自然语言处理中注意力机制综述
本文系作者乐雨泉 (yuquanle) 投稿,作者公众号:AI小白入门(id: StudyForAI),欢迎关注,点击文末"阅读原文"可直达原文链接,也欢迎大家投稿,AI、NLP相关即可。
目录
1.写在前面
2.Seq2Seq 模型
3.NLP中注意力机制起源
4.NLP中的注意力机制
5.Hierarchical Attention
6.Self-Attention
7.Memory-based Attention
8.Soft/Hard Attention
9.Global/Local Attention
10.评价指标
11.写在后面
12.参考文献
写在前面
近些年来,注意力机制一直频繁的出现在目之所及的文献或者博文中,可见在nlp中算得上是个相当流行的概念,事实也证明其在nlp领域散发出不小得作用。这几年的顶会paper就能看出这一点。本文深入浅出地介绍了近些年的自然语言中的注意力机制包括从起源、变体到评价指标方面。
据Lilian Weng博主[1]总结以及一些资料显示,Attention机制最早应该是在视觉图像领域提出来的,这方面的工作应该很多,历史也比较悠久。人类的视觉注意力虽然存在很多不同的模型,但它们都基本上归结为给予需要重点关注的目标区域(注意力焦点)更重要的注意力,同时给予周围的图像低的注意力,然后随着时间的推移调整焦点。
而直到Bahdanau等人[3]发表了论文《Neural Machine Translation by Jointly Learning to Align and Translate》,该论文使用类似attention的机制在机器翻译任务上将翻译和对齐同时进行,这个工作目前是最被认可为是第一个提出attention机制应用到NLP领域中的工作,值得一提的是,该论文2015年被ICLR录用,截至现在,谷歌引用量为5596,可见后续nlp在这一块的研究火爆程度。
注意力机制首先从人类直觉中得到,在nlp领域的机器翻译任务上首先取得不错的效果。简而言之,深度学习中的注意力可以广义地解释为重要性权重的向量:为了预测一个元素,例如句子中的单词,使用注意力向量来估计它与其他元素的相关程度有多强,并将其值的总和作为目标的近似值。既然注意力机制最早在nlp领域应用于机器翻译任务,那在这个之前又是怎么做的呢?
传统的基于短语的翻译系统通过将源句分成多个块然后逐个词地翻译它们来完成它们的任务,这导致了翻译输出的不流畅。不妨先来想想我们人类是如何翻译的?我们首先会阅读整个待翻译的句子,然后结合上下文理解其含义,最后产生翻译。
从某种程度上来说,神经机器翻译(NMT)的提出正是想去模仿这一过程。而在NMT的翻译模型中经典的做法是由编码器 - 解码器架构制定(encoder-decoder),用作encoder和decoder常用的是循环神经网络。这类模型大概过程是首先将源句子的输入序列送入到编码器中,提取最后隐藏状态的表示并用于解码器的输入,然后一个接一个地生成目标单词,这个过程广义上可以理解为不断地将前一个时刻 t-1 的输出作为后一个时刻 t 的输入,循环解码,直到输出停止符为止。
通过这种方式,NMT解决了传统的基于短语的方法中的局部翻译问题:它可以捕获语言中的长距离依赖性,并提供更流畅的翻译。
但是这样做也存在很多缺点,譬如,RNN是健忘的,这意味着前面的信息在经过多个时间步骤传播后会被逐渐消弱乃至消失。其次,在解码期间没有进行对齐操作,因此在解码每个元素的过程中,焦点分散在整个序列中。对于前面那个问题,LSTM、GRU在一定程度能够缓解。而后者正是Bahdanau等人重视的问题。
Seq2Seq模型
在介绍注意力模型之前,不得不先学习一波Encoder-Decoder框架,虽然说注意力模型可以看作一种通用的思想,本身并不依赖于特定框架(比如文章[15]:Learning Sentence Representation with Guidance of Human Attention),但是目前大多数注意力模型都伴随在Encoder-Decoder框架下。
