随着AlphaGo的突破,深度强化学习成为解决顺序决策问题的公认技术。尽管深度强化学习有着良好的声誉,但由于其试错学习机制导致的数据效率低下,使得深度强化学习很难在广泛的领域应用。样本高效深度强化学习的方法有环境建模、经验转移和分布式修改等,其中分布式深度强化学习在人机博弈、智能交通等领域显示出了巨大的应用潜力**

本文通过比较经典的分布式深度强化学习方法,研究实现高效分布式学习的重要组成部分,总结了这一激动人心的研究领域的现状,从单一玩家单一智能体分布式深度强化学习到最复杂的多玩家多智能体分布式深度强化学习。此外,我们回顾了最近发布的有助于实现分布式深度强化学习的工具箱,而无需对其非分布式版本进行大量修改。在分析其优缺点的基础上,开发并发布了多玩家多智能体分布式深度强化学习工具箱,并在复杂游戏环境Wargame上进行了进一步验证,显示了该工具箱在复杂游戏环境下多玩家多智能体分布式深度强化学习的可用性。最后,我们试图指出分布式深度强化学习的挑战和未来的发展趋势,希望通过本文的简要回顾可以为那些对分布式深度强化学习感兴趣的研究者提供指导或启发。
1.概述
随着智能体AlphaGo[1],[2]的突破,在人机博弈中赢得了众多专业围棋棋手的胜利,深度强化学习(DRL)开始受到大多数研究人员的关注,成为一种公认的解决顺序决策问题的技术。许多算法都是为了解决DRL与现实世界应用之间的挑战性问题,如勘探和开发困境、数据效率低下、多智能体合作和竞争。在所有这些挑战中,由于DRL的试错学习机制需要大量的交互数据,数据效率低下是最受批评的。
为了缓解数据效率低下的问题,提出了几个研究方向。例如,基于模型的深度强化学习构建环境模型,生成假想轨迹,以帮助减少与环境的交互时间。迁移强化学习从源任务中挖掘共享的技能、角色或模式,然后使用学到的知识来加速目标任务中的强化学习。受分布式机器学习技术(已成功应用于计算机视觉和自然语言处理[4])的启发,开发了分布式深度强化学习(DDRL),该技术已显示出训练非常成功的智能体的潜力,如Suphx [5], OpenAI Five[6]和AlphaStar[7]。
通常,训练深度强化学习智能体由两个主要部分组成,即: 通过与环境交互拉动策略网络参数生成数据,通过消费数据更新策略网络参数。这种结构化模式使得分布式修改DRL成为可能,并且开发了大量的DDRL算法。例如,通用的强化学习体系结构[8]可能是第一个DDRL体系结构,它将训练系统分为四个部分,即参数服务器、学习者、参与者和重放缓冲区,这激发了后续的数据效率更高的DDRL体系结构。最近提出的SEED RL[9]是IMPALA[10]的改进版本,据称能够每秒产生和消耗数百万帧,基于此,AlphaStar在44天内(192 v3 + 12 128个核心tpu, 1800个cpu)成功训练,击败了专业人类玩家。
