「基于课程学习的深度强化学习」研究综述

作为解决序贯决策的机器学习方法,强化学习采用交互试错的方法学习最优策略,能够契合人类的智能决策方 式。基于课程学习的深度强化学习是强化学习领域的一个研究热点,它针对强化学习智能体在面临高维状态空间和动作 空间时学习效率低、难以收敛的问题,通过抽取一个或多个简单源任务训练优化过程中的共性知识,加速或改善复杂目标 任务的学习。论文首先介绍了课程学习的基础知识,从四个角度对深度强化学习中的课程学习最新研究进展进行了综 述,包括基于网络优化的课程学习、基于多智能体合作的课程学习、基于能力评估的课程学习、基于功能函数的课程学习。然后对课程强化学习最新发展情况进行了分析,并对深度强化学习中的课程学习的当前存在问题和解决思路进行了总结 归纳。最后,基于当前课程学习在深度强化学习中的应用,对课程强化学习的发展和研究方向进行了总结。
http://www.xactad.net/oa/darticle.aspx?type=view&id=20221103
1. 引言
强化学习(Reinforcement Learning,RL) 作为机器 学习分支之一,在人工智能领域具有重要地位[1] :智能 体在环境中通过“交互-试错冶获取正/ 负奖励值,调整 自身的动作策略,从而生成总奖励值最大的动作策略 模型[2]。传统强化学习方法在有限状态空间和动作空间的 任务中能够取得较好的收敛效果[3] ,但复杂空间状态 任务往往具有很大的状态空间和连续的动作空间,尤 其当输入数据为图像和声音时,传统强化学习很难处 理,会出现维度爆炸问题[4 -5 ] 。解决上述问题的一个 方法,就是将强化学习和深度神经网络(Deep Neural Network,DNN)结合,用多层神经网络来显式表示强 化学习中的值函数和策略函数[6] 。
深度 强 化 学 习 ( Deep Reinforcement Learning, DRL)将深度学习的感知能力和强化学习的决策能力 相结合[7],近年来在人工智能领域迅猛发展,例如 Atari 游戏[8 -9 ] 、复杂机器人动作控制[10 -11 ] ,以及围棋 AlphaGo 智能的应用[12]等,2015 年机器学习领域著名 专家 Hinton、Bengio、Lecun 在《Nature》 上发表的深度 学习综述一文将深度强化学习作为深度学习的重要发 展方向[13] 。
尽管在过去三十年间取得很大进步,但由于标准 强化学习智能体的初始设定都是随机策略,在简单环 境中通过随机探索和试错,能够达成较好的训练效 果[14] 。但在复杂环境中由于状态空间的复杂性、奖励 信号的稀疏性,强化学习从环境中获取样本的成本不 断提高,学习时间过长,从而影响了智能体的有效 探索[15]。
解决上述问题的一个有效途径,就是将课程学习 (Curriculum Learning,CL)和深度强化学习相结合[16]。2009 年,以机器学习领军人物 Bengio 为首的科研团队 在国际顶级机器学习会议 ICML 上首次提出课程学习 的概念[17] ,引起机器学习领域的巨大轰动。课程学习 借鉴人类从简单到复杂的学习思想,首先在任务集中 筛选出部分简单任务进行学习以产生训练课程,而后 在剩余的复杂任务中利用训练课程进行学习,最后在 整个训练集中进行训练。将课程学习和深度强化学习 相结合,可以有以下两个方面的作用[18] :(1)可以加快 训练模型的收敛速度,避免训练初期对于复杂任务投 入过多训练时间;(2)提高模型的泛化能力,增强对复 杂任务的学习能力。
该文首先对课程学习进行简要描述,从四个角度 对深度强化学习中的课程学习进行了分类整理,之后 对近三年的基于课程学习的深度强化学习新算法进行 了总结分析,最后讨论了基于课程学习的深度强化学 习的发展前景和挑战。
1 基于课程学习的深度强化学习