Seq2seq模型最早由bengio等人[17]论文《Learning Phrase Representations using RNN Encoder–Decoder for Statistical Machine Translation》。随后Sutskever等人[16]在文章《Sequence to Sequence Learning with Neural Networks》中提出改进模型即为目前常说的Seq2Seq模型。
从广义上讲,它的目的是将输入序列(源序列)转换为新的输出序列(目标序列),这种方式不会受限于两个序列的长度,换句话说,两个序列的长度可以任意。以nlp领域来说,序列可以是句子、段落、篇章等,所以我们也可以把它看作处理由一个句子(段落或篇章)生成另外一个句子(段落或篇章)的通用处理模型。
对于句子对,我们期望输入句子Source,期待通过Encoder-Decoder框架来生成目标句子Target。Source和Target可以是同一种语言,也可以是两种不同的语言,若是不同语言,就可以处理翻译问题了。若是相同语言,输入序列Source长度为篇章,而目标序列Target为小段落则可以处理文本摘要问题 (目标序列Target为句子则可以处理标题生成问题)等等等。
seq2seq模型通常具有编码器 - 解码器架构:
编码器encoder: 编码器处理输入序列并将序列信息压缩成固定长度的上下文向量(语义编码/语义向量context)。期望这个向量能够比较好的表示输入序列的信息。
解码器decoder: 利用上下文向量初始化解码器以得到变换后的目标序列输出。早期工作仅使用编码器的最后状态作为解码器的输入。
编码器和解码器都是循环神经网络,比较常见的是使用LSTM或GRU。
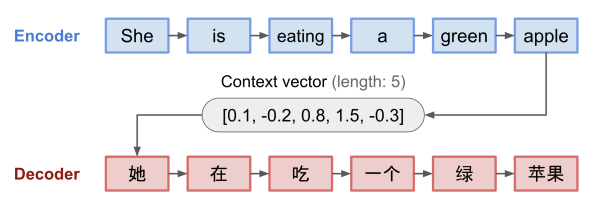
编码器 - 解码器模型
NLP中注意力机制的起源
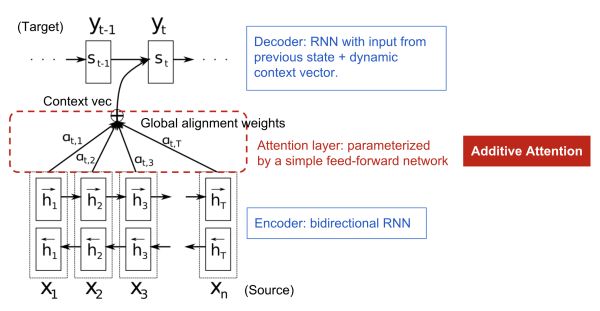
Bahdanau等人[3]把attention机制用到了神经网络机器翻译(NMT)上。传统的encoder-decoder模型通过encoder将Source序列编码到一个固定维度的中间语义向量context,然后再使用decoder进行解码翻译到目标语言序列。前面谈到了这种做法的局限性,而且,Bahdanau等人[3]在其文章的摘要中也说到这个context可能是提高这种基本编码器 - 解码器架构性能的瓶颈,那Bahdanau等人又是如何尝试缓解这个问题的呢? 别急,让我们来一探究竟。
作者为了缓解中间向量context很难将Source序列所有重要信息压缩进来的问题,特别是对于那些很长的句子。提出在机器翻译任务上在 encoder–decoder 做出了如下扩展:将翻译和对齐联合学习。这个操作在生成Target序列的每个词时,用到的中间语义向量context是Source序列通过encoder的隐藏层的加权和,而传统的做法是只用encoder最后一个时刻输出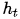
想想前面那个例子:Source: 机器学习-->Target: machine learning (假如中文按照字切分)。decoder在解码"machine"时,"机"和"器"提供的权重要更大一些,同样,在解码"learning"时,"学"和"习"提供的权重相应的会更大一些,这在直觉也和人类翻译也是一致的。
通过这种attention的设计,作者将Source序列的每个词(通过encoder的隐藏层输出)和Target序列 (当前要翻译的词) 的每个词巧妙的建立了联系。想一想,翻译每个词的时候,都有一个语义向量,而这个语义向量是Source序列每个词通过encoder之后的隐藏层的加权和。 由此可以得到一个Source序列和Target序列的对齐矩阵,通过可视化这个矩阵,可以看出在翻译一个词的时候,Source序列的每个词对当前要翻译词的重要性分布,这在直觉上也能给人一种可解释性的感觉。
论文中的图也能很好的看出这一点:
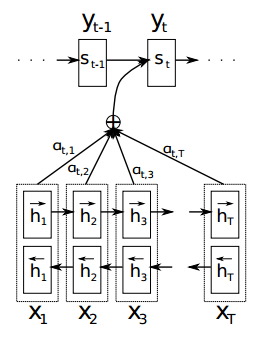
生成第t个目标词
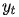
更形象一点可以看这个图:

现在让我们从公式层面来看看这个东东 (加粗变量表示它们是向量,这篇文章中的其他地方也一样)。 假设我们有一个长度为n的源序列x,并尝试输出长度为m的目标序列y:
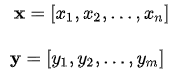
作者采样bidirectional RNN作为encoder(实际上这里可以有很多选择),具有前向隐藏状态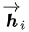
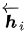
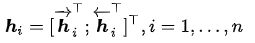
对于目标(输出)序列的每个词(假设位置为t),decoder网络的隐藏层状态:
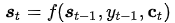
其中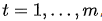
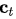
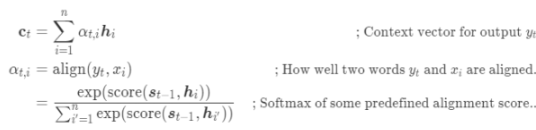
(注意:这里的score函数为原文的a函数,原文的描述为: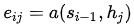
对齐模型基于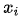
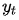
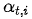
在Bahdanau[3]的论文中,作者采用的对齐模型为前馈神经网络,该网络与所提出的系统的所有其他组件共同训练。因此,score函数采用以下形式,tanh用作非线性激活函数,公式如下:
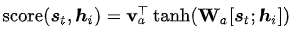
其中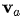
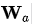
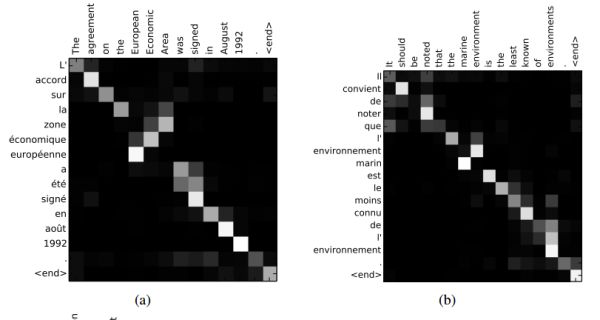
对齐矩阵例子
而decoder每个词的条件概率为:
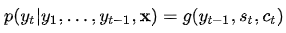
g为非线性的,可能是多层的输出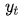
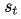
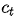
NLP中的注意力机制
随着注意力机制的广泛应用,在某种程度上缓解了源序列和目标序列由于距离限制而难以建模依赖关系的问题。现在已经涌现出了一大批基于基本形式的注意力的不同变体来处理更复杂的任务。让我们一起来看看其在不同NLP问题中的注意力机制。
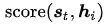 。再来看看几个代表性的work。
。再来看看几个代表性的work。
Citation[5]等人提出Content-base attention,其对齐函数模型设计为:
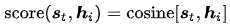
Bahdanau[3]等人的Additive(*),其设计为:
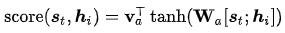
Luong[4]等人文献包含了几种方式:
以及Luong[4]等人还尝试过location-based function:
这种方法的对齐分数仅从目标隐藏状态学习得到。
Vaswani[6]等人的Scaled Dot-Product(^):
细心的童鞋可能早就发现了这东东和点积注意力很像,只是加了个scale factor。当输入较大时,softmax函数可能具有极小的梯度,难以有效学习,所以作者加入比例因子
。
Cheng[7]等人的Self-Attention(&)可以关联相同输入序列的不同位置。 从理论上讲,Self-Attention可以采用上面的任何 score functions。在一些文章中也称为“intra-attention” 。
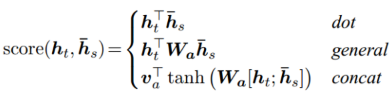
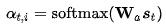
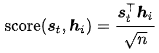
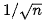 。
。Hu[7]对此分了个类:

Hierarchical Attention
再来看看Hierarchical Attention,Yang[9]等人提出了Hierarchical Attention Networks,看下面的图可能会更直观:
Hierarchical Attention Networks
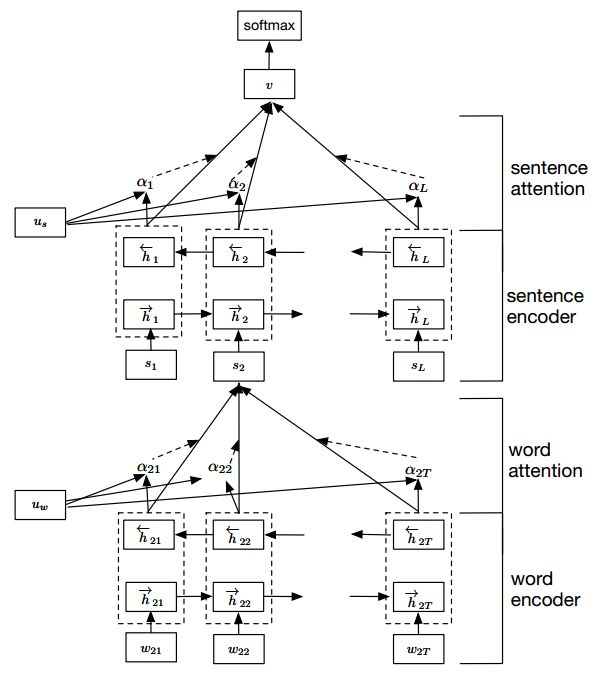
这种结构能够反映文档的层次结构。模型在单词和句子级别分别设计了两个不同级别的注意力机制,这样做能够在构建文档表示时区别地对待这些内容。Hierarchical attention可以相应地构建分层注意力,自下而上(即,词级到句子级)或自上而下(词级到字符级),以提取全局和本地的重要信息。自下而上的方法上面刚谈完。那么自上而下又是如何做的呢?让我们看看Ji[10]等人的模型:
Nested Attention Hybrid Model
和机器翻译类似,作者依旧采用encoder-decoder架构,然后用word-level attention对全局语法和流畅性纠错,设计character-level attention对本地拼写错误纠正。
Self-Attention
Self-Attention(自注意力),也称为intra-attention(内部注意力),是关联单个序列的不同位置的注意力机制,以便计算序列的交互表示。它已被证明在很多领域十分有效比如机器阅读,文本摘要或图像描述生成。
比如Cheng[11]等人在机器阅读里面利用了自注意力。当前单词为红色,蓝色阴影的大小表示激活程度,自注意力机制使得能够学习当前单词和句子前一部分词之间的相关性。

当前单词为红色,蓝色阴影的大小表示激活程度
比如Xu[12]等人利用自注意力在图像描述生成任务。注意力权重的可视化清楚地表明了模型关注的图像的哪些区域以便输出某个单词。

我们假设序列元素为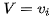
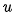
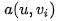
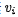
我们根据文章[7]中的例子来看看这个过程,例如句子:"Volleyball match is in progress between ladies"。句子中其它单词都依赖着"match",理想情况下,我们希望使用自注意力来自动捕获这种内在依赖。换句话说,自注意力可以解释为,每个单词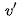
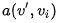
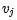
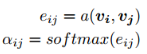
另一方面,自注意力还可以自适应方式学习复杂的上下文单词表示。譬如经典文章[14]:A structured self-attentive sentence embedding。这篇文章提出了一种通过引入自关注力机制来提取可解释句子嵌入的新模型。 使用二维矩阵而不是向量来代表嵌入,矩阵的每一行都在句子的不同部分,想深入了解的可以去看看这篇文章,另外,文章的公式感觉真的很漂亮。
这篇文章为提出许多改进,在完全抛弃了RNN的情况下进行seq2seq建模。接下来一起来详细看看吧。
Key, Value and Query
众所周知,在NLP任务中,通常的处理方法是先分词,然后每个词转化为对应的词向量。接着一般最常见的有二类操作,第一类是接RNN(变体LSTM、GRU、SRU等),但是这一类方法没有摆脱时序这个局限,也就是说无法并行,也导致了在大数据集上的速度效率问题。第二类是接CNN,CNN方便并行,而且容易捕捉到一些全局的结构信息。很长一段时间都是以上二种的抉择以及改造,直到谷歌提供了第三类思路:纯靠注意力,也就是现在要讲的这个东东。
将输入序列编码表示视为一组键值对(K,V)以及查询 Q,因为文章[6]取K=V=Q,所以也自然称为Self Attention。
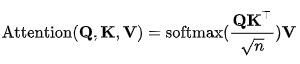
K, V像是key-value的关系从而是一一对应的,那么上式的意思就是通过Q中每个元素query,与K中各个元素求内积然后softmax的方式,来得到Q中元素与V中元素的相似度,然后加权求和,得到一个新的向量。其中因子为了使得内积不至于太大。以上公式在文中也称为点积注意力(scaled dot-product attention):输出是值的加权和,其中分配给每个值的权重由查询的点积与所有键确定。
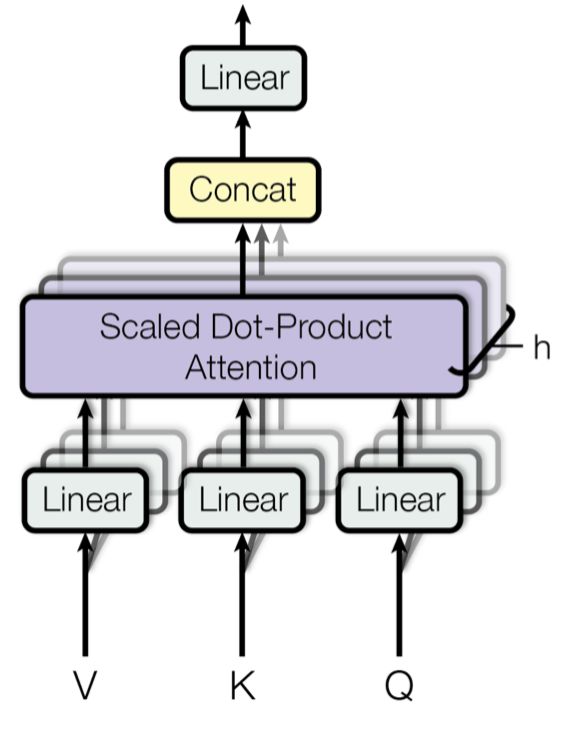
Multi-head scaled dot-product attention mechanism
Multi-Head Self-Attention不是仅仅计算一次注意力,而是多次并行地通过缩放的点积注意力。 独立的注意力输出被简单地连接并线性地转换成预期的维度。论文[6]表示,多头注意力允许模型共同关注来自不同位置的不同表示子空间的信息。 只有一个注意力的头,平均值就会抑制这一点。


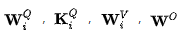 是需要学习的参数矩阵。
既然为seq2seq模式,自然也包括encoder和decoder,那这篇文章又是如何构建这些的呢?莫急,请继续往下看。
是需要学习的参数矩阵。
既然为seq2seq模式,自然也包括encoder和decoder,那这篇文章又是如何构建这些的呢?莫急,请继续往下看。
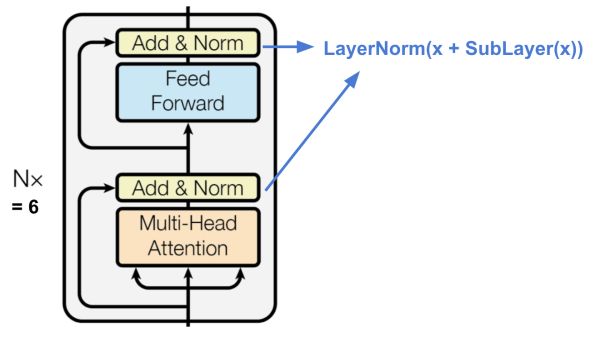
Encoder
The transformer's encoder
每层都有一个多头自注意力层
每层都有一个简单的全连接的前馈网络
每个子层采用残差连接和层规范化。 所有子层输出相同维度dmodel = 512。
Decoder
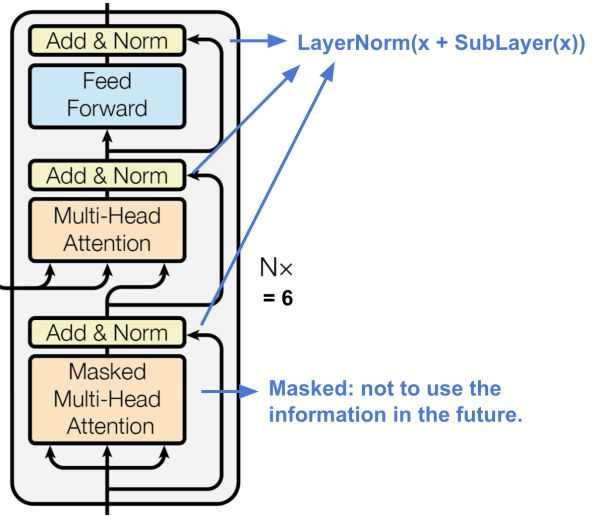
The transformer's decoder.
