这使得在C2兵棋推演的背景下,更有针对性地发展人工智能对复杂的多Agent(人、人工智能和人+人工智能团队)的决策能力。
第二个目标是通过开发一个有效的WMI来研究和开发如何呈现人工智能的理解和预测以及如何利用人类的理解和预测,为复杂决策的有效人类-人工智能团队合作创造条件。这项工作包括利用和开发高性能计算(HPC)资源进行计算支持,同时开发用于决策的商业二维交互和混合现实交互的定制软件(例如,基于增强现实沙盘[ARES]平台的战斗空间可视化和互动(BVI)平台)。通过开发多种WMI方法,我们期望这些平台能够实现复杂决策的快速原型研究,并能够将我们的新型AI与更成熟的兵棋推演训练和模拟框架与团队进行整合。
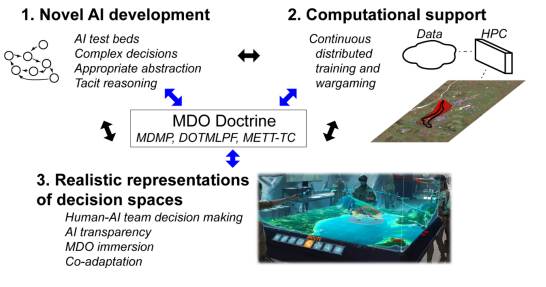
我们预计,在新型人工智能开发、HPC计算支持和用于决策空间现实表现的WMI开发方面的这些努力将为人类-人工智能团队的发展创造一个新的范例,为未来多个陆军理论(MDMP、DOTMLPF、27 METT-TC28)的进步和现代化铺平道路(图2)。
图2 在更广泛的人类-Agent团队决策研究战略中的新型人工智能开发
这个项目开发了两个研究框架 。首先,它开发了一个人工智能测试平台,被称为ARL战斗空间,用于创建和调查人工智能的复杂协作和敌对决策。其次,它认识到目前军事决策过程中的局限性,构思了一个用于人与人工智能协作的复杂决策的WMI,利用军队和商业开发的战斗空间可视化平台,与非传统的HPC资源进行潜在的连接,实现人工智能增强的兵棋推演平台。
https://www.zhuanzhi.ai/vip/8842a84e7adfe90340d8b655b489ba67
专知便捷查看
便捷下载,请关注专知人工智能公众号(点击上方蓝色专知关注)
专知,专业可信的人工智能知识分发
,让认知协作更快更好!欢迎注册登录专知www.zhuanzhi.ai,获取100000+AI(AI与军事、医药、公安等)主题干货知识资料!
欢迎微信扫一扫加入专知人工智能知识星球群,获取最新AI专业干货知识教程资料和与专家交流咨询!
点击“
阅读原文
”,了解使用
专知
,查看获取100000+AI主题知识资料