课程学习的目标是自动设计和选择完整序列的任 务(即课程) M1 ,M2 ,…,Mt 对智能体进行训练,从而提 高对目标任务的学习速度或性能[19] ,课程学习流程如 图 1 所示。课程 马 尔 可 夫 决 策 过 程 ( Curriculum Markov Decision Process,CMDP) [20] 是一个 6 元组 (S,A,p,r, 驻s0 ,Sf) ,其中 S 是状态空间集, A 是动作空间集, p(s ' | s,a) 代表智能体在状态 s 时采取动作 a 后转移到状 态 s ' 的概率, r(s,a,s ' ) 代表在状态 s 采取动作 a 到达 状态 s ' 所获得的即时奖励, 驻s0 代表初始状态分布, Sf 代表最终状态集。
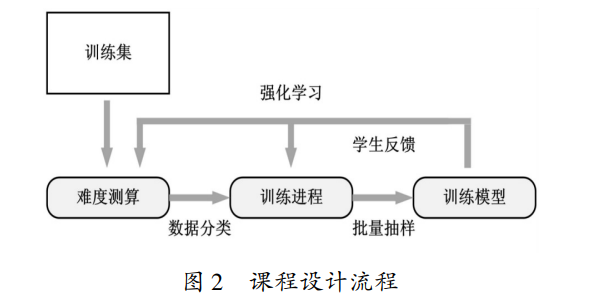
常见的课程创建方法有以下两种[21] :(1)在线创 建课程,根据智能体对给定顶点样本的学习进度动态 添加边;(2)离线创建课程,在训练前生成图,并根据 与不同顶点相关联的样本的属性选择边。课程设计流 程如图 2 所示。
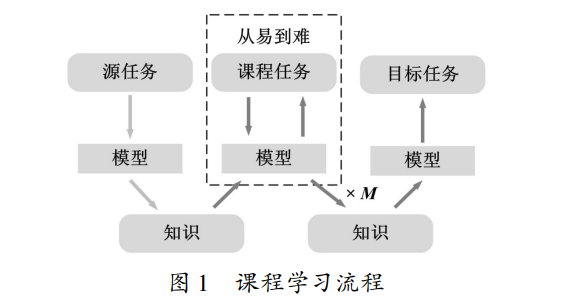
2 深度强化学习中的课程学习研究进展
对于强化学习智能体来说,自主学习一项复杂任 务需要很长的时间。在深度强化学习中应用课程学 习,可以通过利用一个或多个源任务的知识来加速或 改善复杂目标任务的学习[25] 。Felipe 等人提出了新方法[26] :(1) 将目标任务划 分为简单任务;(2)在尽量小的专家经验支持下,根据 面向对象的任务描述自动生成课程;(3) 使用生成的 课程来跨任务重用知识。实验表明在人工指定和生成子任务方面都取得了更好的性能。为了提高多智能体的学习性能,Jayesh 等人应用 前馈神经网络( Feedforward Neural Network,FNN) 完 成协 同 控 制 任 务[27] , 包 括 离 散 和 连 续 动 作 任 务, Daphna 等人提出了推断课程( Inference Curriculum, IC)的方法[28] ,从另一个网络迁移学习的方式,接受不 同任务的训练。为了解决从稀疏和延迟奖励中学习的 局限性问题,Atsushi 提出了一种基于渐进式神经网络 (Progressive Neural Network, PNN ) 的 课 程 学 习 方 法[29] ,带参数的模块被附加上预先确定的参数,该策 略比单组参数的效果更好。
3 算法分析与总结
强化学习是处理序列决策任务的流行范式[46] ,尽 管在过去的三十年中取得了许多进步,但在许多领域 的学习仍然需要与环境进行大量的交互,导致模型的 训练时间过长,收敛速度过慢。为了解决这个问题,课程学习被用于强化学习,这样在一个任务中获得的经 验可以在开始学习下一个更难的任务时加以利用。然 而,尽管课程学习理论、算法和应用研究在国内外已普 遍开展,并且也已经取得了较多的研究成果[47 -48 ] ,但 仍然有许多问题还亟待解决。
3. 1 强化学习中的课程学习算法理论分析与对比
在算法和理论方面,传统课程学习对于小规模的 多智能体强化学习性能提升明显,但在大规模多智能 体环境中,由于环境和智能体之间的复杂动态以及状 态-行动空间的爆炸,因此在实际问题的解决上进展 不大[49] 。得益于深度神经网络的数据处理能力,使用 深度神经网络表示回报函数,避免了特征提取工作,当 前基于课程学习的深度强化学习算法在实验场景中应 用于 StarCraft [50] 、 grid - world [51] 、 hide - and - seek [52] 、 Sokoban [53]等经典强化学习问题的解决。随着课程学 习技术的发展,算法在智能决策[54] 、困难编队下的合 作导航[55] 、在 SUMO 交通模 拟 器 中 协 商 多 车 辆 变 道[56]以及在 Checkers 环境下的战略合作[57] 等领域也 取得了一定的成功。该综述分四个角度对目前强化学习中的课程学习 方法进行分类并介绍,希望能够为相关研究人员提供 一点帮助。为方便了解和对比,该文分析、对比了这几 类方法的优缺点,并归纳在表 1 中。
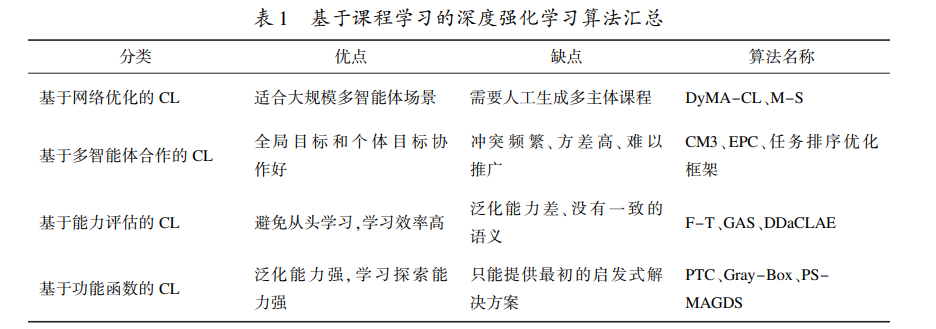
(1)基于网络优化的课程学习。解决大规模问题 的方法是从小型多智能体场景开始学习,逐步增加智 能体的数量,最终学习目标任务。使用多种传输机制 以加速课程学习过程,课程设计是影响课程迁移成绩 的关键因素。如何选择合适的课程(包括如何决定每 个任务的训练步长,如何选择合适的学习模型重新加 载等)是至关重要的。如何自动生成多智能体课程可 能是目前尚存在的主要局限性,这将在今后的工作中 进一步研究[58] 。
(2)基于多智能体合作的课程学习。是根据全局 目标和个体目标之间的关系进行学习探索,使用信度 分配[33] 、种群进化课程[34] 、任务排序框架[36] ,通过函 数增强方案来连接价值和策略函数的阶段,在具有高 维状态空间的多目标多智能体环境中执行高挑战性任 务性能较好,缺点是冲突较为频繁、更高的方差和无法 维持合作解决方案[59] ,目前难以推广到非齐次系统或 没有已知目标分配的设置的工作。
(3)基于能力评估的课程学习。通过限制其最初 行动空间来设置内部课程,使用非策略强化学习同时 估计多个行动空间的最优值函数,建立技能、表述和有 意义的经验数据集,从而避免从头开始学习,加快学习 效率。缺点是集群对每个状态都会改变[60] ,这可能会 干扰泛化,因为没有一致的语义。
(4)基于功能函数的课程学习。 通过设定级数函 数和映射函数来为智能体量身定制在线课程,通过高 斯过程定义智能体函数,学习策略在单位之间共享,以鼓励合作行为。使用神经网络作为函数逼近器来估计 动作-价值函数,并提出一个奖励函数来帮助单位平 衡它们的移动和攻击。缺点是只提供最初的启发式解 决方案[61] ,而且质量不能得到保证。
3. 2 基于课程学习的深度强化学习研究方向
通过对最新课程学习算法理论的研究分析,本节 对当前基于课程学习的深度强化学习存在的开放性问 题和可能的研究方向进行讨论。(1)自动创建任务课程。任务创建是课程学习方法的重要组成部分,任务 质量会影响课程的生成质量,任务数量会影响课程排 序算法的搜索空间和效率。现有课程学习中的任务大 多由人工创建,减少任务创建过程中的人工输入量是 未来工作的重要发展方向[62] 。(2)迁移不同类型知识。课程任务之间,知识必须从一个任务迁移到另一 个任务。目前大部分研究中,知识迁移的类型是固定 的。例 如, Narvekar 等 人 在 任 务 之 间 迁 移 价 值 函 数[63] ,而 Svetlik 等人迁移成型奖励[64] 。这种知识迁 移类型的局限性在于,不同的任务对于知识类型的需 求可能是不同的,因此可以从不同任务中分别提取知 识进行组合。例如,从一个任务中提取一个选项,从另 一个任务中提取模型,从而达成更好的学习效果。(3)课程重用的成本分摊。当前课程学习方法的另一个局限性是,生成课程 的时间可能比直接学习目标任务的时间更长。原因在 于,课程通常是为每个智能体和目标任务独立学习的。因此,分摊成本的一种方法是学习一门课程来训练多 个不同的智能体[65] ,或解决多个不同的目标任务。
4 结束语
该文对基于课程学习的深度强化学习进行了回 顾,由浅入深地对课程学习进行了分析,介绍了课程学 习的概念理论、经典算法、研究进展和发展展望等,从 基于网络优化的课程学习、基于多智能体合作的课程 学习、基于能力评估的课程学习、基于功能函数的课程 学习四个角度对强化学习中的课程学习进行了分类梳 理、对比分析,最后对基于课程学习的深度强化学习的 未来展望进行简要分析。根据当前深度强化学习中存在的状态空间复杂、 维数灾难、学习时间长等问题,课程学习会是未来的一 个发展方向。课程学习算法可以将目标任务分解成多 个子任务,结合大多数的强化学习算法,使用多种传输 机制以加速强化学习进程,大大提高了学习探索效率 和通用性。最后,目前课程算法在大规模多智能体场 景的研究进展缓慢,其主要原因在于多智能体场景的 复杂性。然而大规模多智能体场景更加贴近现实,优 质的课程学习算法能够在很大程度上提高学习探索的 效率。因此,相信课程学习算法会成为深度强化学习 的热门方向,加快深度强化学习的发展速度。
专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复“CBRL” 就可以获取《「基于课程学习的深度强化学习」研究综述》专知下载链接







