在过去的几年中,强化学习(RL)与深度学习的结合取得了快速的进展。从游戏到机器人的各种突破都激发了人们对设计复杂的RL算法和系统的兴趣。然而,RL中普遍采用的工作流程是学习tabula rasa,这可能导致计算效率低下。这就妨碍了RL算法的持续部署,并可能排除没有大规模计算资源的研究人员。在机器学习的许多其他领域,预训练范式已被证明在获取可迁移知识方面是有效的,可用于各种下游任务。最近,我们看到了对深度RL预训练的兴趣激增,结果很有希望。然而,许多研究都是基于不同的实验设置。由于强化学习的性质,该领域的预训练面临着独特的挑战,因此需要新的设计原则。本文系统地回顾了深度强化学习预训练方面的现有工作,对这些方法进行了分类,讨论了每个子领域,并对开放问题和未来方向提出了关注。
https://www.zhuanzhi.ai/paper/aad5ecc8e9b3ee704395b5de4af297d2
1. 概述
强化学习(RL)为顺序决策提供了一种通用的数学形式主义(Sutton & Barto, 2018)。通过利用RL算法和深度神经网络,不同领域的各种里程碑通过数据驱动的方式优化用户指定的奖励函数实现了超人的性能(Silver et al., 2016; Akkaya et al., 2019; Vinyals et al., 2019; Ye et al., 2020, 2020, 2022; Chen et al., 2021b)。正因为如此,我们最近看到了对这一研究方向越来越多的兴趣。
然而,尽管RL已被证明在解决指定良好的任务时是有效的,但样本效率(Jin et al.,2021)和泛化(Kirk et al.,2021)的问题仍然阻碍了它在现实世界问题中的应用。在强化学习研究中,一个标准的范式是让智能体从自己或他人收集的经验中学习,通常是在单个任务上,并通过随机初始化tabula - rasa优化神经网络。相比之下,对人类来说,关于世界的先验知识对决策过程有很大帮助。如果任务与之前看到的任务相关,那么人类倾向于重用已经学习到的东西来快速适应新任务,而不需要从头开始从详尽的交互中学习。因此,与人类相比,RL智能体通常存在数据效率低下的问题(Kapturowski et al.,2022),并且容易出现过拟合(Zhang et al.,2018)。
然而,其他机器学习领域的最新进展积极倡导利用从大规模预训练中构建的先验知识。大型通用模型,也被称为基础模型(Bommasani et al., 2021),通过在大范围数据上进行训练,可以快速适应各种下游任务。这种训练前-微调范式已被证明在计算机视觉等领域有效(Chen et al., 2020; He et al., 2020; Grill et al., 2020)和自然语言处理(Devlin et al., 2019; Brown et al., 2020)。然而,预训练还没有对RL领域产生显著影响。尽管如此,大规模RL前训练的设计原则面临着来自多方面的挑战: 1) 领域和任务的多样性; 2)数据来源有限; 3) 快速适应解决下游任务的难度大。这些因素源于RL的性质,不可避免地需要加以考虑。
