
人类可以自然有效地在复杂的场景中找到显著区域。在这种观察的推动下,注意力机制被引入到计算机视觉中,目的是模仿人类视觉系统的这方面。这种注意力机制可以看作是一个基于输入图像特征的动态权值调整过程。注意力机制在图像分类、目标检测、语义分割、视频理解、图像生成、三维视觉、多模态任务和自监督学习等视觉任务中取得了巨大的成功。本文综述了计算机视觉中的各种注意力机制,并对其进行了分类,如通道注意力、空间注意力、时间注意力和分支注意力; 相关的存储库https://github.com/MenghaoGuo/Awesome-Vision-Attentions专门用于收集相关的工作。本文还提出了注意机力制研究的未来方向。
https://www.zhuanzhi.ai/paper/2329d809f32ca0840bd93429d1cef0fe
引言
将注意力转移到图像中最重要的区域而忽略不相关部分的方法称为注意力机制; 人类视觉系统使用一个[1],[2],[3],[4]来帮助高效和有效地分析和理解复杂的场景。这反过来也启发了研究人员将注意力机制引入计算机视觉系统,以提高它们的表现。在视觉系统中,注意力机制可以看作是一个动态选择过程,根据输入的重要性自适应加权特征来实现。注意力机制在许多视觉任务中提供了好处,例如:图像分类[5],[6],目标检测[7],[8],语义分割[9],[10],人脸识别[11],[12],人再识别[13],[14],动作识别[15],[16],少样本学习[17],[18],医学图像处理[19],[20],图像生成[21],[22],姿态估计[23],超分辨率[24],[25],3D视觉[26],[27],多模态任务[28],[29]。
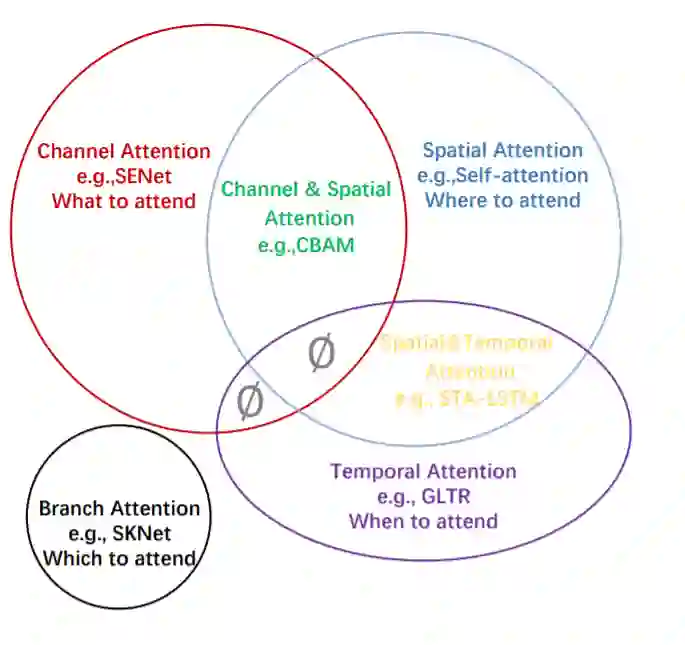
图1 注意力机制可以根据数据域进行分类。其中包括通道注意力、空间注意力、时间注意力和分支注意力四大类基本注意力,以及通道&空间注意力和空间&时间注意力相结合的两大类混合注意力。∅表示此组合不存在。
在过去的十年中,注意机制在计算机视觉中发挥着越来越重要的作用; 图3,简要总结了深度学习时代计算机视觉中基于注意的模型的历史。进展大致可分为四个阶段。第一阶段从RAM[31]开始,这是一项将深度神经网络与注意力机制结合起来的开创性工作。它通过策略梯度对重要区域进行循环预测,并对整个网络进行端到端更新。后来,各种工作[21],[35]采用了类似的视觉注意力策略。在这个阶段,循环神经网络(RNNs)是注意机制的必要工具。在第二阶段的开始,Jaderberg等人[32]提出判别歧视性输入特征是第二阶段的主要特征; DCNs[7]、[36]是代表性工作。第三阶段以SENet[5]开始,该网络提出了一种新的管道段的代表作。最后一个阶段是自注意力时代。自注意力最早在[33]中提出,并迅速在自然语言处理领域取得了巨大进展。Wang et al.[15]率先将自注意力引入计算机视觉,提出了一种新型的非局部网络,在视频理解和目标检测方面取得了巨大成功。随后进行了EMANet[40]、CCNet[41]、HamNet[42]和单机网络[43]等一系列工作,提高了速度、结果质量和泛化能力。近年来,各种纯深度自注意力网络(视觉变换器)很明显,基于注意力的模型有潜力取代卷积神经网络,成为计算机视觉中更强大、更通用的架构。
本文的目的是对当前计算机视觉中的注意力方法进行总结和分类。我们的方法如图1所示,并在图2中进一步解释 :它是基于数据域的。有些方法考虑重要数据何时出现的问题,或者它在哪里出现的问题,等等,并相应地尝试查找数据中的关键时间或位置。我们将现有的注意力方法分为六类,其中包括四种基本类别:通道注意力(注意力什么[50])、空间注意力(注意什么地方)、时间注意力(注意力什么时间)和分支通道(注意力什么地方),以及两种混合组合类别:通道&空间注意力和空间&时间注意力。这些观点和相关工作在表2中进行了进一步的简要总结。
-
对视觉注意力方法的系统综述,包括注意力机制的统一描述、视觉注意机制的发展以及当前的研究;
-
根据他们的数据域对注意力方法进行分类分组,使我们能够独立于特定的应用程序将视觉注意力方法联系起来
-
对未来视觉注意力研究的建议。



