PlaNet 简介:用于强化学习的深度规划网络
文 / Danijar Hafner,Google AI 学生研究员
在强化学习 (RL) 的推动下,有关人工智能体如何逐渐改进自身决策的研究正取得迅猛进展。对于此项技术,智能体会在选择动作(如运动命令)的过程中观察一系列感官输入信息(如相片),有时还会因完成指定目标而受到奖励。这种无模型的 RL 方法旨在直接从感官观察中预测良好动作,使 DeepMind 的 DQN 能够玩 Atari 游戏,并能让其他智能体来操控机器人。然而,这种黑箱法往往需要数周的模拟交互,才能通过反复试验进行学习,由此限制了其在实践中的应用。
相比之下,基于模型的 RL 试图让智能体学习世界的普遍运行规律。这种方法并非将观察结果直接转化为动作,而是让智能体提前作出明确规划,进而通过 “想象” 长期回报来更谨慎地选择动作。这种基于模型的强化学习方法已取得了实质性成功,例如 AlphaGo 便是根据已知的游戏规则,在虚拟棋盘上想象采取一系列动作。然而,为了在未知环境中利用规划(如在仅给定像素作为输入的情况下控制机器人),智能体必须从经验中学习规则或动态变化情况。由于这种动态模型原则上可实现更高效率,并可进行自然的多任务学习,因此创建足够精确的模型以成功进行规划便成为 RL 的长期目标。
为早日攻克这项研究挑战,我们联合 DeepMind 推出深度规划网络 (PlaNet) 智能体,该智能体仅凭图像输入即可学习世界模型,并能成功利用此模型进行规划。PlaNet 能够解决基于图像的各类控制任务,最终性能可媲美先进的无模型智能体,但其平均数据效率却是后者的 50 倍。此外,我们还将发布 源代码,以供研究社区构建上述模型。
注:源代码 链接
https://github.com/google-research/planet
经 2000 次尝试后,PlaNet 智能体从输入图像中学会解决各种连续控制任务。先前不学习环境模型的智能体往往需要进行 50 倍的尝试才能达到与之媲美的性能
PlaNet 的工作原理
简言之,PlaNet 是在给定图像输入的前提下学习动态模型,并通过该模型进行高效规划,从而累积新的经验。相较于过去基于图像进行规划的方法,我们依靠的是一个紧凑的隐藏或潜在状态序列。我们将其称为潜在动态模型,原因是该模型并非直接从一张图像预测到下一张图像,而是预测未来的潜在状态。之后,模型会从相应的潜在状态中生成每一步的图像与奖励。通过以这种方式压缩图像,智能体能够自动学习更多抽象表征(如物体的位置和速度),无需全程生成图像便可更轻松地预测未来的状态。
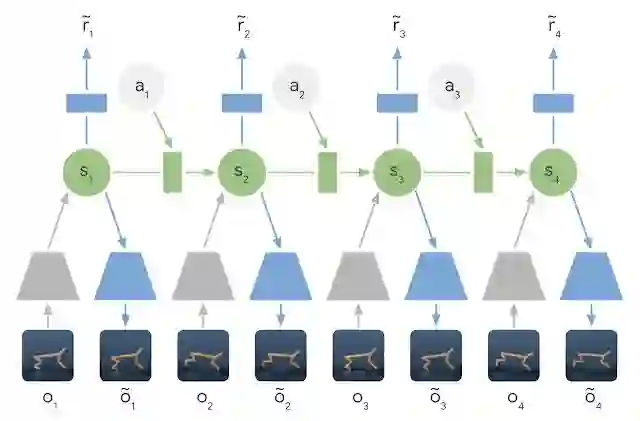
习得的潜在动态模型:在潜在动态模型中,模型会利用编码器网络(灰色梯形)将输入图像的信息集成到隐藏状态(绿色部分)中。然后将隐藏状态向前投射,以预测后续图像(蓝色梯形)和奖励(蓝色矩形)
为学习准确的潜在动态模型,我们引入了:
循环状态空间模型:这是一个兼具确定与随机成分的潜在动态模型,可预测实现鲁棒规划所需的各种未来可能状态,同时还能记住多个时间步上的信息。实验表明,如要取得出色的规划性能,这两种成分缺一不可
潜在的超调目标:我们通过保持潜在空间中一步与多步预测之间的一致性,归纳出潜在动态模型的标准训练目标,以此来训练多步预测。这便产生了一个快速有效的目标,其不仅有助于改善长期预测,还可与任何潜在序列模型兼容
虽然预测未来图像允许我们教模型学习,但编码和解码图像(上图中的梯形)需要大量计算,会拖慢规划速度。但是,我们能在紧凑的潜在状态空间中作出迅速规划,因为我们只需预测未来的奖励(而非图像)即可评估动作序列。例如,智能体能够在不看到实际场景的情况下,想象出球的位置及其与目标的距离会随某些动作如何变化。由此,我们便可在智能体每次选择动作时,将 10000 个想象的动作序列与大批量进行比较。然后,我们会找到最优序列,执行其首个动作,并在下一步重新规划。
