元宇宙知识 | 如何在元宇宙中应用众多GAN模型???

生成对抗网络(GANs)是一种机器学习方法,被用于许多重要和新颖的应用。例如,在成像科学中,通用图像被有效地用于生成图像数据集、人脸照片、图像和视频字幕、图像到图像转换、文本到图像转换、视频预测和3D对象生成等。在本文中,作者讨论了如何利用GAN来创建一个人工世界。更具体地说,讨论GANs如何利用图像/视频字幕方法来帮助描述图像,以及如何在想要的主题中使用图像到图像的转换框架来将图像转换为新的图像。作者阐明了GANs如何影响创建一个定制的世界。
11、简介
许多深度学习框架和架构被研究人员用于不同的应用程序。近年来,在各种计算机视觉任务中取得了一系列的突破性的成果。深度学习对图像处理产生了令人印象深刻的影响。
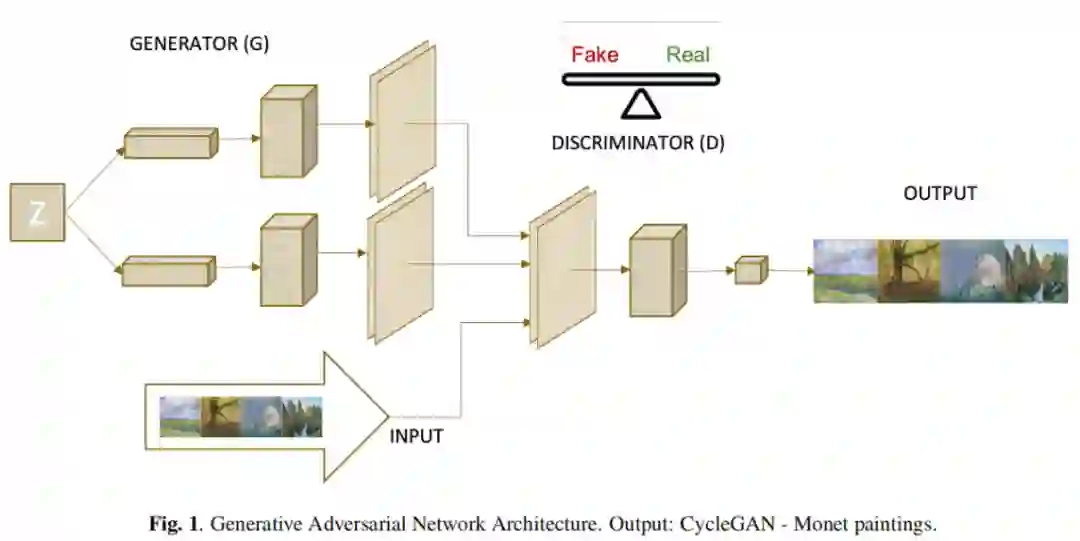
生成式对抗网络是一种机器学习模型。这是由Goodfellow等人在2014年首次提出的,用于通过对抗过程估计生成模型。他们同时训练两种模型:生成模型和判别模型。生成模型 捕获数据分布。而判别模型D估计样本来自于训练数据而不是 的概率(见图1)。大多数生成模型都是通过调整参数来训练的,以最大限度地提高生成器网生成训练数据集的概率。判别器只是一个普通的神经网络分类器。生成器从先验分布 中获取随机噪声值 ,并通过函数 将其映射到输出值 。图1说明了这一解释。
GANs可以生成新的样本。大多数针对GANs的应用都是针对图像的,而GANs的输出都是虚构的。它们更适用于许多不同的图像问题。它们可以解决更复杂的任务,并使它们更健壮。图像字幕是生成输入图像/图像的简洁描述的过程。许多有影响的研究已经对图像字幕和视频字幕进行了研究。GAN架构有助于生成更准确、多样化和连贯的多句子图像/视频描述。一项在人工智能中发展机会平等和公平的研究提出了一种新的方法,通过惩罚回归标记无印象生成的合成未标记图像,以帮助标记新数据(虚构输出图像)。他们使用GAN架构生成了虚构的输出图像。
在这项研究中,介绍了最近的GAN技术,它们可以影响地创建一个定制的世界。本研究的主要贡献是生成对抗网络在图像处理中的应用在人工智能(AI)领域非常有用。有了GAN架构描述,讨论之前在这一领域的工作。然后,来谈谈最近适用于图像的GAN框架。还说明了GAN的不同应用程序,它如何描述图像,以及它如何转换它们。最后,概述了GAN的应用程序和优势,以及它们对人工智能世界的影响。
22、讨论
在本节中,将通过实验来演示GAN的用例。阐明了GAN如何帮助生成图像。讨论了生成对抗网络模型及其应用。解释了不同的GAN模型应用于图像字幕和视频字幕。然后,在图像到图像的转换中说明GAN模型。
2.1、GAN在生成图像中的应用
由于GAN优异的性能,尤其是在图像生成方面的表现,该算法已被广泛应用于许多领域。Toutiaee等人在对生成式对抗网络生成的图像进行无刻板印象标记的研究时,主要关注生成式对抗网络,原因有2:
-
首先,它能够产生虚构的输出(想象的图像) -
其次,它激励了一大批科学家在通过优化GAN以生成更真实的数据
他们使用广泛使用的数据集,如CelebA,许多GAN从业者使用它来创建具有40个面部属性的超自然想象图片。实验了由最先进的GAN生成的超高质量的虚构的人类图像(比如Style-GAN)。Style-GAN的研究人员试图通过在对抗训练中提出一种替代的生成器架构来提高输出图像的质量。

图2显示了由StyleGAN所做的一个实验,以说明它如何通过给人的图像来帮助创建不同的字符。作者使用FacePlace数据集来训练模型。图中显示的结果显示,制作的人脸对观众来说看起来非常自然。

Chong等人还利用Style-GAN提出了JoJoGAN。JoJoGAN是一个任意一次性面孔风格化的框架。只要有一个参考风格的图像,一个熟练的艺术家可以复制新的艺术品风格。通过近似一个成对的训练数据集来训练JoJoGAN。然后,调整了一个风格引擎来执行一次性的面部风格化。图3显示了由JoJoGAN做的一个实验,它展示它如何通过提供一个人的图像来帮助创建不同的角色。
2.2、GAN在图像字幕和视频字幕中的应用
Dai等人提出的条件生成对抗网络(CGAN)。这个框架联合学习一个生成器来生成以图像为条件的描述,以及一个评估器来评估描述与视觉一致性的匹配程度。也有学者探索了一种生成句子的方法,它具有3个属性:语义上的保真度、自然性和多样性。本文为GAN方法提出了一个不同的任务。将GANs应用于文本生成并非很简单。由于语言表征的特殊性,它带来了2个重大的挑战:
-
首先,很难直接应用通过策略梯度设计的反向传播
-
其次,在传统的GAN设置中,由于判别器的反馈,生成器训练中的梯度消失和误差传播,通过蒙特卡罗推出获得近似的预期未来奖励的早期反馈。
这个框架不仅产生了一个可以生成产生自然和多样的表达式的生成器,而且还产生了一个称为G-GAN的描述评估器,它与人类评估更加一致。该方法首次将GAN方法应用于图像字幕。
Nezami等人提出了ATTEND-GAN模型。通过使用设计的基于注意力的字幕生成器和SentiCap数据集上的对抗训练机制,在两阶段架构中生成类人风格的字幕。该模型的结构是由ResNet-152网络生成的空间视觉特征,标题识别器的灵感来自Wasserstein GAN (WGAN)。

