用扩散模型生成高保真度图像


发布人:Google Research Brain 团队研究员 Jonathan Ho 和软件工程师 Chitwan Saharia
自然图像合成是范围很广的一类机器学习 (ML) 任务,会面临各种类型的应用所带来的许多设计挑战。其中之一就是图像超分辨率,即训练一个模型来将低分辨率的图像,转换为细节丰富的高分辨率图像(例如 RAISR)。超分辨率的应用有很多,从恢复古旧的家族画像,到改善医疗成像系统 (Super-resolution imaging),均有涉猎。另一个类似的图像合成任务是类条件下的图像生成,即训练一个模型,并根据输入的类别标签生成样本图像。最终生成的样本图像可用于提高图像分类、分割等下游模型的性能。例如,GAN 经常受到不稳定的训练和模式崩溃的影响,而自回归模型通常受到合成速度慢的影响。
RAISR
https://ai.googleblog.com/2016/11/enhance-raisr-sharp-images-with-machine.html
一般来说,这些图像合成任务由深度生成模型完成,如 GAN、VAE,以及自回归模型。然而,通过训练让这些模型在困难的高分辨率数据集上,合成高质量的样本时,它们的表现均有不足。例如,GAN 经常受到不稳定的训练和模式崩溃的影响,而自回归模型通常受到合成速度慢的影响。
GAN
https://arxiv.org/abs/1406.2661
VAE
https://arxiv.org/abs/1312.6114
自回归模型
https://arxiv.org/abs/1601.06759
但是,2015 年首次提出的扩散模型 (Diffusion Model) 由于其训练的稳定性及在图像和音频生成方面的样本质量结果很有潜力,最近又重新引起了关注。因此,与其他类型的深度生成模型相比,此模型在得失方面有了不错的权衡。扩散模型的工作原理是通过逐步添加高斯噪声来破坏训练数据,慢慢抹去数据中的细节,直到变成纯噪声。然后再训练一个神经网络来逆转这个破坏过程。运行这个反向破坏过程,可以通过逐渐去噪,来从纯噪声中合成数据,直到产生一个干净的样本。这个合成过程可以被解释为一种优化算法,会按照数据密度的梯度来产生可能的样本。
扩散模型
https://arxiv.org/abs/1503.03585
可以被解释为
https://arxiv.org/abs/2006.11239
按照数据密度的梯度
https://arxiv.org/abs/1907.05600
今天,我们会介绍两种相互联系的方法。它们将推动扩散模型的图像合成质量界限,即通过重复优化获得的超级分辨率 (SR3) 和用于类条件合成的模型,此模型又名为级联扩散模型 (CDM)。经证明,通过扩大扩散模型的规模以及精心选择的数据增强技术,我们可以取得比现有方法更出色的结果。具体来说,SR3 可以实现强大的图像超分辨率结果,在人工评估方面的表现优于 GAN。CDM 生成的高保真 ImageNet 样本在 FID 得分 (Fréchet inception distance) 和分类准确率得分上都大大超过了 BigGAN-deep 和 VQ-VAE2。
分类准确率得分
https://arxiv.org/abs/1905.10887
BigGAN-deep
https://arxiv.org/abs/1809.11096
VQ-VAE2
https://arxiv.org/abs/1906.00446

SR3 是一个超分辨率扩散模型,它通过输入低分辨率图像,从纯噪声中构建相应的高分辨率图像。该模型利用图像破坏过程为训练对象,在这个过程中,噪声被逐步添加到高分辨率图像中,直到只剩下纯噪声为止。然后,它将逆转这一过程,从纯噪声开始,逐步去除噪声,再通过指导输入的低分辨率图像,达到目标分布。
SR3
http://iterative-refinement.github.io
通过大规模的训练,在扩缩到所输入低分辨率图像的 4-8 倍时,SR3 在人脸和自然图像的超分辨率任务中取得了强大的基准结果。这些超分辨率模型可以进一步级联起来,增加有效的超分辨率缩放系数,例如,通过将 64x64→256x256 和 256x256→1024x1024 的人脸超分辨率模型堆叠在一起,来执行 64x64→1024x1024 的超分辨率任务。
以人工评估研究为例,我们比较了 SR3 与现有方法。通过开展双选项必选实验 (Two-alternative forced choice),我们要求受访者在引用的高分辨率图像和模型输出之间做出选择,并回答问题(猜一猜哪张图像是摄像机拍摄的?)。我们通过混淆率(评分者选择模型输出而不是参考图像的次数百分比,一个完美的算法能够达到 50% 的混淆率)来衡量模型的性能。这项研究的结果如下图所示。
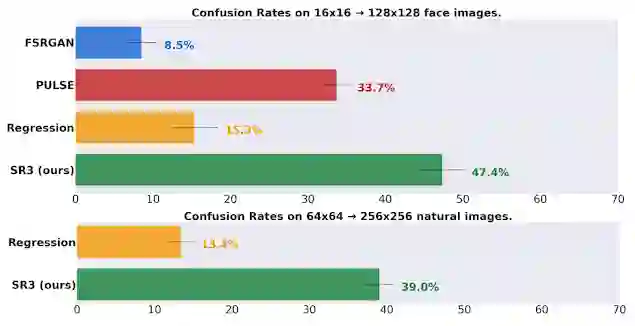
上:我们在 16x16→128x128 的人脸任务中实现了接近 50% 的混淆率,优于一流的人脸超分辨率方法 PULSE 和 FSRGAN。下:在 64x64 → 256x256 的自然图像这个更困难的任务中,我们也达到了 40% 的混淆率,表现水准远超回归基线
PULSE
https://arxiv.org/abs/2003.03808
FSRGAN
https://arxiv.org/abs/1711.10703
在展示了 SR3 处理自然图像超分辨率方面的有效性之后,我们便更进一步——将这些 SR3 模型用于类条件图像生成。CDM 是利用 ImageNet 数据训练的类条件扩散模型,可以生成高分辨率的自然图像。由于 ImageNet 是一个困难的高熵数据集,我们将 CDM 构建为多个扩散模型的级联。这种级联方法会将多个空间分辨率的生成模型串联起来:一个扩散模型以低分辨率生成数据,搭配一连串的 SR3 超分辨率扩散模型,生成图像的分辨率逐渐提高到最高。众所周知,级联可以改善高分辨率数据的质量和训练速度,这一点在以前的研究(例如自回归模型和 VQ-VAE-2)以及同时进行的扩散模型研究中都有所体现。正如以下定量结果所证明的那样,CDM 进一步突出了级联在扩散模型中对样本质量的有效性和对下游任务(如图像分类)的有用性。