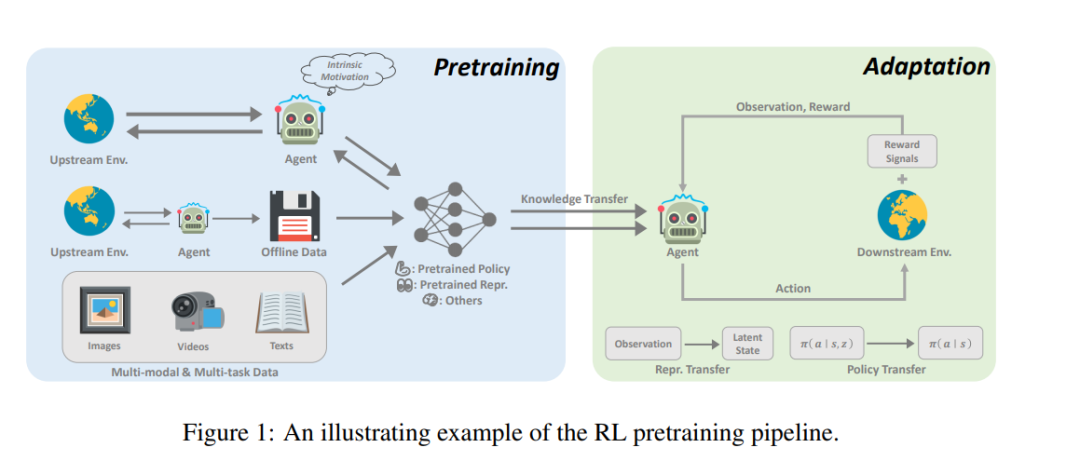
本研究旨在对当前深度强化学习预训练的研究现状进行概览。在RL中有原则的预训练有多种潜在的好处。首先,RL训练产生的大量计算成本仍然是工业应用的障碍。例如,复现AlphaStar的结果(Vinyals等人,2019年)大约需要数百万美元(Agarwal等人,2022年)。预训练可以通过预训练的世界模型(Sekar et al., 2020)或预训练的表示(Schwarzer et al., 2021b)来改善这一问题,通过支持快速适应以零次或少次的方式解决任务。此外,众所周知,RL是特定于任务和领域的。已有研究表明,使用大量任务无关数据进行预训练可以增强这些类型的泛化(Lee et al.,2022)。最后,我们相信用适当的架构进行预训练可以释放扩展定律的力量(Kaplan等人,2020年),正如最近在游戏中的成功所显示的那样(Schwarzer et al., 2021b; Lee et al., 2022)。通过增加计算量,扩大通用模型的规模,我们能够进一步取得超人的结果,正如“痛苦的教训”(Sutton, 2019)所教导的那样。
近年来,深度RL的预训练取得了一些突破。在著名的AlphaGo中,通过专家演示,使用监督学习来预测专家采取的行动,进行了朴素的预训练(Silver et al., 2016)。为了在较少的监督下进行大规模的预训练,无监督强化学习领域近年来发展迅速(Burda等人,2019a;Laskin等人,2021),使智能体能够在没有奖励信号的情况下从与环境的交互中学习。根据离线RL的最新进展(Levine等人,2020年),研究人员进一步考虑如何利用未标记和次优离线数据进行预训练(Stooke等人,2021年;Schwarzer等人,2021b),我们称之为离线预训练。与任务无关的数据的离线范式进一步为通用预训练铺平了道路,其中来自不同任务和模式的不同数据集以及具有良好扩展特性的通用模型被组合起来构建通用模型(Reed et al., 2022; Lee et al., 2022)。预训练有可能在强化学习中发挥重要作用,这项综述可以作为对该方向感兴趣的人的起点。在这篇论文中,我们试图提供一个系统的回顾,现有的工作在深度强化学习的预训练。据我们所知,这是系统研究深度RL预训练的先驱努力之一。
本文根据RL预训练的发展趋势,对本文进行了如下组织。在学习了强化学习和预训练(第2节)的初步内容之后,我们从在线预训练开始,在在线预训练中,智能体通过与没有奖励信号的环境的交互进行学习(第3节)。然后,我们考虑离线预训练,即使用任何策略收集一次无标记训练数据的场景(第4节)。在第5节中,我们讨论了针对各种正交任务开发通才智能体的最新进展。我们进一步讨论了如何适应下游RL任务(第6节)。最后,我们总结了本次综述和一些展望(第7节)。