每层有两个多头注意机制子层。
每层有一个完全连接的前馈网络子层。
与编码器类似,每个子层采用残差连接和层规范化。
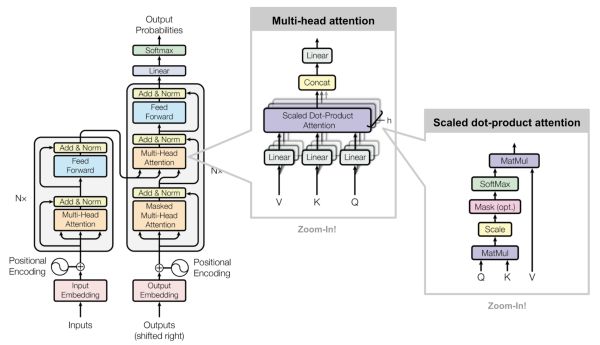
The full model architecture of the transformer.
Memory-based Attention
那Memory-based Attention又是什么呢?我们先换种方式来看前面的注意力,假设有一系列的键值对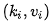
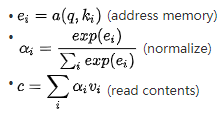
这种解释是把注意力作为使用查询q的寻址过程,这个过程基于注意力分数从memory中读取内容。聪明的童鞋肯定已经发现了,如果我们假设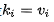
那为什么又要这样做呢?在nlp的一些任务上比如问答匹配任务,答案往往与问题间接相关,因此基本的注意力技术就显得很无力了。那处理这一任务该如何做才好呢?这个时候就体现了Memory-based attention mechanism的强大了,譬如Sukhbaatar[19]等人通过迭代内存更新(也称为多跳)来模拟时间推理过程,以逐步引导注意到答案的正确位置:

在每次迭代中,使用新内容更新查询,并且使用更新的查询来检索相关内容。一种简单的更新方法为相加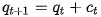
当然有,直觉敏感的童鞋肯定想到了,光是这一点,就可以根据特定任务去设计,比如Kuma[13]等人的工作。这种方式的灵活度也体现在key和value可以自由的被设计,比如我们可以自由地将先验知识结合到key和value嵌入中,以允许它们分别更好地捕获相关信息。看到这里是不是觉得文章灌水其实也不是什么难事了。
Soft/Hard Attention
最后想再谈谈Soft/Hard Attention,是因为在很多地方都看到了这个名词。
据我所知,这个概念由《Show, Attend and Tell: Neural Image Caption Generation with Visual Attention》提出,这是对attention另一种分类。SoftAttention本质上和Bahdanau等人[3]很相似,其权重取值在0到1之间,而Hard Attention取值为0或者1。
Global/Local Attention
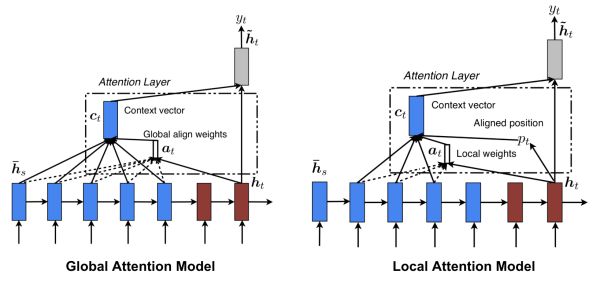
Luong等人[4]提出了Global Attention和Local Attention。Global Attention本质上和Bahdanau等人[3]很相似。Global方法顾名思义就是会关注源句子序列的所有词,具体地说,在计算语义向量时,会考虑编码器所有的隐藏状态。而在Local Attention中,计算语义向量时只关注每个目标词的一部分编码器隐藏状态。由于Global方法必须计算源句子序列所有隐藏状态,当句子长度过长会使得计算代价昂贵并使得翻译变得不太实际,比如在翻译段落和文档的时候。
评价指标

写在后面

本文参考了众多文献,对近些年的自然语言中的注意力机制从起源、变体到评价方面都进行了简要介绍,但是要明白的是,实际上注意力机制在nlp上的研究特别多,为此,我仅仅对18、19年的文献进行了简单的调研(AAAI、IJCAI、ACL、EMNLP、NAACL等顶会),就至少有一百篇之多,足见attention还是很潮的,所以我也把链接放到了我的github上。方便查阅。以后慢慢补充~~
地址:
https://github.com/yuquanle/Attention-Mechanisms-paper/blob/master/Attention-mechanisms-paper.md
随便贴个图:
如果没有梯子或者嫌下载麻烦又需要论文集的童鞋,可以关注我的公众号:AI小白入门,后台回复“Attention”获取资源,以下是部分截图~~

参考文献

长按二维码关注~
AI小白入门
ID: StudyForAI
学习AI学习ai(爱)
期待与您的相遇~