为了使DRL的分布式修改能够使用多台机器,需要解决机器通信和分布式存储等几个工程问题。幸运的是,已经开发并发布了几个有用的工具箱,将DRL的代码修改为分布式版本通常需要少量的代码修改,这在很大程度上促进了DDRL的发展。例如Uber发布的Horovod[11],充分利用了ring allreduce技术,相对于单一GPU版本,只需要增加几行代码就可以很好地使用多个GPU进行训练加速。Ray[12]是UC Berkeley RISELab发布的一个分布式机器学习框架,它为高效的DDRL提供了一个RLlib[13],由于它的强化学习抽象和算法库,使用起来很方便。
鉴于DDRL研究取得的巨大进展,梳理DDRL技术的发展历程、面临的挑战和机遇,为今后的研究提供线索是十分必要的。最近,Samsami和Alimadad[14]对DDRL进行了简要的回顾,但他们的目标是单玩家单智能体分布式强化学习框架,而缺乏更具挑战性的多智能体多玩家DDRL。捷克[15]对强化学习的分布式方法进行了简要的综述,但只对几种具体算法进行了分类,没有讨论关键技术、比较和挑战。与以往的总结不同,本文通过比较经典的分布式深度强化学习方法,研究实现高效分布式学习的重要组成部分,进行了更全面的考察,从单一参与者单一智能体分布式深度强化学习到最复杂的多参与者多智能体分布式深度强化学习。
本文的其余部分组织如下。在第二节中,我们简要介绍了DRL的背景、分布式学习和典型的DDRL测试平台。在第3节中,我们详细阐述了DDRL的分类。在第4节中,我们将比较当前的DDRL工具箱,这些工具箱在很大程度上帮助实现了高效的DDRL。在第5节中,我们介绍了一个新的多玩家多智能体DDRL工具箱,它为复杂游戏提供了一个有用的DDRL工具。在第6部分,我们总结了DDRL的主要挑战和机遇,希望能启发未来的研究。最后,我们在第7节对本文进行了总结。
2. 背景知识
强化学习是一种典型的机器学习范式,其本质是通过交互进行学习。在一般的强化学习方法中,智能体通过采取行动来驱动环境的动态,并接受奖励来改进其追逐长期结果的策略,从而与环境进行交互。为了学习一个能够进行顺序决策的智能体,有两种典型的算法,即学习算法。一种是不使用环境模型的无模型方法,另一种是使用预先给定或学习的环境模型的基于模型的方法。已经提出了大量的算法,读者可以参考[16],[17]获得更全面的回顾。 深度学习的成功离不开庞大的数据和计算能力,这就导致了对能够处理数据密集型和计算密集型计算的分布式学习的巨大需求。由于深度学习算法的结构化计算模式,针对深度学习[20]、[21]的并行性,提出了一些成功的分布式学习方法。早期流行的分布式深度学习框架是由谷歌设计的DistBelief[22],其中提出了参数服务器和A-SGD的概念。谷歌基于DistBelief发布了第二代分布式深度学习框架Tensorflow[23],成为广泛使用的工具。其他典型的分布式深度学习框架,如PyTorch、MXNet和Caffe2也被研究和工业团体开发和使用。
3. 分布式深度强化学习的分类法
目前已有大量的DDRL算法或框架,其代表有GORILA[8]、A3C[32]、APEX[33]、IMPALA[10]、Distributed PPO[34]、R2D2[35]、Seed RL[9]等,我们可以根据这些算法或框架绘制出DDRL的关键组成部分,如图1所示。我们有时使用框架而不是算法或方法,因为这些框架不针对特定的强化学习算法,它们更像是各种强化学习方法的分布式框架。一般来说,一个基本的DDRL算法主要由三个部分组成,构成了一个单玩家单agent的DDRL方法:
行动者 Actor:通过与环境的交互产生数据(轨迹或梯度)。 * 学习者Learner: 使用数据(轨迹或梯度)执行神经网络参数更新。 * 协调器 Coordinators: 协调数据(参数或轨迹),以控制学习者和行动者之间的交流。
行动者从学习者中提取神经网络参数,从环境中接收状态,并执行推理以获得动作,这些动作将环境的动态驱动到下一个状态。通过对多个参与者重复上述过程,可以提高数据吞吐量,并收集足够的数据。学习者从行动者那里提取数据,进行梯度计算或后处理,并更新网络参数。多个学习器可以通过使用多个GPU和诸如ring allreduce或参数服务器[11]等工具来缓解GPU的有限存储。通过重复上述过程,可以得到最终的强化学习智能体。
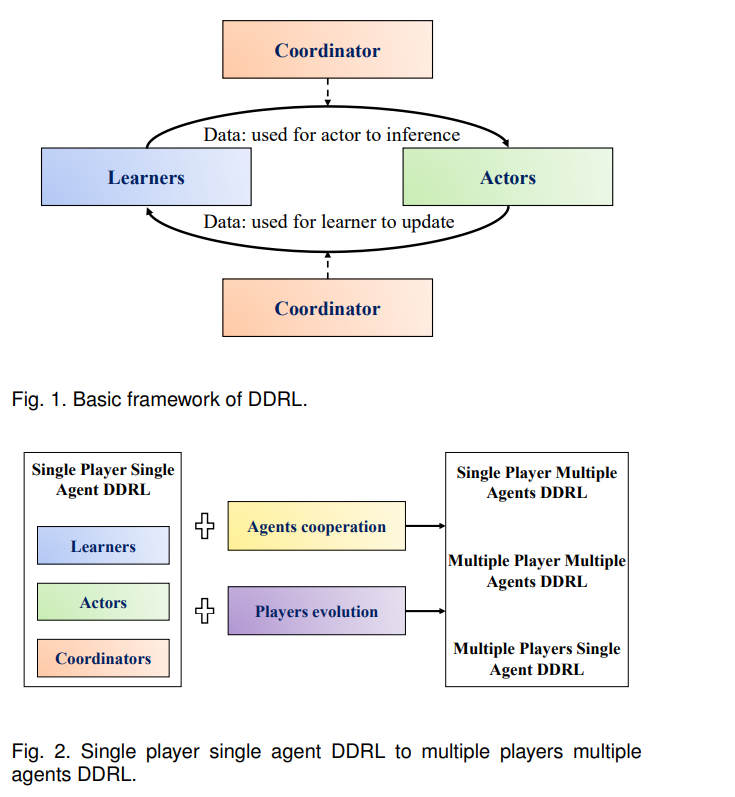
协调器是DDRL算法的重要组成部分,它控制着学习者和行动者之间的通信。例如,当使用协调器同步参数更新和提取(由参与者)时,DDRL算法是同步的。当参数的更新和提取(参与者)不严格协调时,DDRL算法是异步的。因此,DDRL算法的基本分类可以基于协调器的类型。
- 同步:全局策略参数的更新是同步的,策略参数的提取(行动者)是同步的,即不同的行动者共享最新的全局策略。
- 异步:全局策略参数的更新是异步的,或者说策略更新(由学习者进行)和策略拉取(由行动者进行)是异步的,即行动者和学习者通常具有不同的策略参数。
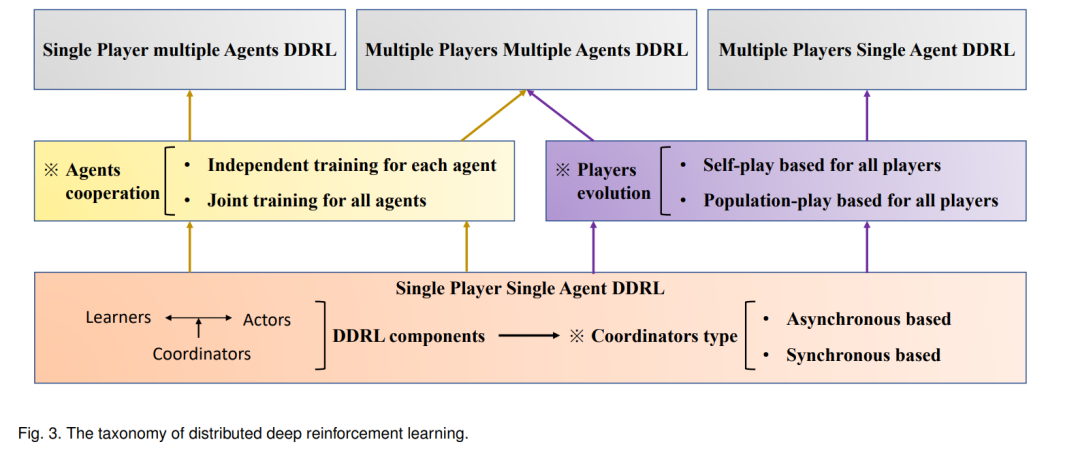
利用上述基本框架,可以设计出一个单玩家单agent的DDRL算法。然而,当面对多个智能体或多个参与者时,基本框架无法训练可用的强化学习智能体。基于目前支持AlphaStar[7]、OpenAI Five[6]和JueWU[36]等大型系统级AI的DDRL算法,构建多玩家和多agent DDRL需要两个关键组件,即agent合作和玩家进化,如图2所示:
基于多智能体增强学习算法[18],采用智能体协作模块对多智能体进行训练。通常,多智能体强化学习可以根据如何进行智能体关系建模分为独立训练和联合训练两大类。
独立训练:通过将其他学习智能体视为环境的一部分,独立地训练每个智能体。
联合训练:将所有智能体作为一个整体进行训练,考虑智能体通信、奖励分配和分布式执行的集中训练等因素。
玩家模块进化是为每个玩家的智能体迭代而设计的,其中其他玩家的智能体同时学习,从而为每个玩家学习多代智能体,如AlphaStar和OpenAI Five。根据目前主流的玩家进化技术,玩家进化可以分为两种类型:
- 基于自玩:不同的玩家共享相同的策略网络,玩家通过面对过去的版本来更新当前生成的策略。
- 基于群体的游戏:不同的玩家有不同的策略网络,或称为群体,玩家通过对抗其他玩家或/及其过去的版本来更新当前世代的策略。
最后,基于上述DDRL的关键组件,DDRL的分类如图3所示。下面,我们将根据代表性方法的主要特点,对其进行总结和比较。