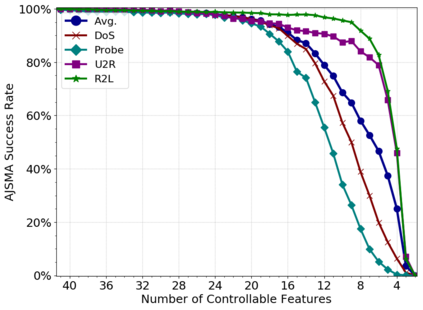
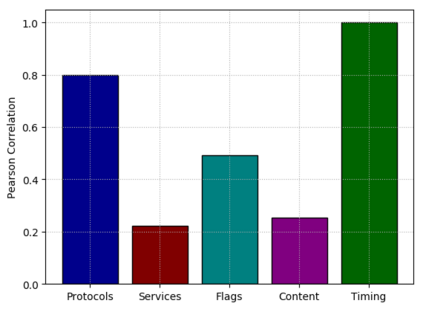
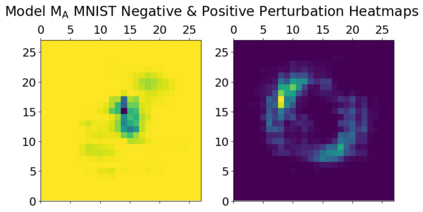
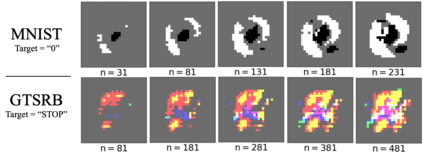
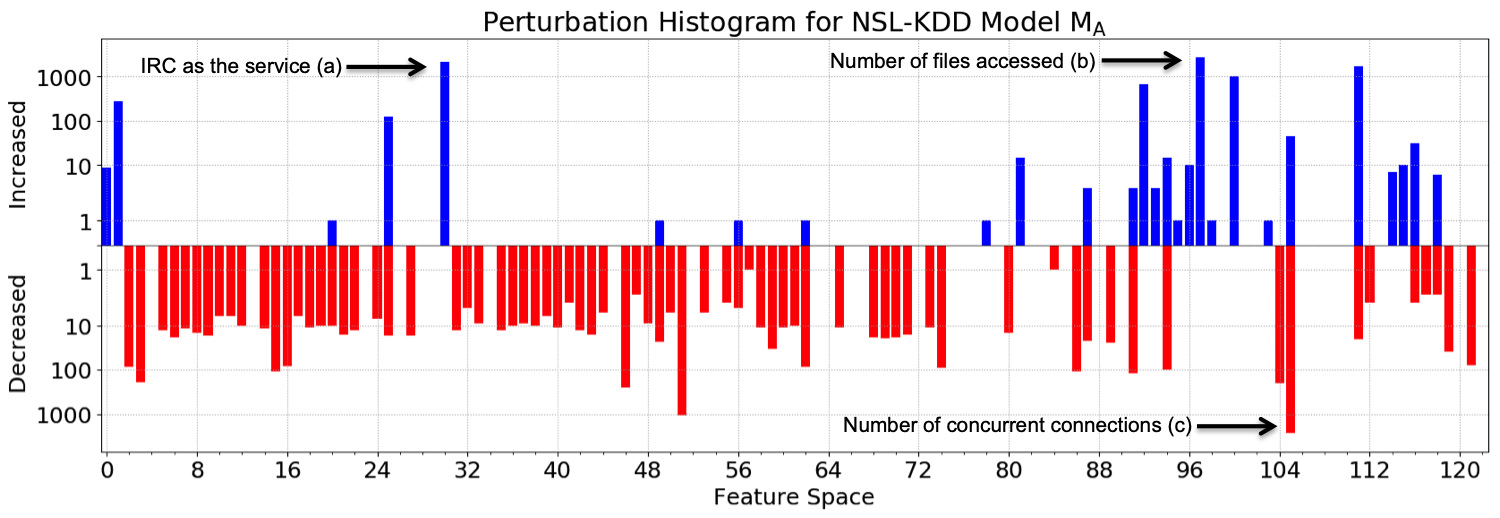
Machine learning algorithms have been shown to be vulnerable to adversarial manipulation through systematic modification of inputs (e.g., adversarial examples) in domains such as image recognition. Under the default threat model, the adversary exploits the unconstrained nature of images; each feature (pixel) is fully under control of the adversary. However, it is not clear how these attacks translate to constrained domains that limit which and how features can be modified by the adversary (e.g., network intrusion detection). In this paper, we explore whether constrained domains are less vulnerable than unconstrained domains to adversarial example generation algorithms. We create an algorithm for generating adversarial sketches: targeted universal perturbation vectors which encode feature saliency within the envelope of domain constraints. To assess how these algorithms perform, we evaluate them in constrained (e.g., network intrusion detection) and unconstrained (e.g., image recognition) domains. The results demonstrate that our approaches generate misclassification rates in constrained domains that were comparable to those of unconstrained domains (greater than 95%). Our investigation shows that the narrow attack surface exposed by constrained domains is still sufficiently large to craft successful adversarial examples; and thus, constraints do not appear to make a domain robust. Indeed, with as little as five randomly selected features, one can still generate adversarial examples.
翻译:事实证明,通过系统地修改图像识别等领域的投入(例如对抗性生成法),机器学习算法很容易受到对抗性操纵。在默认威胁模式下,对手利用图像不受限制的性质;每个特性(像素)完全在对手的控制之下。然而,尚不清楚这些攻击如何转化成限制领域,限制和如何由对手改变特征(例如,网络入侵探测)的制约领域。在本文中,我们探讨受限制的领域是否比不受限制的领域更容易受到对抗性模拟生成法的制约。我们为生成对抗性生成法创建了一种算法:定向的通用扰动矢量,在域内限制范围内标出显著特征。要评估这些算法如何运行,我们就在受限制(例如,网络入侵探测)和不受约束(例如,图像识别)的领域进行评估。结果显示,我们的方法在受限制的领域产生的分类率与未受限制的领域相似(大于95 % ) 。我们的调查显示,受限制的领域所暴露的狭窄的进攻面面并不具有明显的特征。因此,一个被限制的域域域内具有非常强大的特征,因此,具有非常强大的域域域内具有非常强大的特征。