级联流水线的示例,其中包括一系列扩散模型:第一个模型用于生成低分辨率的图像,然后其余的模型负责执行上采样,以最终生成高分辨率的图像。此为用于生成类条件 ImageNet 的流水线,以 32x32 分辨率的类条件扩散模型开始,然后是使用 SR3 的 2 倍和 4 倍的类条件超分辨率

从我们的 256x256 级联类条件 ImageNet 模型中选择的生成图像
同时进行
https://arxiv.org/abs/2102.09672
研究
https://arxiv.org/abs/2105.05233
将 SR3 模型纳入级联流水线的同时,我们还引入了一种新的数据增强技术,称之为 “条件增强”,它可以进一步优化 CDM 的样本质量结果。虽然 CDM 中的超分辨率模型利用数据集中的原始图像训练而成,但在生成过程中,它们需要以超分辨率对低分辨率基础模型生成的图像进行处理,而这些图像与原始图像相比,质量可能不够高。这就导致了超分辨率模型的训练和测试水平不对等。条件增强是指对级联流水线中每个超分辨率模型的低分辨率输入图像进行数据增强。在我们的研究中,这些增强包括高斯噪声和高斯模糊,防止各个超分辨率模型对其低分辨率的条件输入过度拟合,最终让 CDM 得到更好的高分辨率样本质量。
总的来说,CDM 生成的高保真样本在类条件 ImageNet 生成的 FID 得分和分类准确率得分方面都优于 BigGAN-deep 和 VQ-VAE-2。不同于 ADM 和 VQ-VAE-2 等其他模型,CDM 是一个纯粹的生成模型,不会使用分类器来提高样本质量。有关样本质量的定量结果如下所示。
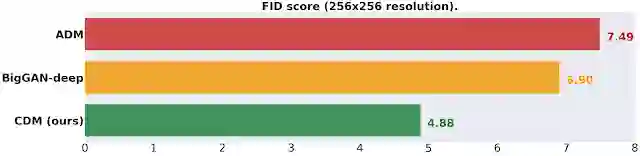
就不使用额外分类器来提高样本质量的方法而言,类条件 ImageNet FID 在 256x256 分辨率下的得分。BigGAN-deep 的分数记录自其在最佳截断值时的表现(数值越低越好)
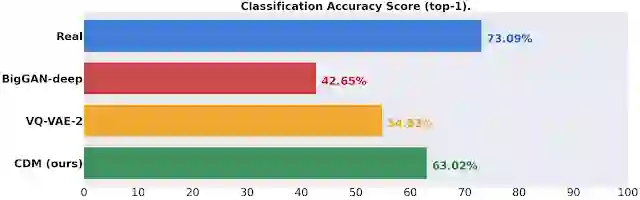
ImageNet 分类准确率在 256x256 分辨率下的得分,用以衡量利用生成数据训练的分类器的验证集准确率。与现有的方法相比,使用 CDM 生成的数据取得了明显的进步,缩小了真实数据和生成数据之间的分类准确率的差距(数值越高越好)
在 SR3 和 CDM 的助力下,我们已经将扩散模型的性能提升到了超分辨率和类条件 ImageNet 生成基准的一流水平。我们很高兴能进一步探索扩散模型在各种生成性建模问题上的极限。有关我们研究的更多信息,请参阅通过迭代优化实现图像超分辨和用于生成高保真图像的级联扩散模型。
通过迭代优化实现图像超分辨
http://iterative-refinement.github.io
用于生成高保真图像的级联扩散模型
http://cascaded-diffusion.github.io
感谢联合作者 William Chan、Mohammad Norouzi、Tim Salimans 和 David Fleet,还要感谢 Ben Poole、Jascha Sohl-Dickstein、Doug Eck 以及 Google Research Brain 团队其他成员参与研究讨论并提供协助。感谢 Tom Small 帮助我们制作动画。

点击“阅读原文”访问 TensorFlow 官网

不要忘记“一键三连”哦~

分享

点赞

在看