2. 在线预训练
在RL之前的大多数成功都是基于密集且设计良好的奖励功能。尽管传统的RL范式在为特定任务提供优异表现方面发挥着首要作用,但在将其扩展到大规模的预训练时,它面临着两个关键的挑战。首先,众所周知,RL智能体很容易过拟合(Zhang et al., 2018)。因此,用复杂的任务奖励训练的预训练智能体很难泛化到未见过的任务规范。此外,设计奖励函数仍然是一个实际的挑战,这通常是昂贵的和需要专业知识。
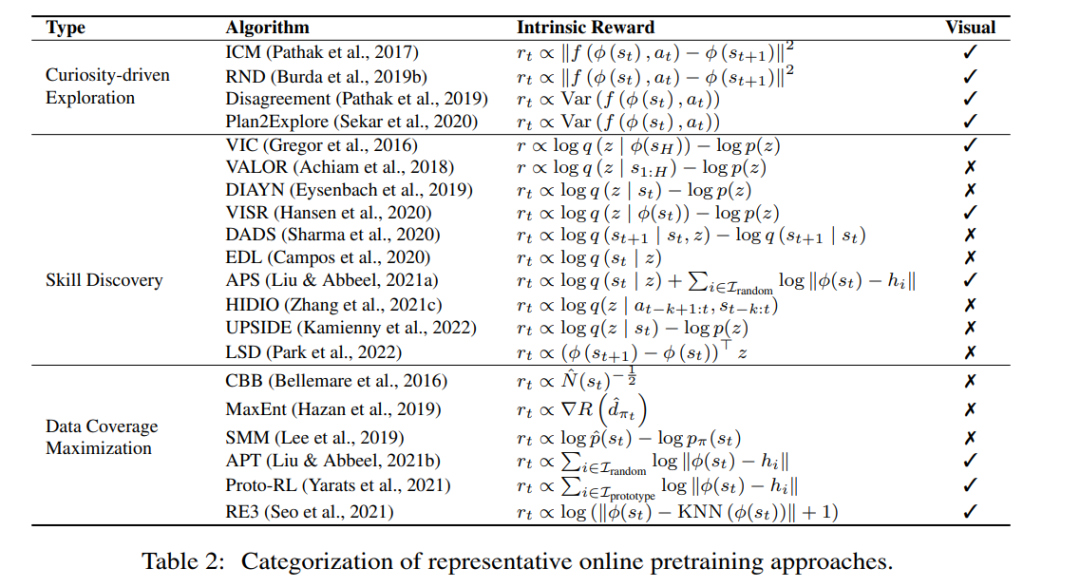
没有这些奖励信号的在线预训练可能是学习通用技能的一个很好的解决方案,并消除了监督要求。在线预训练的目的是在没有人为监督的情况下,通过与环境的交互获得先验知识。在预训练阶段,允许代理与环境进行长时间的交互,而不获得外部奖励。当环境是可访问的,使用它可以促进技能学习,当任务被分配给智能体时,这些技能将非常有用。这种解决方案,也被称为无监督RL,近年来得到了积极的研究(Burda等人,2019a;Srinivas & Abbeel, 2021年)。
为了鼓励智能体在没有任何监督的情况下建立自己的知识,我们需要有原则的机制为智能体提供内在动力。心理学家发现,婴儿可以通过与环境的互动发现需要学习的任务以及这些任务的解决方案(Smith & Gasser, 2005)。随着经验的积累,他们能够在以后完成更困难的任务。这激发了大量研究,研究如何建立具有内在奖励的自学智能体(Schmidhuber, 1991;Singh等人,2004;Oudeyer等人,2007)。内在奖励,与指定任务的外在奖励相比,是指鼓励智能体收集多样化经验或开发有用技能的一般学习信号。研究表明,一旦给出下游任务,用内在奖励和标准强化学习算法对智能体进行预训练,可以导致快速适应(Laskin等人,2021)。
3. 离线预训练
尽管在线预训练在没有人工监督的情况下具有很好的学习效果,但在大规模应用中仍有局限性。最终,很难将在线交互与在大型和多样化的数据集上进行训练的需求协调起来(Levine, 2021)。为了解决这个问题,人们希望将数据收集和预训练解耦,并直接利用从其他智能体或人类收集的历史数据。一个可行的解决方案是离线强化学习(Lange et al., 2012;Levine et al., 2020),最近受到了关注。离线RL的目的是单纯从离线数据中获得一个最大化的策略。离线RL的一个基本挑战是分布转移,它指的是训练数据和测试中看到的数据之间的分布差异。现有的离线RL方法主要关注如何在使用函数逼近时解决这一挑战。例如,策略约束方法(Kumar等人,2019年;Siegel等人,2020)明确要求学习策略避免在数据集中采取看不见的操作。值正则化方法(Kumar et al., 2020)通过将值函数拟合到某些形式的下界,缓解了值函数的过高估计问题。然而,离线训练的策略是否可以泛化到离线数据集中看不到的新上下文仍有待深入研究(Kirk等人,2021年)。