NIPS 2017论文解读 | 基于对比学习的Image Captioning

在碎片化阅读充斥眼球的时代,越来越少的人会去关注每篇论文背后的探索和思考。
在这个栏目里,你会快速 get 每篇精选论文的亮点和痛点,时刻紧跟 AI 前沿成果。
点击本文底部的「阅读原文」即刻加入社区,查看更多最新论文推荐。
本期推荐的论文笔记来自 PaperWeekly 社区用户 @jamiechoi。本文提出了一种将对比学习(CL)用于 Image Captioning 的方法,通过在参考模型上设立两个约束,鼓励独特性,从而提高标记质量。
如果你对本文工作感兴趣,点击底部的阅读原文即可查看原论文。
关于作者:蔡文杰,华南理工大学硕士生,研究方向为Image Caption。
■ 论文 | Contrastive Learning for Image Captioning
■ 链接 | https://www.paperweekly.site/papers/1344
■ 源码 | https://github.com/doubledaibo/clcaption_nips2017
论文动机
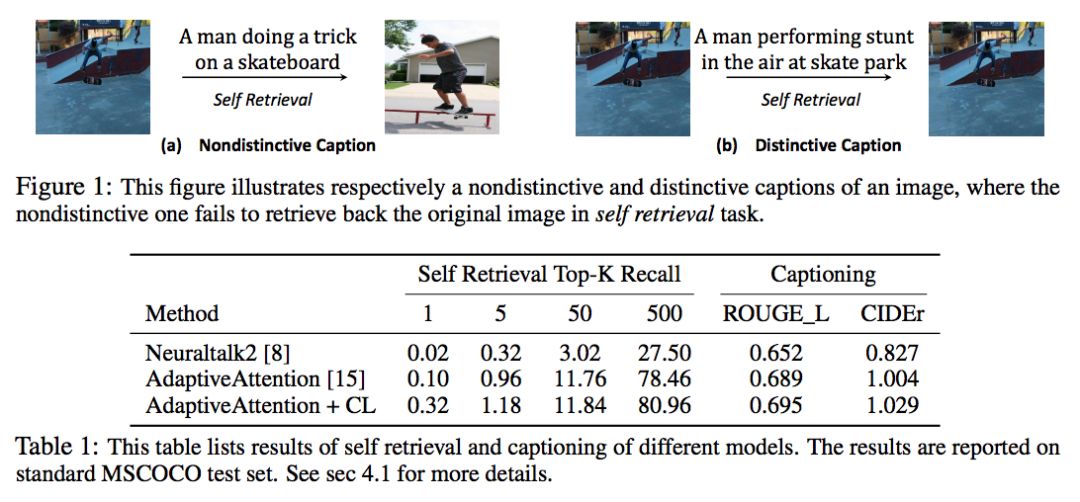
本文提出的 Contrastive Learning (CL) 主要是为了解决 Image Caption 任务中生成的 Caption 缺少 Distinctiveness 的问题。
这里的 Distinctiveness 可以理解为独特性,指的是对于不同的图片,其 caption 也应该是独特的、易于区分的。即在所有图片中,这个 caption 与这幅图片的匹配度是最高的。
然而现在大多数的模型生成的 caption 都非常死板,尤其是对于那些属于同一类的图片,所生成的 caption 都非常相似,而且 caption 并没有描述出这些图片在其他方面的差异。
Empirical Study
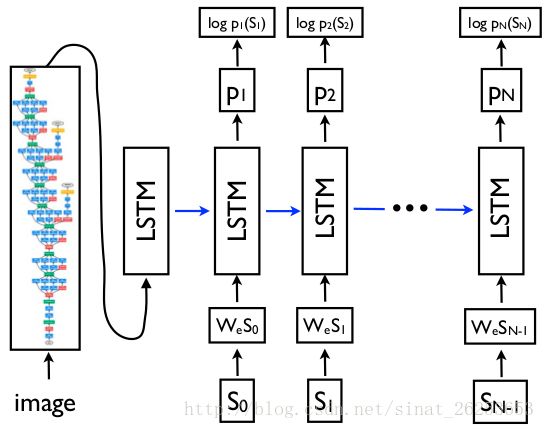
文章提出了一个 self-retrieval study,来展示缺少 Distinctiveness 的问题。作者从 MSCOCO test set 上随机选取了 5000 张图片 I1,...I5000,并且用训练好的 Neuraltalk2 和 AdaptiveAttention 分别对这些图片生成对应的 5000 个 caption c1,...,c5000。
用 pm(:,θ) 表示模型,对于每个 caption ct,计算其对于所有图片的条件概率 pm(ct|I1),...,pm(ct|I5000),然后对这些概率做一个排序,看这个 caption 对应的原图片是否在这些排序后的结果的 top-k 个里,具体可见下图。
可见加入了 CL 来训练以后,模型的查找准确率明显提高了,并且 ROUGE_L 以及 CIDEr 的分数也提高了,准确度与这两个评价标准的分数呈正相关关系。这说明提高 Distinctiveness 是可以提高模型的 performance 的。
Contrastive Learning
先介绍通常使用 Maximum Likelihood Estimation (MLE) 训练的方式,这里借用 show and tell 论文里面的图:
输入一副图片以后,我们会逐个地得到下一个目标单词的概率 pt(St),我们需要最大化这个概率,而训练目标则通过最小化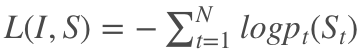
而使用 MLE 训练会导致缺少 Distinctiveness 的问题,作者在他之前的文章 Towards Diverse and Natural Image Descriptions via a Conditional GAN 里面已经解释过了,大家可以读一读。
CL 的中心思想是以一个参考模型 (reference model,如 state-of-the-art 的模型,本文以 Neuraltalk2 和 AdaptiveAttention 为例) 作为 baseline,在此基础上提高 Distinctiveness,同时又能保留其生成 caption 的质量。参考模型在训练过程中是固定的。
CL 同时还需要正样本和负样本作为输入,正负样本都是图片与 ground-truth caption 的 pair,只不过正样本的 caption 与图片是匹配的;而负样本虽然图片与正样本相同,但 caption 却是描述其他图片的。
具体符号:
目标模型 target model:pm(:,θ)
参考模型 reference model:pn(:,ϕ)
正样本 ground-truth pairs: X=((c1,I1),...,(cTm,ITm))
负样本 mismatched pairs: Y=((c/1,I1),...,(c/Tn,ITn))
目标模型和参考模型都对所有样本给出其估计的条件概率 pm(c|I,θ) 和 pn(c|I,θ),这里的 pm(c|I,θ) 应该是输入图片后,依次输入 caption 中的单词S0,...,SN−1,并且依次把得到的下一个目标单词概率 p1(S1),...,pN(SN) 相乘所得到的。结合上图看会更清晰。
并且希望对于所有正样本来说,pm(c|I,θ) 大于 pn(c|I,θ);对于所有负样本,pm(c|I,θ) 小于 pn(c|I,θ)。意思就是目标模型对于正样本要给出比参考模型更高的条件概率,对于负样本要给出比参考模型更低的条件概率。
定义 pm(c|I,θ) 和 pn(c|I,θ) 的差为 D((c,I);θ,ϕ)=pm(c|I,θ)−pn(c|I,θ),而 loss function 为:
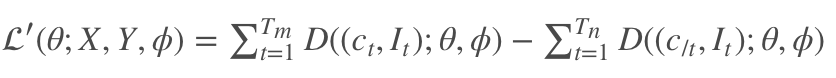
这里应该是最大化 loss 进行求解。
然而实际上这里会遇到几个问题:
首先 pm(c|I,θ) 和 pn(c|I,θ) 都非常小(~ 1e-8),可能会产生 numerical problem。因此分别对 pm(c|I,θ) 和 pn(c|I,θ) 取对数,用 G((c,I);θ,ϕ)=lnpm(c|I,θ)−lnpn(c|I,θ) 来取代 D((c,I);θ,ϕ)。
其次,由于负样本是随机采样的,不同的正负样本所产生的 D((c,I);θ,ϕ) 大小也不一样,有些 D 可能远远大于 0,有些 D 则比较小。
而在最大化 loss 的过程中更新较小的 D 则更加有效,因此作者使用了一个 logistic function (其实就是 sigmoid)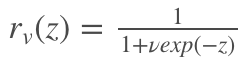
因此,D((c,I);θ,ϕ) 又变成了:h((c,I);θ,ϕ)=rν(G((c,I);θ,ϕ)))。
由于 h((c,I);θ,ϕ)∈(0,1),于是 loss function 变成了:
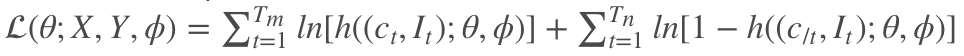
等式的第一项保证了 ground-truth pairs 的概率,第二项抑制了 mismatched pairs 的概率,强制模型学习出 Distinctiveness。
另外,本文把 X 复制了 K 次,来对应 K 个不同的负样本 Y,这样可以防止过拟合,文中选择 K=5。
最终的 loss function:
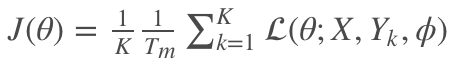
以上的这些变换的主要受 Noise Contrastive Estimation (NCE) 的启发。
理想情况下,当正负样本能够被完美分辨时,J(θ)的上界是 0。即目标模型会对正样本 p(ct|It) 给出高概率,负样本 p(c/t|It) 给出低概率。
此时:
G((ct,It);θ,ϕ)=→∞,G((c/t,It);θ,ϕ)→−∞, h((ct,It);θ,ϕ)=1,h((c/t,It);θ,ϕ)=0, J(θ) 取得上界 0。
但实际上,当目标模型对正样本给出最高概率 1 时,我认为 G((ct,It);θ,ϕ) 应该等于 lnpn(c|I,θ),因此 h((ct,It);θ,ϕ)<1,J(θ) 的上界应该是小于 0 的。
实验结果
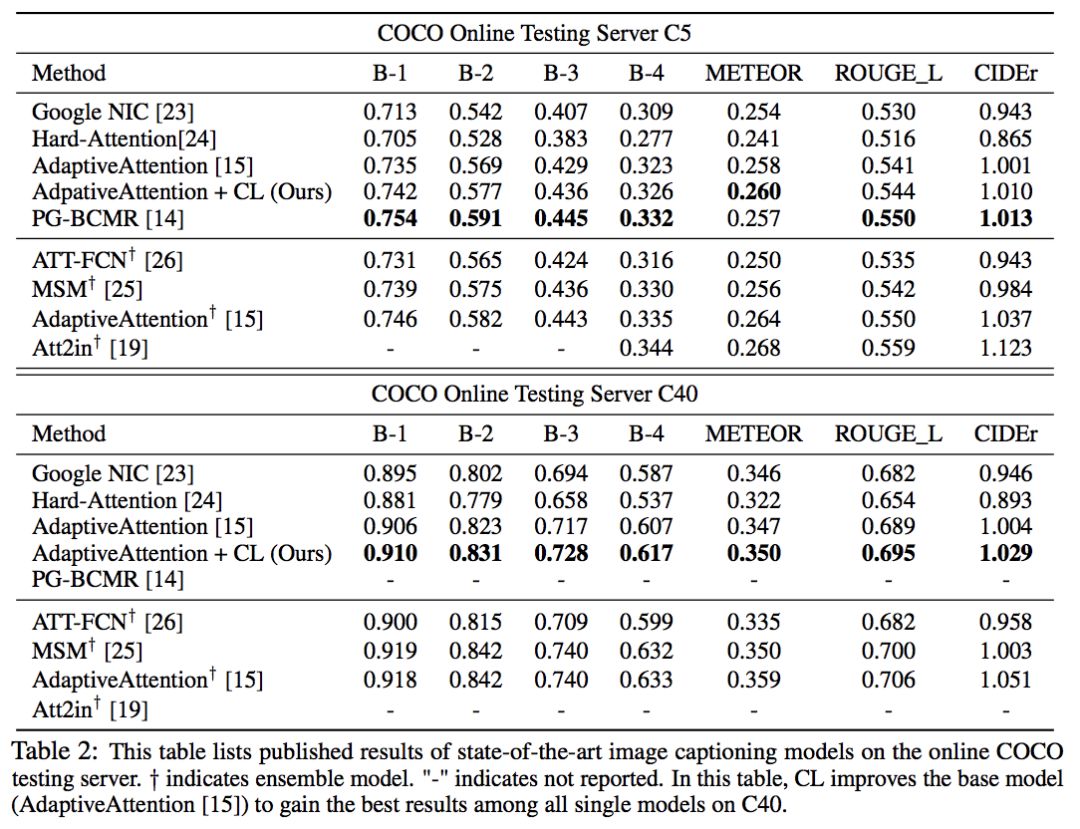
如上图,可以看到,加入 CL 以后,模型的表现有较大提升。
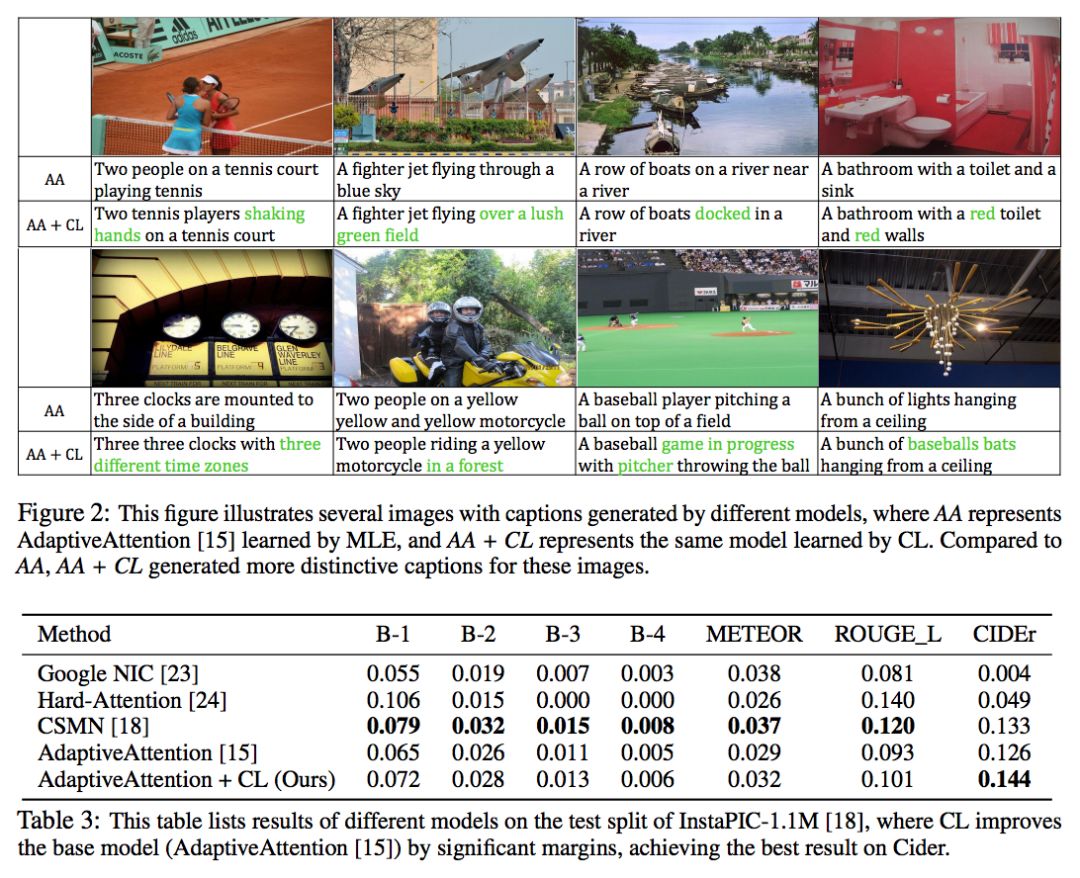
上图为 CL 与原模型的一些可视化结果。
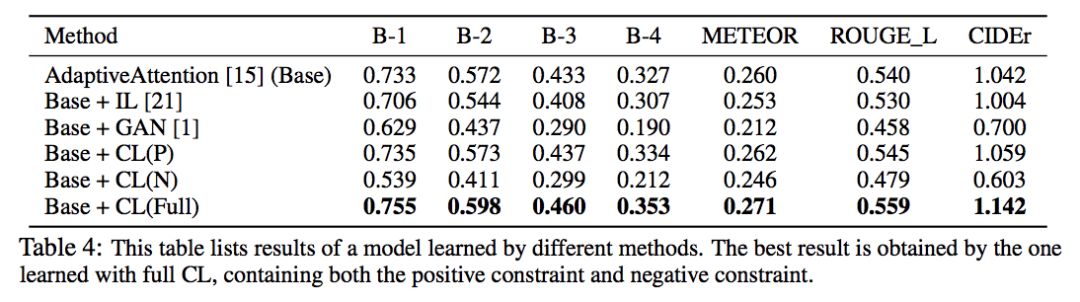
文章还对比了 CL 跟 GAN、IL (Introspective Learning) 之间的区别:
IL 把 target model 自身作为 reference,并且是通过比较 (I,c),(I/,c) 来进行学习的。 IL 的负样本 (I/,c) 通常是预定义且固定的,而 CL 的负样本则是动态采样的。
GAN 中的 evaluator 直接测量 Distinctiveness,而不能保证其准确性。
另外,加入 IL 和 GAN 后模型的准确性都有所下降,说明模型为了提高 Distinctiveness 而牺牲了准确性。但 CL 在保持准确性的同时又能提高 Distinctiveness。
上图还对比了分别只有正负样本的训练情况,可以看到:
只有正样本的情况下模型的表现只稍微提升了一些。我认为,这是因为参考模型给出的概率是恒定的,去掉负样本以后的损失函数就相当于 MLE 的损失函数再减去一个常数,与 MLE 是等价的,因此相当于在原来的模型的基础上多进行了一些训练。
只有负样本的情况下模型的表现是大幅下降的(因为没有指定正样本,且负样本是随机抽取的)。
而只有两个样本都参与训练的时候能给模型带来很大的提升。
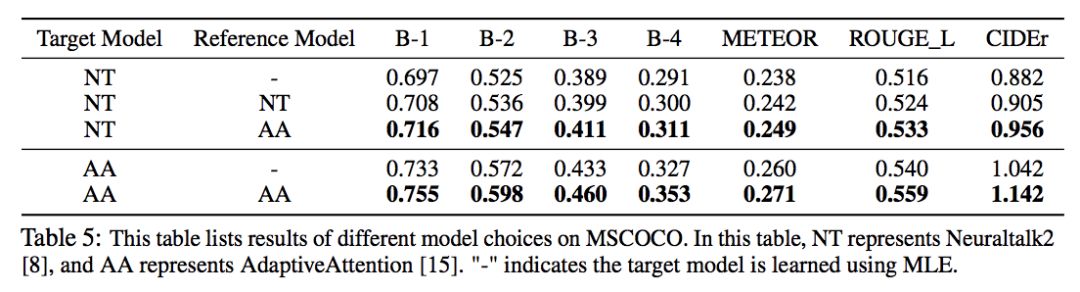
上图测试了 CL 的泛化能力,可以看到,通过选择更好的模型(AA)作为 reference,NT 的提升更大。(但是却没有超过 AA 本身,按理说不是应该比 reference 模型更好吗?)
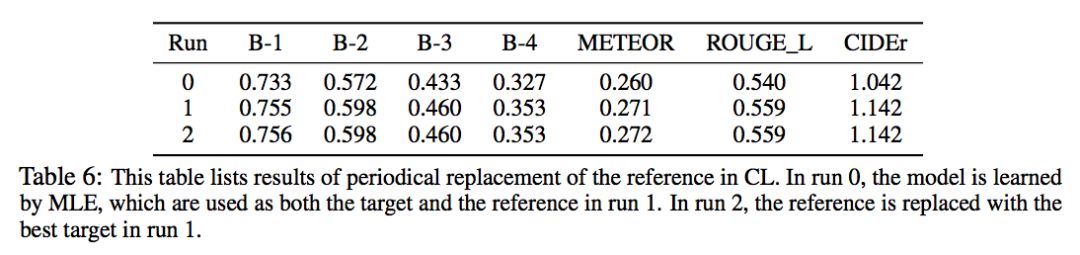
另外,还可以通过周期性地以训练好的目标模型作为更好的参考模型,来提升模型的下界。然而在 Run 2 进行第二次替换的时候提升已经不大,证明没有必要多次替换。
总结
总的来说,本文主要的贡献在于提出了 Contrastive Learning 的方法,构造损失函数利用了负样本来参与训练,提高模型的 Distinctiveness。另外本文提出的 self-retrieval 实验思路在同类论文里也是挺特别的。
本文由 AI 学术社区 PaperWeekly 精选推荐,社区目前已覆盖自然语言处理、计算机视觉、人工智能、机器学习、数据挖掘和信息检索等研究方向,点击「阅读原文」即刻加入社区!


2017年度最值得读的AI论文 | NLP篇 · 评选结果公布
2017年度最值得读的AI论文 | CV篇 · 评选结果公布
我是彩蛋
解锁新功能:热门职位推荐!
PaperWeekly小程序升级啦
今日arXiv√猜你喜欢√热门职位√
找全职找实习都不是问题
解锁方式
1. 识别下方二维码打开小程序
2. 用PaperWeekly社区账号进行登陆
3. 登陆后即可解锁所有功能
职位发布
请添加小助手微信(pwbot01)进行咨询
长按识别二维码,使用小程序
*点击阅读原文即可注册

关于PaperWeekly
PaperWeekly 是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事 AI 领域,欢迎在公众号后台点击「交流群」,小助手将把你带入 PaperWeekly 的交流群里。

▽ 点击 | 阅读原文 | 查看论文 & 源代码