Arjovsky等人声称Wasserstein生成式对抗网络最小化了地球移动者距离的合理和有效的近似。此外,Wasserstein GAN能够在不发生模态崩溃的情况下学习分布。使用WGAN算法有显著的实际好处:一个有意义的损失度量,与生成器的收敛性和样本质量相关;改善了优化过程的稳定性。
Makhzani等人提出了对抗自编码器(Adversarial Autoencoder, AAE),它是一种概率自编码器,使用生成式对抗网络,通过将自动编码器的隐藏码向量的聚集后验与任意先验分布进行匹配,从而产生有意义的样本,从而进行变分推理。
通过将GAN注入到深度学习中,Sung Park等人通过设计一个鉴别器来评估视频的视觉相关性、语言多样性、流畅性和句子的连贯性,将对抗网络应用到他们的框架中。因此,GAN有助于生成更准确、更多样化、更连贯的多句视频描述。判别器(D)的任务是为用生成器(G)为给定视频生成的字幕打分。他们建议由三个独立的判别器组成D,每一个都专注于上述任务之一。他们将这种设计表示为混合判别器。
2.3、GAN在图像到图像转换中的应用
Isola等人的想法是将图像相互转换。例如,通过一个蒙面图像,他们的方法将其转换为真实图像,反之亦然。其中一个应用可能是获取卫星图像并将其转换为谷歌地图。他们还表明,这种方法在从标签地图合成照片、从边缘地图重建对象和给图像上色等任务中是有效的。
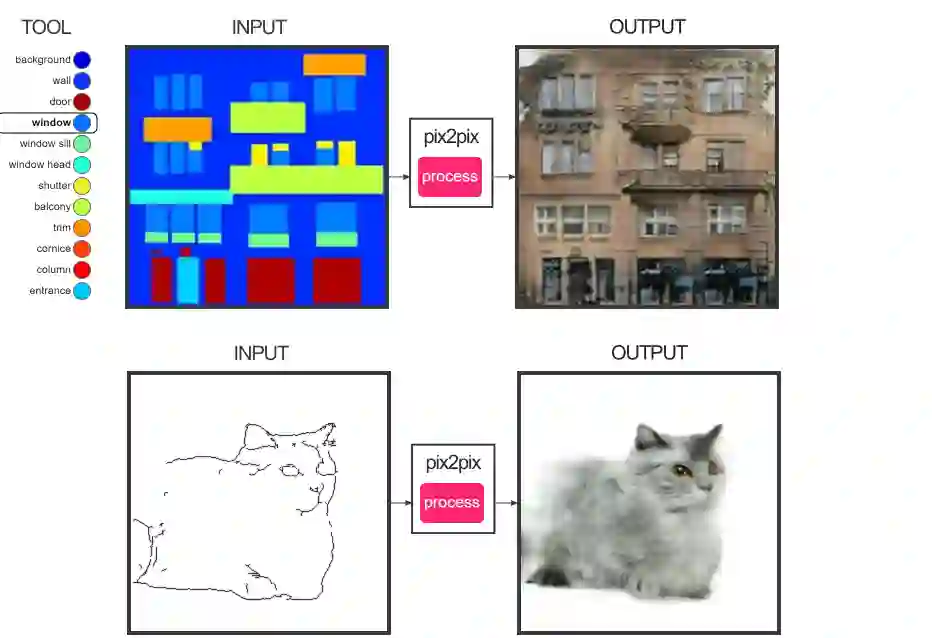
他们使用条件对抗网络解决Pix2Pix图像到图像的转换问题。首先,使用卷积神经网络来最小化预测像素和真实像素之间的欧几里德距离,但它往往会产生模糊的结果,因为通过平均所有可信的输出来最小化欧几里德距离。为了获得良好的输出,比如让输出与现实难以区分,然后自动学习适合满足这一目标的损失函数。
使用条件对抗网络来解决图像到图像的转换问题,因为条件GAN会学习到一种损失,试图对输出的图像进行分类,如果是真实的或假的,同时训练生成模型来最小化这种损失。他们工作的新颖之处在于将PatchGAN设计成一个判别器架构。该判别器试图对图像中的每NxN个patch进行分类。这是有利的,因为较小的PatchGAN参数更少,运行速度更快,并且可以应用于任意大的图像。

CycleGAN是一种使用生成对抗网络(GAN)模型架构来训练图像到图像转换模型的方法。Zhu等人引入了使用循环一致对抗网络的非成对图像到图像的翻译。它们代表了一种学习在没有成对示例的情况下将图像从源域转换到目标域的方法。一个示例应用程序可以使用一个著名艺术家的绘画集合,学习将用户的照片呈现为他们的风格。它们利用了转换应该是循环一致的属性,这意味着如果有从X到Y和从Y到X的转换,那么它们应该是彼此的逆,并且两个映射都应该是双射。
他们使用周期一致性损失作为一种使用传递性来正则化结构化数据的方法。与他们之前的工作相比,在成对数据上训练的pix2pix显示了在不使用成对数据的情况下,他们可以如何接近上界。CycleGAN方法有令人印象深刻的应用。CycleGAN可以将莫奈、梵高、塞尚和浮世绘的艺术风格转化为风景照片。它将对象从一类(如狗)转换为另一类(如猫),或将冬季景观转换为夏季景观。它将莫奈的许多画作翻译成可信的照片。此外,它在某种程度上改善了原始图像。
33、总结
生成式对抗网络由于其令人印象深刻的性能而被广泛应用于许多领域,尤其是在图像生成范式上。GANs可以想象出新的样本。因此,可以通过将它们应用于一系列的应用程序,从而从中获得许多好处。这些应用程序可以包括创建虚构的人物、设计对象、装饰新的环境、季节翻译、对象变形、风格转换,以及从绘画中生成照片。
本研究的主要目的是说明GAN如何在想要创造的超宇宙中的虚拟现实和增强现实中发挥帮助。作者提出了一些实验。通过训练更多的GANs,可以获得更多的好处,并将它们应用到不同的方面。例如,可以通过使用图像和视频字幕技术来描述环境来利用它们来治疗有视觉障碍的人。
44、参考
[1].Generative Adversarial Network Applications in Creating a Meta-Universe
专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复“MUGAN” 就可以获取《元宇宙知识 | 如何在元宇宙中应用众多GAN模型》专知下载链接