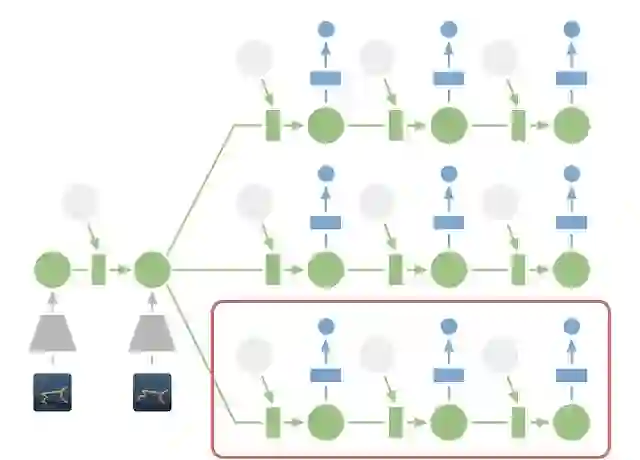
潜在空间中的规划:规划时,我们将过去的图像(灰色梯形)编码为当前的隐藏状态(绿色部分)。据此,我们便可高效预测多个动作序列未来会带来的奖励。请注意对比前文示图,了解代价高昂的图像解码器(蓝色梯形)是如何消失的。然后,我们会找到最优序列,并执行其首个动作(红色框)
相较于先前对世界模型的研究,PlaNet 无需策略网络即可运作,因为它完全通过规划来选择动作,因而可立即从模型改进中受益。如需了解技术详情,请查看我们的 在线研究论文 或其 PDF 版本。
注:在线研究论文 链接
https://planetrl.github.io/
PDF 链接
https://danijar.com/publications/2019-planet.pdf
PlaNet 与无模型方法对比
我们通过连续控制任务对 PlaNet 进行评估。评估时,我们仅为智能体提供图像观察结果和奖励。此类任务包含以下几种不同挑战:
cartpole 上翻任务:该任务使用固定的摄像头,故 cart 可能会超出视野范围。因此,智能体必须吸收并记住多个帧上的信息
手指旋转任务:需对两个不同的物体以及二者之间的互动作出预测
猎豹式奔跑任务:包括与地面接触(很难进行准确预测),需利用模型预测多个可能的未来状态
杯子任务:仅在智能体接到球时为其提供稀疏奖励信号。这就要求智能体准确预测未来状态,以便规划精确的动作序列
步行者任务:此任务中,模拟机器人起初躺在地上,其必须先学会站立,然后再开始行走

PlaNet 智能体在各类基于图像的控制任务中进行训练。该动图展示了智能体在解决任务时的输入图像。这些任务包含几项不同挑战:仅可观察部分内容、与地面接触、因接到球获得稀疏奖励,以及控制颇难操纵的两足机器人
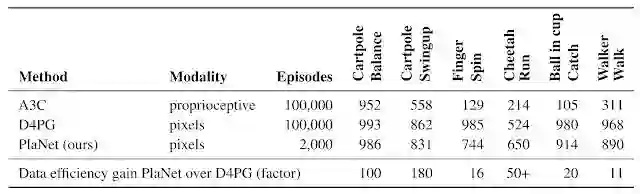
此外,我们的研究还率先证明,在完成基于图像的任务时,利用习得模型进行规划的方法要优于无模型的规划方法。下表将 PlaNet 与著名的 A3C 智能体及 D4PG 智能体(二者均结合了无模型 RL 的最新进展)进行了对比。这些基线数字取自于 DeepMind Control Suite。PlaNet 在各项任务中的表现均明显优于 A3C,最终性能逼近 D4PG,而其与环境的平均交互次数仅相当于后两者的 1/50。
一个智能体,搞定所有任务
此外,我们还训练出一个一体化 PlaNet 智能体,可将以上六项任务全部搞定。我们将该智能体随机放置到不同环境中且不告知其具体任务,因此其需根据图像观察结果自行推断任务内容。无需更改超参数,该多任务智能体便可达到与单个智能体等同的平均性能水平。尽管该智能体在 cartpole 任务中的学习速度较慢,但在需进行探索且难度较高的步行者任务中,其学习速度会得到大幅提升,且最终性能可达到较高水平。

在多个任务中训练的 PlaNet 智能体的视频预测结果。上面一行是利用训练好的智能体收集的留出片段,而下面一行则为开环智能体的幻觉。该智能体以观察到的前 5 帧作为背景,进而推断出任务和状态,并基于动作序列准确预测后续的 50 步动作
结论
研究结果表明,用于构建自主 RL 智能体的学习动态模型大有前景。我们希望日后更多研究能够重点关注在难度更高的任务中学习准确的动态模型,如 3D 环境和现实世界的机器人任务。我们或许还能借助 TPU 的处理能力来扩展这项研究。我们感到无比兴奋的是,基于模型的强化学习方法创造了众多可能性,其中包括多任务学习、分层规划以及根据不确定性估计进行的主动探索等。
致谢
本项目由以下成员合作完成:Timothy Lillicrap、Ian Fischer、Ruben Villegas、Honglak Lee、David Ha 和 James Davidson。此外,我们还要感谢在整个项目期间,对我们的论文草稿发表意见并随时提供反馈的所有人士。
更多 AI 相关阅读:




